
How Lyft Uses AI to Scale Translation Across 150+ Products
Inside the LLM pipeline targeting a 30-minute SLA for 95% of app and web translations.

Fellow Data Tinkerers!
Today we will look at how Lyft cut translation latency from days to minutes using AI
But before that, I wanted to share with you what you could unlock if you share Data Tinkerer with just 1 more person.
There are 100+ resources to learn all things data (science, engineering, analysis). It includes videos, courses, projects and can be filtered by tech stack (Python, SQL, Spark and etc), skill level (Beginner, Intermediate and so on) provider name or free/paid. So if you know other people who like staying up to date on all things data, please share Data Tinkerer with them!
Now, with that out of the way, let’s get to how Lyft turned localisation into a 30-minute AI workflow!
TL;DR
Situation
Lyft’s human-led localisation was high quality but too slow for Québec’s Bill 96 launch and European expansion.
Task
The team needed translations in minutes across 11 locales and 150+ services without losing terminology, tone, compliance or placeholders.
Action
Lyft built an LLM Drafter/Evaluator loop with retries, context injection, deterministic guardrails, prompt versioning and locale-specific tuning.
Result
Translation latency dropped from days to minutes, with a 30-minute SLA target for 95% of batch translations and 95% needing no major human edits.
Use Cases
translation quality evaluation, batch translation, AI-assisted localisation
Tech Stack/Framework
LLMs, Translation Management Systems, Pydantic, prompt engineering
Explained further
Context
For years, Lyft’s localisation setup was built around human translation. Human linguists usually meant strong quality, consistent terminology and fewer awkward mistakes in the app. When Lyft only supported a small number of languages like Spanish, Portuguese and French, multi-day turnaround times and translation costs that grew with every new language were manageable.
Then the business need changed.
Lyft’s Québec launch created a different level of pressure. Bill 96 required French-first user experiences, which meant localisation could not sit in a multi-day queue while product teams waited around. At the same time, Lyft Urban Solutions, the Bikes & Scooters division, wanted to expand into European markets and needed six new languages.
The old workflow was still good at quality, but it was too slow for the pace of the business. So Lyft rebuilt its translation pipeline around AI, while keeping linguists in the loop for review and final quality control. The goal was to reduce translation latency from days to minutes without turning product copy into awkward machine-translated text.
This article breaks down how Lyft did it: the architecture, the Drafter/Evaluator loop, context injection, deterministic guardrails, prompt versioning and locale-specific tuning.
Inside Lyft’s translation pipeline
Before getting into the LLM workflow, it helps to understand the scale of Lyft’s localisation platform.
Lyft’s platform now serves 11 locales across more than 150 services. That means localisation is not just a small content operation sitting next to the app. It is part of the product infrastructure. Translated strings have to flow reliably across many teams, services and surfaces.
The batch translation pipeline handles 99% of Lyft’s app and web content and targets a 30-minute SLA for 95% of translations. Lyft also supports real-time translation, such as ride chat, though that uses a different architecture and is not covered here.
At the centre of the batch pipeline is a dual-path design.
