
How Grab Detects Data Issues across 100+ Kafka Topics Before They Spread
Real-time stream validation surfaces poison records early and notifies owners with context

Fellow Data Tinkerers
Today we will look at how Grab detects data issues in real-time.
But before that, I wanted to share with you what you could unlock if you share Data Tinkerer with just 1 more person.
There are 100+ resources to learn all things data (science, engineering, analysis). It includes videos, courses, projects and can be filtered by tech stack (Python, SQL, Spark and etc), skill level (Beginner, Intermediate and so on) provider name or free/paid. So if you know other people who like staying up to date on all things data, please share Data Tinkerer with them!
Now, with that out of the way, let’s get to Grab’s real-time work!

TL;DR
Situation
Grab runs critical systems on Kafka streams, where bad data can spread and break downstream consumers. Existing checks were slow and mostly limited to schemas, making issues hard to catch and debug.
Task
Detect bad streaming data early, cover both schema and value-level issues and give stream owners fast, actionable visibility without centralising ownership.
Action
Grab built contract-driven stream checks on Coban, turning schemas, field rules and ownership into real-time FlinkSQL tests with Slack alerts and UI-based inspection of bad records.
Result
The system now monitors 100+ Kafka topics in real time, surfaces poison data quickly and helps teams stop issues before they cascade downstream.
Use Cases
Root cause analysis, real-time monitoring, real-time alerting
Tech Stack/Framework
Apache Kafka, Apache Flink, Amazon S3, Slack, LLM
Explained further
About Grab
Grab is often called the Uber of Southeast Asia but that might be selling it short. What started as a ride-hailing app now powers food delivery, groceries, payments and even insurance all bundled into one super app. They run across over 800 cities in 8 Southeast Asian countries. Behind the rides, meals, and payments lies an enormous stream of events flowing through Grab’s systems.
Background
Grab runs a lot of business on streaming data. Kafka topics feed online systems, offline analytics and machine learning pipelines. When those streams are clean, life is good: teams can move faster, models behave, dashboards run smoothly. But when they’re not clean, it’s a major headache.
The tricky part is that ‘bad data’ in Kafka isn’t always obvious. Sometimes it’s quiet: the stream still parses but key fields are wrong, missing or shaped differently than what downstream teams assume.
That’s why Grab decided to introduce a platform-level solution: Kafka stream contracts that let stream stakeholders define what ‘good’ looks like, then automatically test streams in real time, catch issues as they happen and alert the owners quickly.
The core idea is simple:
Let users define a data contract for a Kafka topic
Convert that contract into executable tests
Run those tests continuously
Capture the poison data plus context
Notify the right people with enough detail to act
This supports a more decentralized, data-mesh style world where teams own their data products while still keeping the overall system reliable for everyone else.
What wasn’t working before
Historically, monitoring Kafka stream data processing didn’t have a strong, end-to-end solution for data quality validation. That created three big issues: detecting bad data, speed of detection and lack of visibility.
1- Detecting bad data
This can be broken down into two further categories:
1.1 Schema issues
These are schema mismatches between producers and consumers that can trigger deserialization errors. Even if schema backward compatibility is validated during schema evolution, the data inside the Kafka topic can still drift from the defined schema.
One concrete example: a rogue producer writes to a topic without using the expected schema. Now you’ve got a topic that ‘has a schema’ but real events don’t match it. The painful bit is not just knowing something broke, it’s identifying which fields are causing the mismatch.
1.2 Rule and value issues
These are disagreements about what a field means or what shape it should take. Kafka stream schemas define structure but they don’t enforce rules like:
expected length for an identifier
expected string pattern
valid numeric ranges
constant values that should never change
There wasn’t an existing framework where stakeholders could define and enforce field-level semantic rules for streams.
2- Speed of detection
The second issue was speed of detection. There was no real-time mechanism to automatically validate data against predefined rules, identify issues quickly and alert stakeholders promptly.
Without real-time validation, issues could stick around for a while, quietly impacting multiple online and offline downstream systems before being discovered.
3- Lack of visibility
Even when teams did detect a problem, it was hard to pinpoint the exact ‘poison data’ and understand what violated the schema or the semantic expectations.
