
How DoorDash Used LLMs to Trigger 30% More Relevant Results
We evaluate the food delivery company DoorDash on LLM experiments and how they get cleaner segments, smarter retrieval and a system that knows what “no-milk vanilla ice cream” actually means.

Fellow Data Tinkerers!
Today we will look at how Doordash used LLM to show better results to users.
But before that, I wanted to share an example of what you could unlock if you share Data Tinkerer with just 2 other people.

There are 100+ more cheat sheets covering everything from Python, R, SQL, Spark to Power BI, Tableau, Git and many more. So if you know other people who like staying up to date on all things data, please share Data Tinkerer with them!
Now, with that out of the way, Let’s see how Doordash leverages LLM for better search results
TL;DR
Situation
DoorDash users search with ultra-specific, complex queries (e.g. low-carb spicy chicken wrap with gluten-free tortilla), expecting accurate matches. Traditional keyword systems couldn’t handle the nuance and pure LLM-based solutions were prone to hallucination.
Task
Build a scalable, accurate and fast search system that could deeply understand both queries and items without sacrificing relevance or blowing up compute.
Action
DoorDash built a hybrid system using:
LLMs (for query segmentation and classification)
Knowledge graphs (for structured metadata)
Approximate Nearest Neighbor search (for grounding output in known taxonomies)
Added tight guardrails: constrained vocabularies, structured output prompts, and post-processing validation.
Plugged structured query outputs into the search rankers and retrained based on improved engagement data.
Result
~30% increase in trigger rate for “Popular Dishes” carousel
2% lift in whole page relevance (WPR) for intent-heavy queries
+1.6% WPR boost from retrained rankers due to better training signals
Use Cases
Improved search relevance, query processing at scale, ranking and personalisation
Tech Stack/Framework
LLM, knowledge graph, ANN
Explained further
At DoorDash, users don’t just type “burger” and call it a day. They type “low-carb spicy chicken wrap with gluten-free tortilla” and expect relevant suggestions. These aren’t simple lookups, they’re loaded with layered preferences, dietary restrictions and dish expectations.
So how do you build a search system that can handle that level of complexity without cracking under pressure?
The DoorDash team went with a hybrid approach: combine the brute force of traditional keyword systems with the nuance of LLMs and knowledge graphs. It’s like pairing a calculator with a philosophy major. It works and here is how.
What happens behind the search bar
At a high level, DoorDash's search engine processes two kinds of things:
Documents - the restaurants or menu/store items
Queries - what users type in
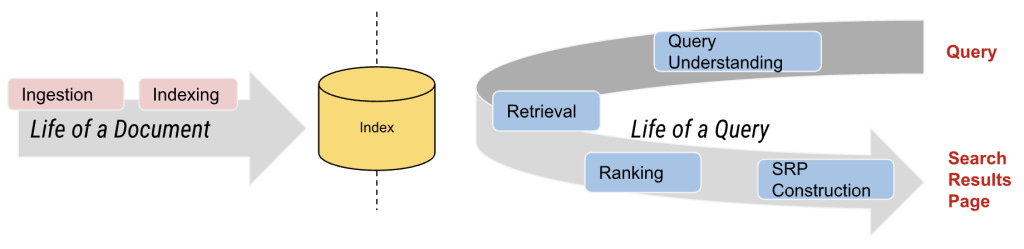
Each goes through its own journey. Queries get parsed, segmented, labeled and spell-checked. Documents get annotated and enriched with metadata, like vegan, spicy or chicken.
But the real power comes from understanding both deeply enough to match the right taco to the right craving.
Two worlds: documents and queries
Documents at DoorDash aren’t just raw strings, they’re enriched with metadata pulled from custom-built knowledge graphs. These graphs define relationships between things like dish type, cuisine, ingredients and dietary preferences.
Take Non-Dairy Milk & Cookies Vanilla Frozen Dessert - 8 oz as an example. It gets tagged with:
Dietary_Preference: "Dairy-Free"
Flavor: "Vanilla"
Product_Category: "Ice Cream"
Quantity: "8 oz"
On the query side, things get chunked up and mapped to similar concepts. So “small no-milk vanilla ice cream” gets split into:
[“small”, “no-milk”, “vanilla ice cream”]
Without this kind of breakdown, the search engine would either over-match (ice cream that isn’t dairy-free) or under-match (only exact string matches). With it, search becomes smarter.
But understanding concepts is only half the battle. How do you break down messy, real-world queries in the first place? That’s where things get messy and where traditional methods start to hit their limits.
Using LLMs without letting them run wild
Traditionally, query segmentation has leaned on methods like pointwise mutual information (which checks how often words co-occur compared to random chance) and n-gram analysis (which looks at fixed word sequences) to figure out which terms belong together. That works fine for clean, simple queries. But once you throw in overlapping entities or any real ambiguity, those old-school tricks start to break down fast.