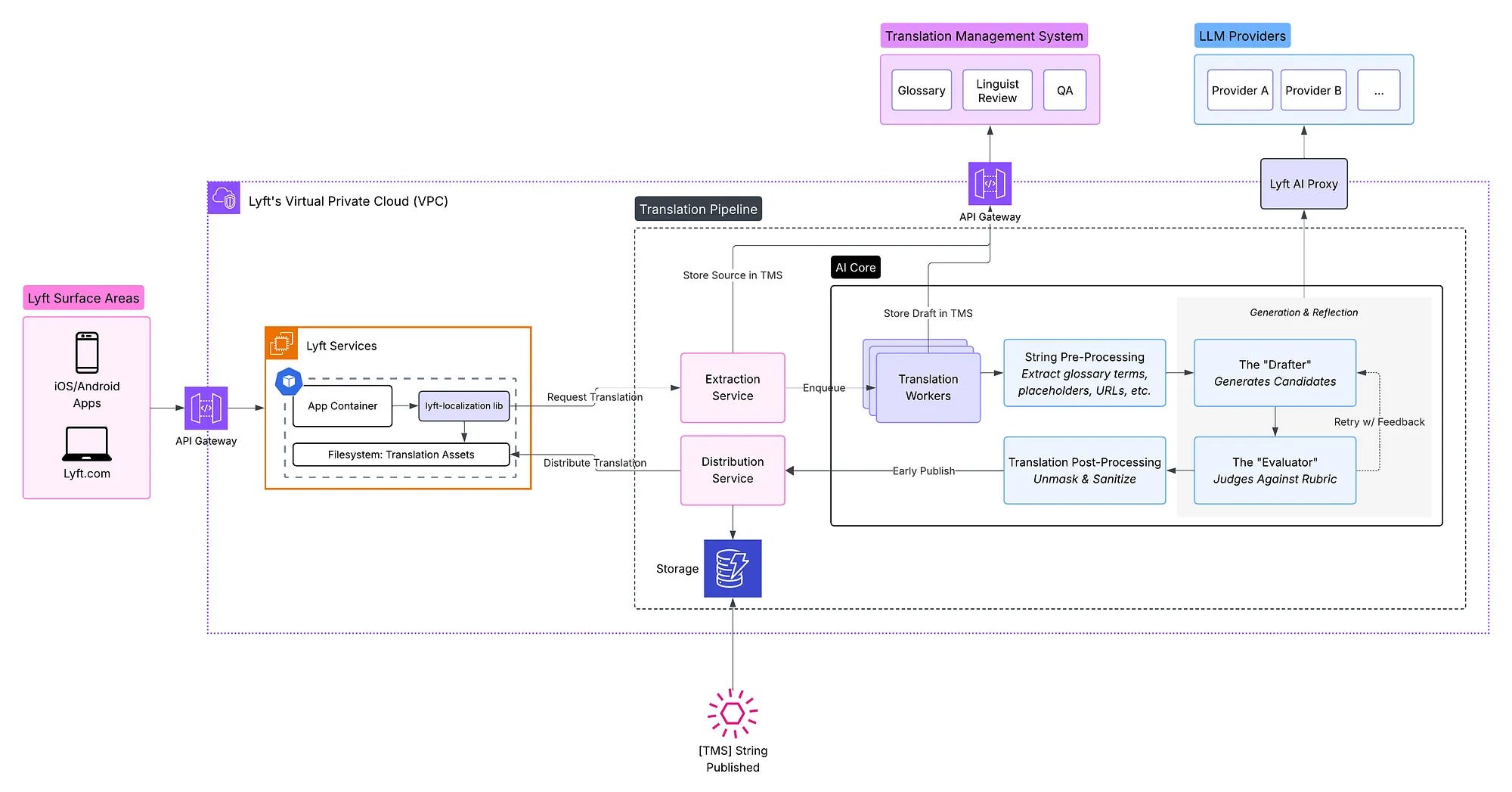
When requesters submit source strings, the pipeline sends them to Smartling, Lyft’s Translation Management System (TMS), for human oversight. At the same time, the same strings go to LLM workers for rapid draft generation.
That split is important because the LLM path gives product teams translated strings quickly enough to unblock launches but the TMS path keeps human review as the quality control layer and system of record. AI translations can ship early, then linguist-reviewed versions replace them once approved.
The batch pipeline has three main phases:
1- Drafting: where translation starts
Requesters submit source strings with context. This includes where the text appears in the UI, what the text is trying to communicate and what tone is expected. This context matters because short UI strings are often ambiguous.
‘Start ride’ is not just two words. It could be a button. It could be an instruction. It could refer to a driver, a rider, a scooter or a bike. Without context, the translation system is guessing.
The Drafter uses that context to generate translation candidates.
2- Unblocking launches: shipping the best draft fast
The Evaluator reviews the candidates and chooses the best one, or rejects all of them.