Root cause analysis becomes painful when you cannot easily answer:
Which records were bad?
Which fields failed?
What did the bad values look like?
When did it start and how frequent is it?
The fix
Grab’s Coban platform provides a standardized, platform-level data quality testing and observability setup for Kafka streams. It’s built around four core ideas:
Data Contract Definition: Stream stakeholders define a contract that includes schema agreements, semantic rules the topic data must follow, and ownership metadata for alerts and notifications.
Automated Test Execution: A long-running test runner automatically executes real-time tests based on that contract.
Real-time Data Quality Issue Identification: The system detects data issues in real time at both schema and rules/values levels.
Alerts and Result Observability: It alerts the right people and makes it easier to observe issues through the platform UI and downstream tooling.
Put simply: define the rules once, then let the platform watch the stream continuously.
The architecture has three main components:
Data contract definition
Test execution and data quality issue identification
Result observability
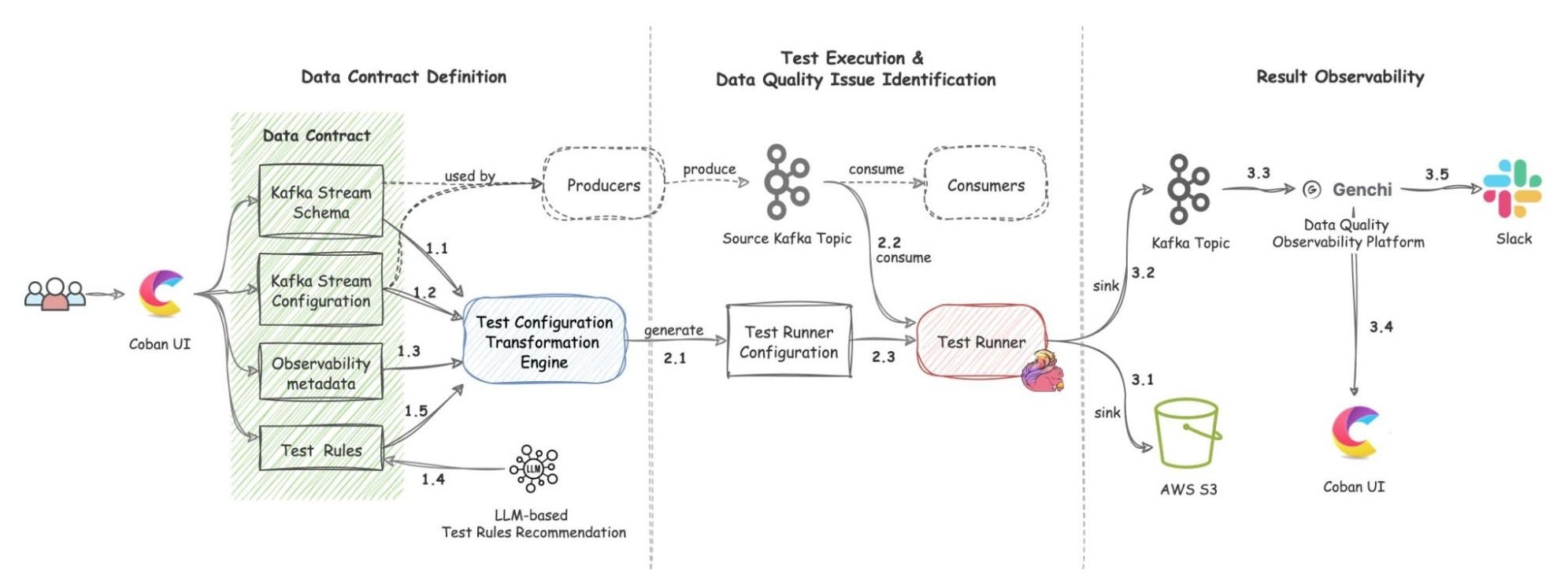
All Flow mentions after this refer to those diagrammed steps above
Data contract definition
Coban’s contract acts as a formal agreement among Kafka stream stakeholders. It includes a few building blocks.