Take a query like “turkey sandwich with cranberry sauce.” Is the cranberry sauce a separate item or part of the sandwich? Without context, traditional methods have no clue. They just see word chunks, not relationships.
LLMs, however, can understand the context if given the right guardrails. They will usually segment things in a way that actually makes sense, picking up on how words relate to each other across different use cases.
But here’s the catch: LLMs are prone to hallucination. So you couldn’t just throw queries at them and hope for the best. Doordash needed a controlled vocabulary to keep things grounded, something that ensured the segments were not only real but useful for the retrieval system.
Fortunately, they already had a knowledge graph in place with a solid ontology and a bunch of taxonomies to work with. So instead of letting the model come up with its own segmentations, it’s prompted to identify meaningful chunks and tag each one with a specific category from Doordash taxonomy.
For food, They have got taxonomies for cuisine types, dish types, dietary tags and more. For retail, it’s things like brand, dietary preference, product category, etc.
Back to our earlier query: “small no-milk vanilla ice cream.”
If we just asked for segments, we might get:
[“small”, “no-milk”, “vanilla ice cream”]
Not bad, but vague. Instead, the team asks the model to return a structured output mapping that relates to one of the Doordash taxonomy categories:
{
Quantity: "small",
Dietary_Preference: "no-milk",
Flavor: "vanilla",
Product_Category: "ice cream"
}
This setup gives the model extra context to work with and it leads to better results. it doesn’t just segment, it classifies. But classification isn’t the end of the road. Once you’ve got the chunks, you need to actually understand what they mean.
Entity linking: turning words into meaning
Once a query is segmented, the next step is to map each segment to a concept in the knowledge graph. For example, “no-milk” isn’t just a string match. It should link to the “dairy-free” concept even if the item description never says “no-milk” explicitly anywhere.
LLMs are handy here too but just like in segmentation, they can still hallucinate. To avoid that problem, the team constrained the model’s output using only concepts from their controlled vocabularies (i.e., taxonomy terms from the knowledge graph).
The guardrails come from a curated candidate list, pulled using approximate nearest neighbor (ANN) retrieval. ANN is a fast way to find the most similar entries in a big dataset without doing a full exhaustive search. This keeps the LLM grounded by forcing it to choose from concepts that actually exist in the system.
Take the earlier example: the segment “no-milk.” Instead of letting the LLM invent a new category like “milk-averse”, the ANN system first retrieves candidates like “dairy-free” or “vegan.” The model then just has to pick the best match based on context, keeping the output both accurate and mappable.
The method behind this is a classic retrieval-augmented generation (RAG) setup:
For every query and knowledge graph concept (a.k.a. candidate label), embeddings are generated either from closed-source models, pre-trained ones or DoorDash’s own.
Using ANN retrieval, the top 100 closest taxonomy concepts are pulled for each query. This trims the fat from the prompt and avoids blowing up the model’s context window.
The LLM is then prompted to link query segments to taxonomy concepts across domains like dish types, dietary tags, cuisines and more.