The selected translation can then be shipped within minutes, which allows product teams to keep moving instead of waiting days for a human translation cycle.
This early-release version is not treated as the final truth. It is a fast, quality-checked draft.
3- Finalisation: human approval and final quality control
Professional linguists review the translations inside the Translation Management System, or TMS. Once approved, the linguist-reviewed version replaces the early-release version and becomes the system of record. If a translation is flagged, it is corrected before distribution.
This dual-path setup is the key design choice.
The LLM path gives speed. The TMS path gives quality control and governance. The AI output can unblock launches, but the human-reviewed version still wins in the end.
Why Lyft chose LLMs over traditional translation?
Lyft started by evaluating traditional Neural Machine Translation providers. These systems were fast, but they often struggled with Lyft-specific terminology and product context.
That is a real problem in localisation because generic correctness is rarely enough. A translation can be grammatically fine while still being wrong for the product. It might ignore official terminology, mishandle regional phrasing, change the tone or translate something that should have stayed in English.
The Lyft team moved toward LLMs because they are better at using context. Traditional NMT services often process each string in isolation. LLMs can take in extra metadata, such as where the string appears, what the intended tone is, what glossary terms apply and which placeholders need to survive untouched.
That extra context is especially useful for product UI.
Take this string:
"Your {vehicle_type} is arriving in {eta_minutes} minutes"A human immediately sees a few things going on. The tone should probably be clear and calm. It likely appears in a time-sensitive user experience. It needs to sound natural but not too casual. And it may need region-specific wording.
LLMs can work with that additional context.
They can also evaluate translations, not just generate them. That matters because translation is rarely a single-answer problem. Multiple versions can be valid, but one may be clearer, more natural or more aligned with Lyft’s terminology.
This led to Lyft’s core architecture: one model drafts, another model evaluates, and the drafter refines based on feedback when needed.
Building a translation review loop
A simple machine translation pipeline would make one API call: send source text, receive translated text, ship it. But this would be an issue at scale for several reasons:
First, it has no nuance. The output may be technically correct, but not necessarily right for the brand, region or UI.
Second, it has no quality signal. There is no built-in way to know whether the translation is good enough before users see it.
Third, it has no recovery path. If the translation breaks a placeholder, ignores a glossary term or changes the meaning, the system has no structured way to repair it.
Lyft needed something closer to a human review loop: generate a few options, critique them, refine the result and only release a candidate that passes checks.
That became the Drafter and Evaluator pattern.
The “Drafter”: generating translation options
The Drafter’s job is to produce translation candidates. Lyft configures it to produce three distinct candidates for each source string. That is a simple but important design choice.
One translation often converges on the safest or most likely wording. That can be fine, but it may not be the best fit for the specific product context. By asking for three candidates, the system increases the chance that one version handles tone, terminology and regional phrasing better than the others.
For the Drafter, Lyft uses a fast, non-reasoning model. Translation generation is mostly a generative task, and standard models already perform well enough for this part of the workflow.
Speed matters because the system may need to retry. Cost matters because localisation touches a lot of strings. Using a frontier reasoning model for every draft would be overkill.
A simplified Drafter prompt looks like this:
DRAFTER_PROMPT = """
You are a professional translator for Lyft.
Translate into {language} for {country}.
Give {num_translations} translations of the following text.
GLOSSARY: {glossary}
PLACEHOLDERS (preserve exactly): {placeholders}
Text: {source_text}
"""For example:
source_text = "Your {vehicle_type} is arriving in {eta_minutes} minutes"
language = "French"
country = "Canada"The Drafter might return:
DrafterOutput(
candidates=[
TranslationCandidate(text="Votre {vehicle_type} arrive dans {eta_minutes} minutes"),
TranslationCandidate(text="Votre {vehicle_type} sera là dans {eta_minutes} minutes"),
TranslationCandidate(text="Votre {vehicle_type} arrivera d'ici {eta_minutes} minutes"),
]
)That gives the pipeline clear contracts between components. The Drafter returns a known object shape. The Evaluator receives candidates in a predictable format. Parsing is less brittle.