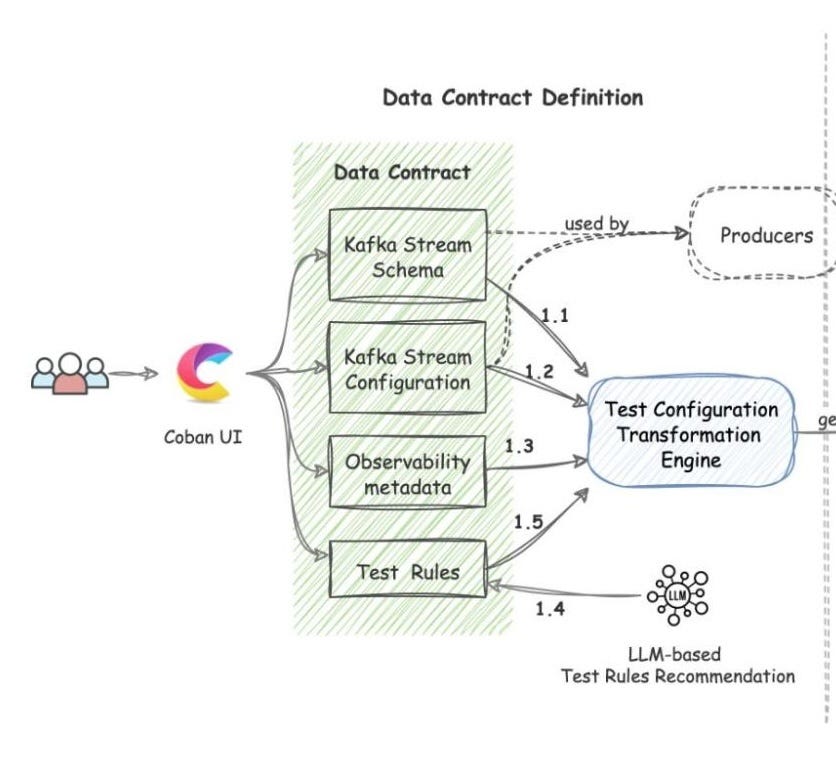
Kafka Stream Schema (Flow 1.1)
The contract includes the schema used by the Kafka topic under test. This helps the Test Runner validate schema compatibility across data streams.
Importantly, this is not only about “did the schema change.” It’s also about “does the data actually match what everyone believes the schema is.”
Kafka Stream Configuration (Flow 1.2)
This includes essential config like endpoint and topic name. Coban automatically populates this so users don’t have to wire everything manually.
Observability Metadata (Flow 1.3)
This is where ownership becomes real. The contract includes contact details for stream stakeholders and alert configurations so the right people get notified when issues show up.
Kafka Stream Semantic Test Rules (Flow 1.5)
This is the heart of the semantic side. Users can define intuitive field-level rules such as:
string pattern checks
number range checks
constant value checks