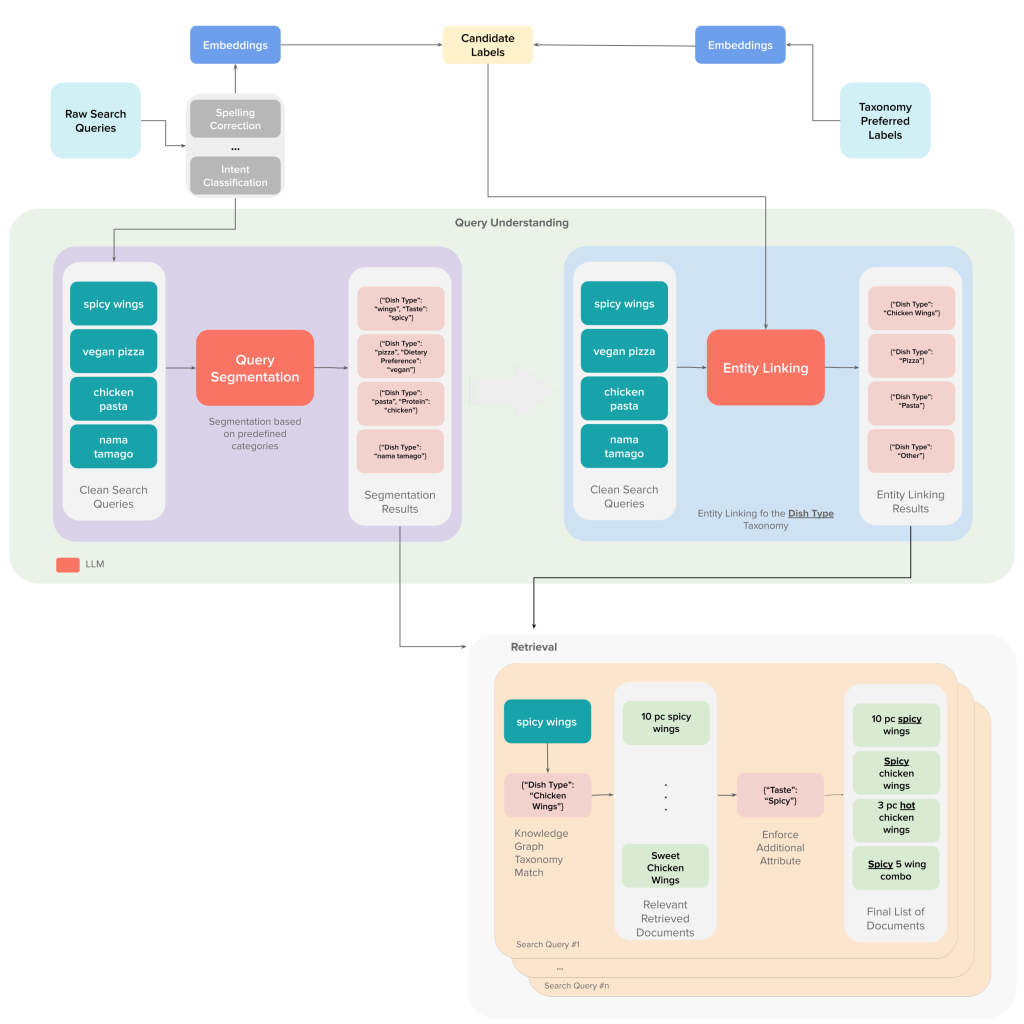
The retrieval payoff
Let’s go back to “small no-milk vanilla ice cream.” After segmentation and entity linking, the final structured output might look like this:
{
Dietary_Preference: "Dairy-Free",
Flavor: "Vanilla",
Product_Category: "Ice Cream"
}
Now retrieval becomes precise, it can make Dietary Preference a MUST condition (non-negotiable) and treat Flavor as a SHOULD (nice to have). It’s like giving the system a conscience, it knows what matters more.
But smart retrieval isn’t enough. You also need to double-check what the model spits out before someone eats the wrong thing.
Evaluations: catching hallucinations before users do
Accuracy is especially critical for filters like dietary restrictions. One mistake and someone could end up eating something they’re allergic to.
To keep hallucinations in check and make sure both segmentation and entity linking are solid, the team added post-processing steps to validate the model’s output. Once that’s done, they run manual audits on every batch of processed queries to spot any issues before they hit production.
Annotators go through a statistically significant sample of results and check two things:
Are the segments correct?
Are they mapped to the right concepts in the knowledge graph?
This manual review helps surface any systematic slip-ups, fine-tune prompts and improve the overall pipeline. Still, even a well-reviewed system comes with trade-offs, especially when scale and change are constants.
Memorisation vs. generalisation: the trade-off
LLMs are a solid tool for query understanding but like most things in ML, there’s a trade-off. In this case, it’s memorisation versus generalisation.
If you run LLMs in batch mode on a fixed set of queries, you’ll usually get high accuracy. That works great when the query space is small and predictable. But the further you drift into the long tail (which, let’s be honest, is where a lot of real-world queries live), things start to get tricky.
Relying purely on memorisation comes with baggage:
Scalability: New queries show up constantly in a system like DoorDash. Preprocessing every single one just isn’t realistic.
Maintenance overhead: Any changes to the knowledge graph or user behavior mean re-running batches, tweaking prompts and revalidating outputs.
Stale features: Segments or links that were fine last month might be outdated now.
That’s where more generalisable approaches shine. Things like embedding-based retrieval, traditional statistical models or even smart rule-based systems can handle new queries on the fly without any preprocessing.
These methods bring a few key advantages:
Scalability: They work on any query, even ones the system hasn’t seen before.
Flexibility: They keep up with evolving language like new dishes, slang, weird typos
Real-time readiness: No batch processing delays; they can act immediately.
The downside? They don’t have the same deep contextual smarts as LLMs. That can hurt precision, especially when subtle relationships between terms matter.
So DoorDash takes a hybrid approach. Instead of picking one side, they combine the strengths of both:
LLMs for deep understanding when you can afford it
Lightweight retrieval methods when you need scale and speed
The result: better precision where it matters and better coverage everywhere else.
But theory only gets you so far. The real test? Whether it plays nicely with the rest of the stack.