The “Evaluator”: choosing the best translation
The Evaluator acts as a quality gate. It receives all candidates from the Drafter, checks them against a rubric and then either selects the best candidate or rejects the batch.
Lyft uses a reasoning-focused model for this step because evaluation requires comparison and judgment. The model has to check whether the source meaning is preserved, whether glossary terms are followed, whether the tone fits and whether placeholders survived the trip.
The Evaluator grades each candidate across four dimensions.
Accuracy and clarity: Does the translation preserve the full meaning of the source? Is it clear?
Fluency & adaptation: Does it read naturally to a native speaker? Is it appropriate for the target region?
Brand alignment: Does it use official Lyft terminology? Are brand names, proper nouns and airport codes preserved correctly?
Technical correctness: Are spelling, grammar, placeholders and required terms handled properly?
Each candidate receives a grade: pass or revise. If any candidate passes, the Evaluator picks the best one. If all candidates fail, it explains why.
Example output:
EvaluatorOutput(
evaluations=[
CandidateEvaluation(
candidate_index=0,
grade=Grade.PASS,
explanation="Accurate, natural phrasing."
),
CandidateEvaluation(
candidate_index=1,
grade=Grade.PASS,
explanation="Natural and conversational."
),
CandidateEvaluation(
candidate_index=2,
grade=Grade.REVISE,
explanation="'d'ici' implies uncertainty, inappropriate for ETA."
),
],
best_candidate_index=0,
)That last point is a good example of why evaluation matters. The third candidate may look reasonable at first glance, but the phrase introduces uncertainty that does not belong in an ETA message. It is the sort of subtle issue a simple string-by-string translation system can miss.
Why Separate Drafter and Evaluator?
Separating the Drafter and Evaluator gives Lyft several advantages.
The first is practical: spotting errors is often easier than producing the ideal translation on the first attempt. The Evaluator does not need to be the world’s greatest translator. It needs to be a strong reviewer with a clear rubric.
The second is bias reduction. A model judging its own work can be too forgiving. It already has the context of why it chose a phrase, which can make it less likely to challenge the result.
The third is cost control. Lyft can use a faster model for drafting and a more capable reasoning model for evaluation. This keeps the expensive judgment step focused where it matters.
How failed translations get a second (or third) chance
When the Evaluator rejects every candidate, the pipeline does not immediately give up. It captures the critique and feeds it into the Drafter’s next attempt.
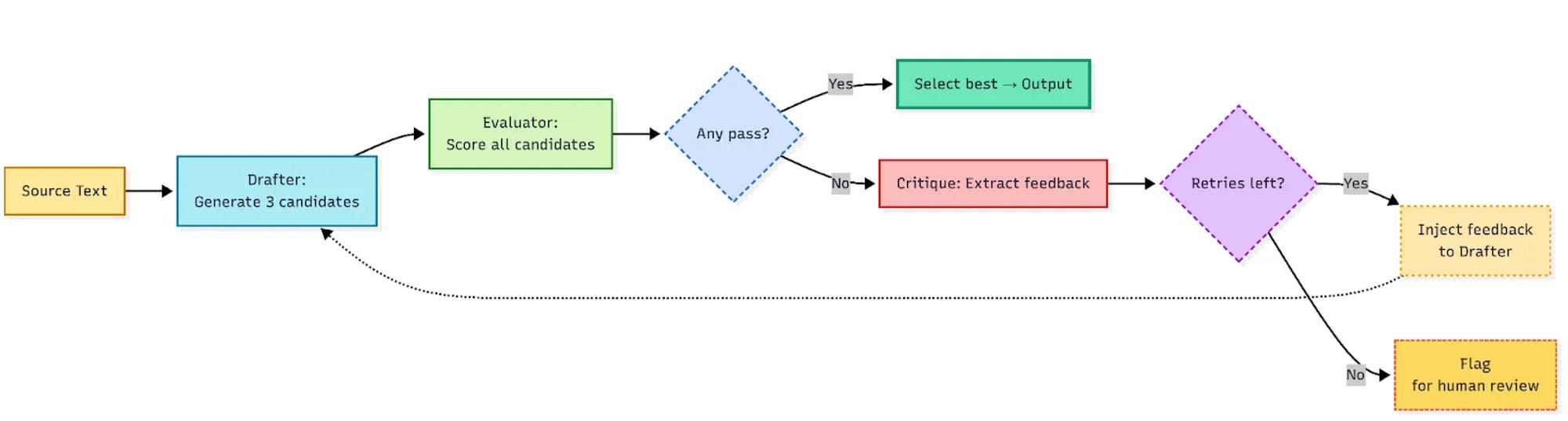
Lyft limits this loop to three attempts. The team found that most of the gains come from the first one or two cycles, so three attempts create a useful balance between quality, latency and cost.