The point is to make the “meaning” of fields enforceable, not just their data types.
LLM-Based Semantic Test Rules Recommendation (Flow 1.4)
Defining dozens or hundreds of field rules can overwhelm people. To reduce that setup burden, Coban uses an LLM-based feature that recommends semantic test rules based on:
the provided Kafka stream schema
anonymized sample data
This feature helps users set up semantic rules efficiently, as demonstrated below
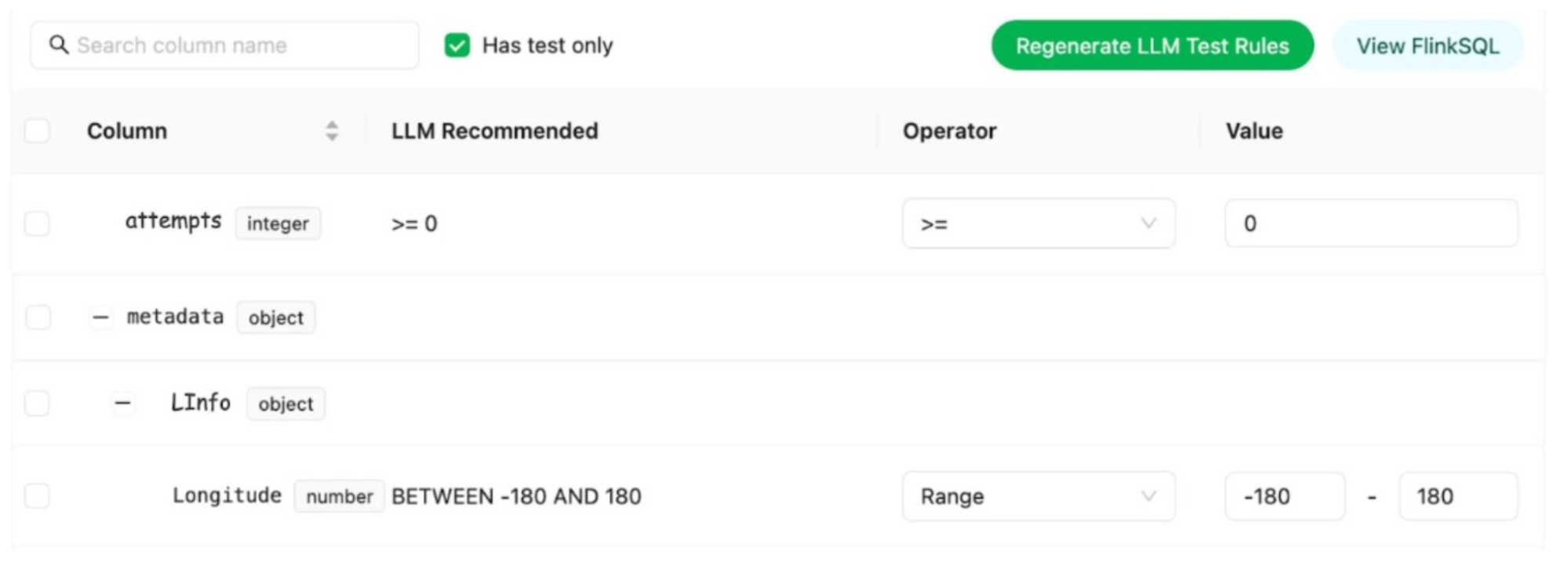
The practical benefit: users get a starting point quickly, instead of staring at a schema and trying to invent rules from scratch.
Data contract transformation
Once a contract is defined, Coban’s transformation engine converts it into configurations the Test Runner can interpret (Flow 2.1).
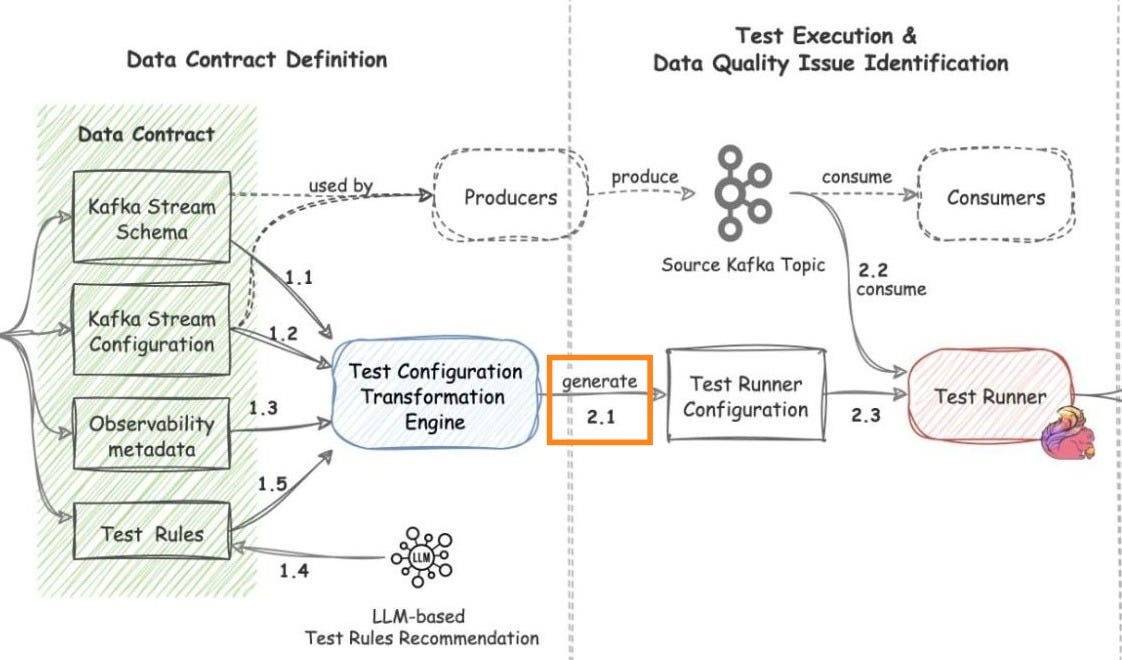
This transformation covers four things:
Kafka Stream Schema: The contract schema is translated into a schema reference format the Test Runner can parse.