Making it all work in production
Of course, even the best query understanding system is only useful if the rest of the stack knows what to do with it. For DoorDash, that means making sure the new signals actually integrate cleanly into the search pipeline, especially with the rankers.
Rankers are the part of the system responsible for taking a big pile of candidate items or stores and deciding what order they should show up in. So once the team introduced these new, structured query signals, the rankers had to be updated to recognise and use them.
As the rankers adjusted to the new inputs and to the new patterns of user behavior that came with better retrieval, the impact showed up fast. Online metrics went up, both on the relevance side and on key business KPIs.
One feature in particular showed just how well things were clicking.
Real world example: açaí bowl, anyone?
One clear beneficiary of DoorDash’s improved query understanding system is the “Popular Dishes” carousel shown below. This component shows users a ranked list of food items when they search with clear dish intent (like “açaí bowl”).
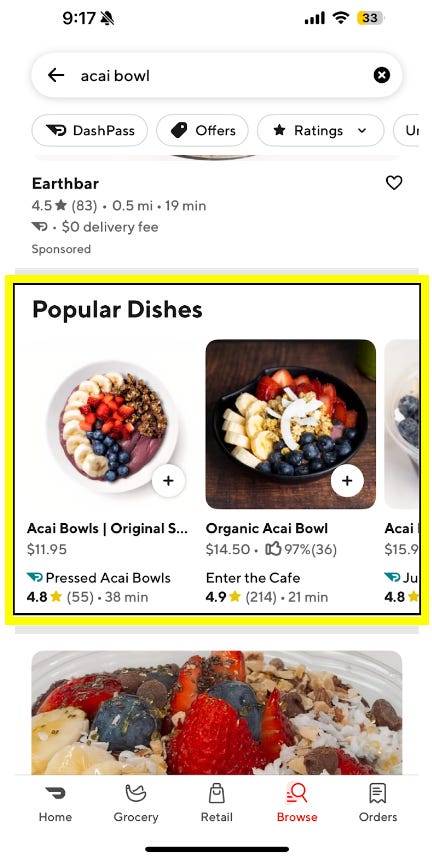
When someone types in “açaí bowl,” they’re not looking to browse menus. They want a specific thing. The carousel lets them quickly scan options across stores, compare prices and pick what looks good. It’s fast, it’s focused and thanks to the new pipeline, it’s pulling in way more relevant results.
After rolling out the updated query understanding and retrieval system, DoorDash saw a ~30% jump in the carousel trigger rate. That means more queries are now returning results that qualify for the Popular Dishes treatment. It’s a strong signal that the system is getting closer to what users actually want.
And it’s not just about quantity, quality improved too. With better segmentation and entity linking, the system can retrieve a broader, more accurate set of items tied to the user’s intent. This showed up in their whole page relevance (WPR) metric, which measures how relevant the entire result page is from the user’s point of view. For dish-intent queries, WPR jumped by over 2%.
And because users were interacting with a wider variety of results, DoorDash was able to retrain its rankers on a more diverse engagement dataset. That led to a newer, smarter ranker version and another 1.6% bump in WPR. And because users interact more with the right stuff, the system gets better training data for the ranker, which then improves things further and becomes a virtuous cycle.
Lessons learned
LLMs are powerful but more so with guardrails. Left to their own devices, they hallucinate. But paired with taxonomies and controlled vocabularies, they become sharp tools for segmentation and classification.
Structured queries unlock smart retrieval. Turning messy user input into clean, labeled chunks (like "Flavor: Vanilla") makes it easier to match intent, not just strings.
Hybrid > pure LLM. DoorDash got the best results by mixing deep LLM understanding with fast, generalizable methods like embedding retrieval.
Better understanding improves ranking. Once structured query signals flowed into rankers, DoorDash saw real-world lifts: 30% more carousel triggers and measurable boosts to conversion and relevance.
The full scoop
To learn more about this, check Doordash's Engineering Blog post on this topic
If you are already subscribed and enjoyed the article, please give it a like and/or share it others, really appreciate it 🙏
Keep learning
How Uber Cut Invoice Handling Time by 70% with GenAI (Without Ditching Humans)

Uber’s invoices were a hot mess. Thousands of formats, 25+ languages and way too much human copy-pasting. Even with automation, it was chaos. Their solution? a GenAI-powered doc processing system that cut invoice handling time by 70% and slashed costs by 30%.
If you want to learn about an actual example of GenAI being used in practice (rather than just vibes), check this article.
How Reddit Scans 1M+ Images a Day to Flag NSFW Content Using Deep Learning

Reddit needed to flag NSFW images the second they were uploaded. They built a deep learning system that does exactly that; fast, scalable and battle-tested in prod. Here’s how it works.