A retry critique might look like this:
critique_for_retry = """
All candidates failed glossary compliance. Key issues:
- "Ride" must be translated as "trajet" per Lyft Quebec glossary
- Do not use "course" which is European French
"""The next Drafter prompt explicitly tells the model what failed and what needs to be fixed: glossary usage, placeholders, tone or formatting.
This feedback loop produces a success rate of more than 95% across most languages. For cases where the Drafter and Evaluator still cannot agree after three tries, the string falls back to the human workflow. Product teams can wait for linguist review in the TMS or request an expedited translation for urgent launches.
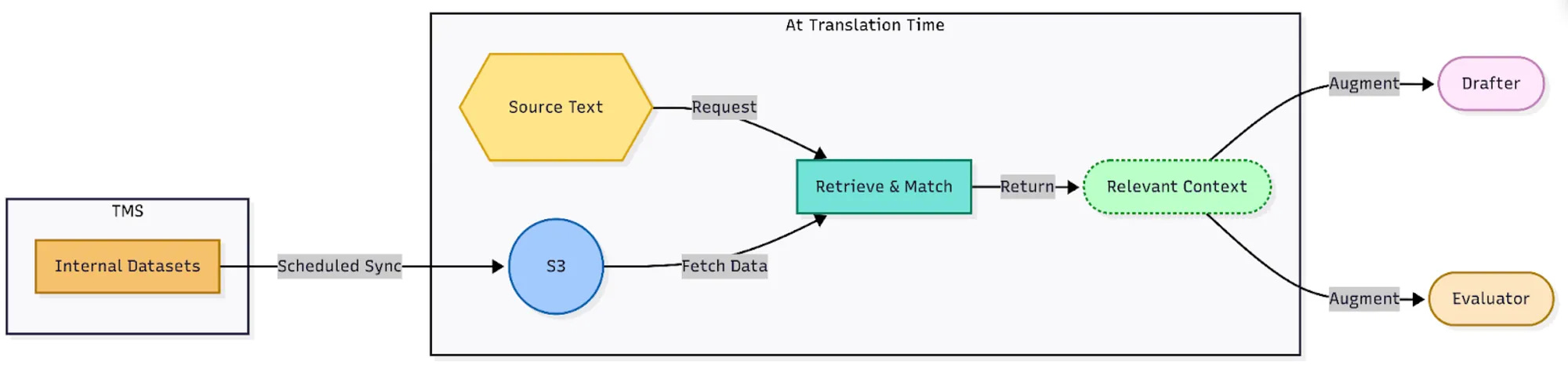
Giving the model Lyft’s translation rules
LLMs do not automatically know Lyft’s internal terminology rules. They do not know that {driver_name} is a code variable that must be preserved. They do not know that a certain term should use Lyft’s official translation in Québec French. They do not know which product names should stay in English.
So Lyft injects context into the prompts. The pipeline uses glossary terms, do-not-translate lists and reference data from the TMS.