Kafka Stream Configuration: The Kafka stream is set up as a source for the Test Runner.
Observability metadata: Contact information is turned into runtime configs for alerting and routing.
Kafka Stream Semantic Test Rules: Human-readable semantic rules are transformed into an inverse SQL query that captures data violating the rules.
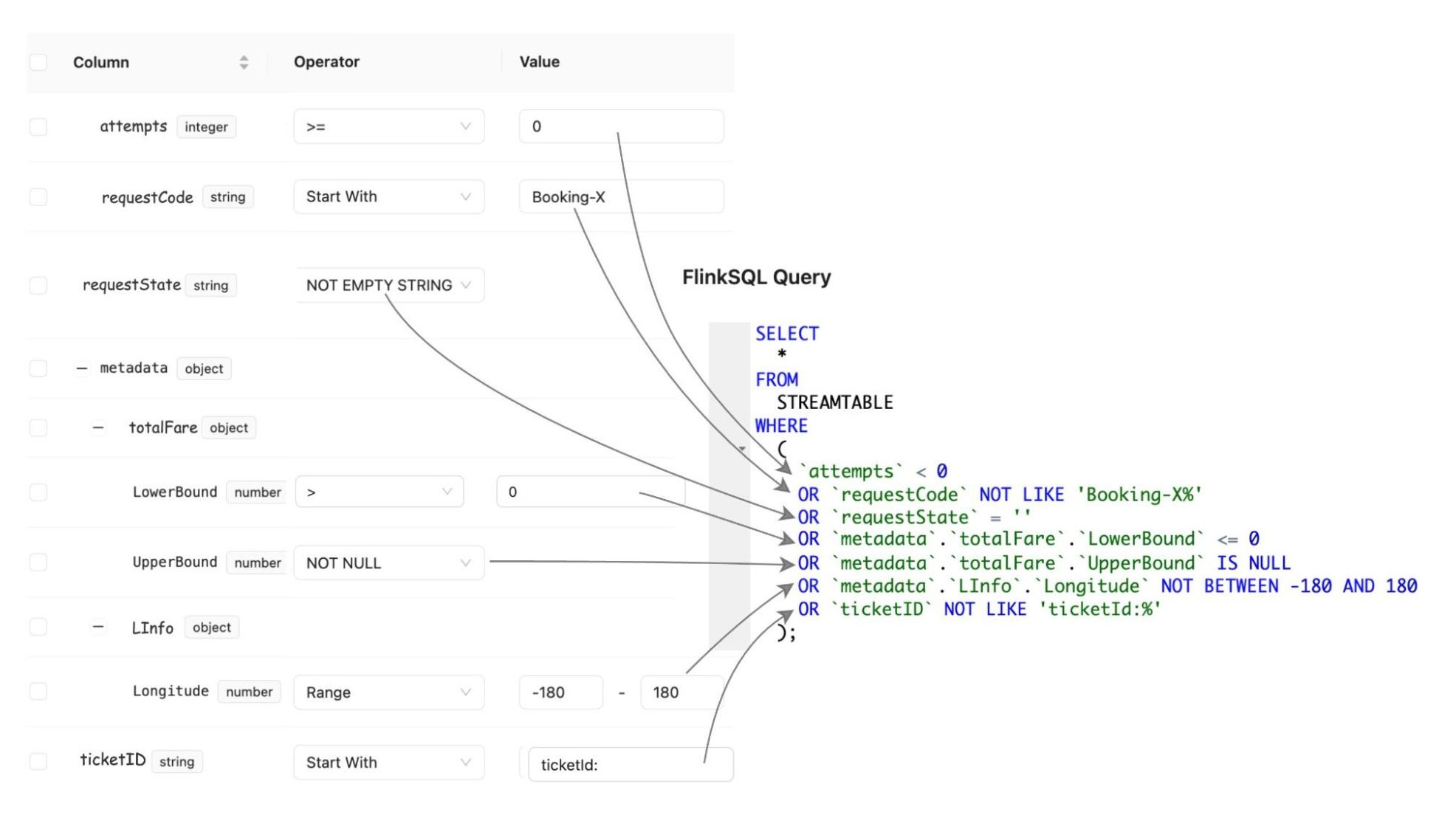
‘Inverse SQL’ here means the query is designed to return the bad rows, not the good ones. That’s a smart design choice because it keeps the output focused on what needs investigation.
Test execution & data quality issue identification
Once the transformation engine generates the configuration, the platform automatically deploys the Test Runner.
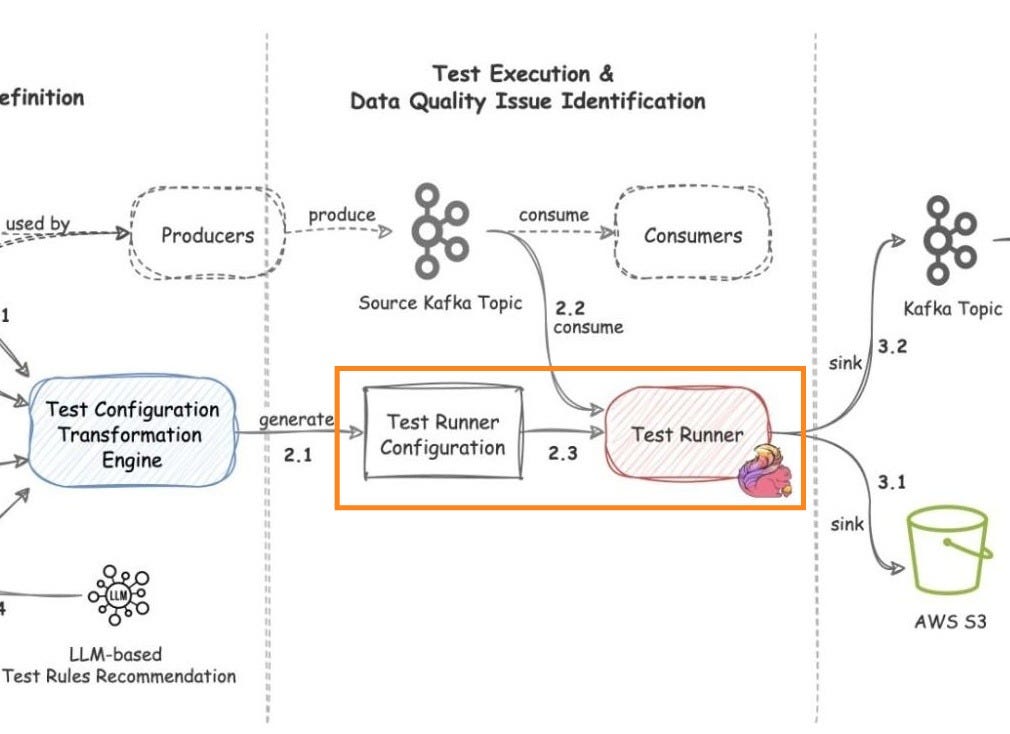
Test runner
The Test Runner uses FlinkSQL as its compute engine. FlinkSQL was chosen because it makes defining rules straightforward using SQL statements, which also makes it easier for the platform to convert contracts into enforceable checks.
Test execution workflow and problematic data identification
Below are the 4 steps undertaken to execute the test and identify problematic data:
Consume Kafka data (Flow 2.2)
FlinkSQL consumes data from the Kafka topic under test using its own consumer group. This is important because it avoids impacting other consumers.Run inverse SQL (Flow 2.3)
The Test Runner runs the inverse SQL query to identify:data that violates semantic rules
data that is syntactically incorrect “in the first place”
Publish data quality issue events (Flow 3.2)
When bad data is found, the Test Runner packages it into a data quality issue event enriched with:a test summary
total count of bad records
sample bad data
Then it publishes the event to a dedicated Kafka topic.
Sink events to S3 (Flow 3.1)
The platform also sinks all data quality events to an AWS S3 bucket for deeper observability and analysis.
This combo (Kafka for realtime events, S3 for deeper inspection) gives both fast alerting and a more durable store for later analysis.
Result observability
Grab’s in-house data quality observability platform, Genchi, consumes the problematic data captured by the Test Runner (Flow 3.3).
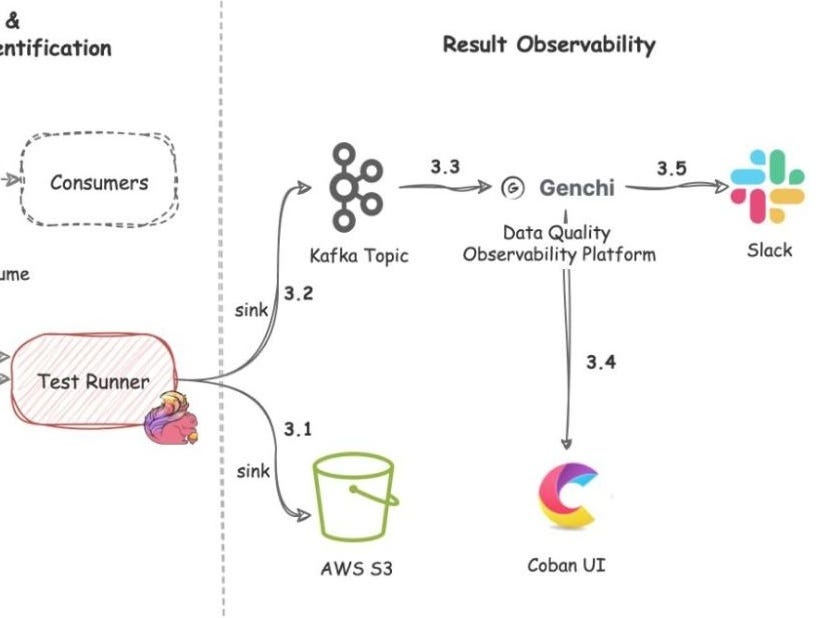
Alerting
Genchi sends Slack notifications to stream owners listed in the contract’s observability metadata (Flow 3.5).
Those notifications include useful debugging context such as:
links to sample data in the Coban UI
observed time windows
counts of bad records
other relevant details
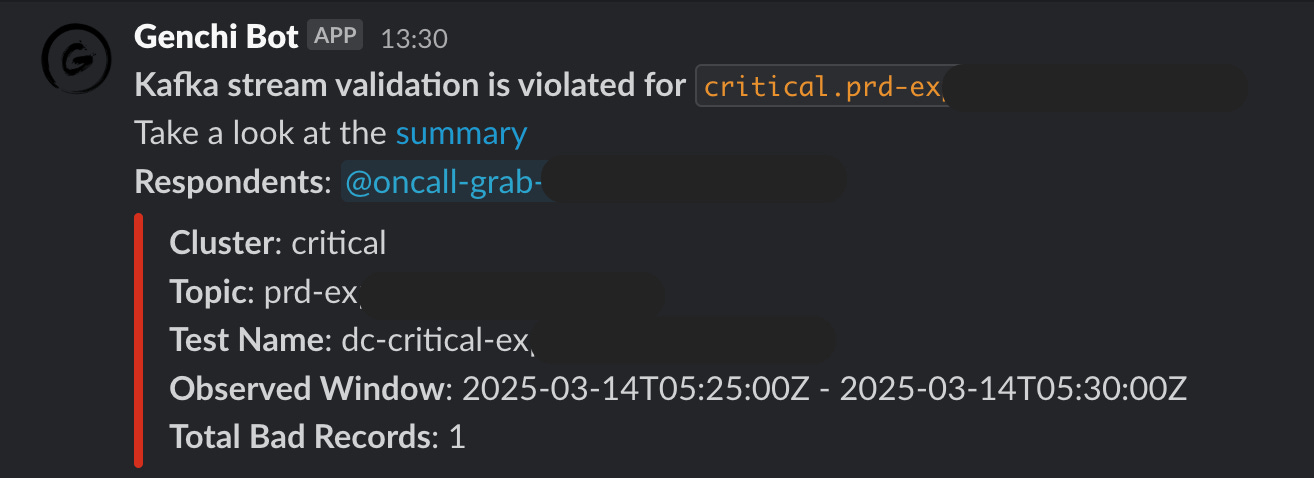
The key point is that alerts are not just ‘something broke’, they include the information you need to start investigating.
Observability
Users can access the Coban UI (Flow 3.4) to see:
Kafka stream test rules
sample bad records
highlighted fields and values that violate rules
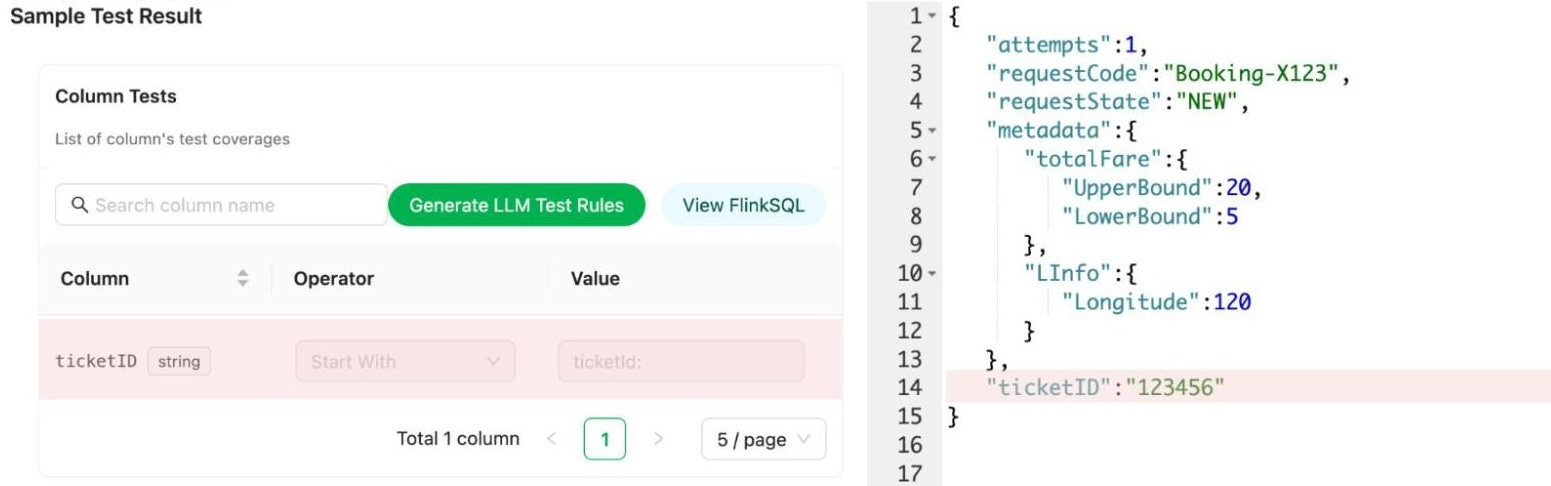
That UI piece matters because it shortens the path from ‘alert received’ to ‘I know what field is failing and what the bad values look like.’
Results so far
Since deploying earlier in the year, this solution enabled Kafka stream users to:
define contracts with both schema and semantic rules
automate real-time test execution
alert stakeholders when problematic data is detected so they can act quickly
It has been actively monitoring data quality across 100+ critical Kafka topics.
The solution also offers the capability to immediately identify and halt the propagation of invalid data across multiple streams.
Wrapping up
Grab implemented and rolled out a real-time data quality monitoring solution for Kafka streams through the Coban platform.
The key outcomes include:
engineers can define syntactic and semantic tests through a data contract
tests run automatically in real time via a long-running Test Runner based on FlinkSQL
issues trigger fast Slack alerts through Genchi using ownership metadata in the contract
teams get better visibility into exactly which data fields violate rules via the Coban UI
In short: Coban turned data quality from a vague hope into something stream owners can specify, enforce and observe in real time.
The full scoop
To learn more about this, check Grab's Engineering Blog post on this topic
If you are already subscribed and enjoyed the article, please give it a like and/or share it others, really appreciate it 🙏