Glossary terms include official translations for individual words and phrases. For example, “Driver” may need to be translated as “Chauffeur” in French, depending on Lyft’s approved terminology.
Do-not-translate lists cover brand names, product names and proper nouns that should remain in English.
These assets are maintained by linguists and periodically pulled into the Translation Pipeline. It gives both the Drafter and Evaluator the production-specific information they need.
Where rules matter more than prompts
Prompts can reduce errors but they cannot fully prevent them.
LLMs are probabilistic. They may translate placeholders, remove URLs, alter formatting or corrupt structured text. For production localisation, that is a serious problem.
Lyft observed several recurring issues. Placeholder translation was the most common failure mode. For example, {driver_name} could become {nom_du_conducteur}.
Lyft’s guardrail system works in two phases: pre-translation extraction and post-translation validation.
Pre-Translation: masking what must not change
Before content reaches the LLM, the pipeline extracts elements that must be preserved exactly. This includes variables and format strings such as {driver_name}, {eta}, %s, %1$s and %@.
It also includes URLs, email addresses, region codes, HTML tags and escape sequences such as \n, \t and \r. These elements are replaced with numbered tokens like __PH_0__, __PH_1__ and __PH_2__.
Example:
Original:
"Hey {first_name}! Your Lyft arrives at {eta}.\nTrack: https://lyft.com/r/abc"
Masked:
"Hey __PH_0__! Your Lyft arrives at __PH_1__.__PH_2__Track: __PH_3__"
Mapping:
__PH_0__ → {first_name}
__PH_1__ → {eta}
__PH_2__ → \n
__PH_3__ → https://lyft.com/r/abcThe mapping is included in the prompt so the LLM understands what each token represents and what needs to be preserved.
The numbering also handles reordering. Different languages may place variables in different parts of the sentence, and the token mapping allows that movement without losing the original placeholder.
Post-Translation: validating before release
After the LLM returns a translation, the pipeline validates it before accepting the result. Validation checks that every expected token appears exactly once, no unexpected tokens were introduced and structured content such as HTML tags remains balanced.
When validation fails, the exact error is passed into a retry prompt. For example, the model might be told that __PH_2__ is missing and that it represents \n. That gives the next attempt a concrete repair instruction rather than a vague ‘please do better’, which, to be fair, is a management style but not a validation strategy.
Once validation passes, the tokens are restored:
Translated:
"Salut __PH_0__! Votre Lyft arrive à __PH_1__.__PH_2__Suivre: __PH_3__"
Restored:
"Salut {first_name}! Votre Lyft arrive à {eta}.\nSuivre: https://lyft.com/r/abc"Treating prompts like production code
In early development, Lyft treated prompts like configuration. The team tweaked wording, tested manually and deployed changes with limited review.
That created a problem. A small prompt change in the Evaluator could increase false rejections, and without proper testing it was difficult to detect the regression or roll back safely.
Lyft now treats prompts as production code.
Prompt templates live alongside the Translation Pipeline code. They go through review. Each prompt version includes a changelog that explains what changed and why. Prompt and model changes are tested against an evaluation suite before receiving production traffic.
The team evaluates changes against ground truth translations in the TMS. Divergences from linguist-approved versions are flagged and reviewed before rollout.

This is a useful lesson for LLM systems generally. Prompts influence system behaviour, so they deserve the same discipline as code: version control, review, testing and rollback.
Testing models without locking into one provider
Lyft does not commit the pipeline to a single model provider. The LLM layer is abstracted, and experimentation happens through Lyft’s configuration infrastructure.
That setup supports traffic splitting, so new models can receive 5%, 20% or 50% of requests. It supports shadow mode, where a candidate model runs in parallel without affecting production. It also supports per-locale overrides and instant rollback without a deploy.
Example config:
drafter:
model: <fast-generation-model>
fallback: <fallback-model>
prompt: <prompt-id>
shadow:
model: <candidate-model>
prompt: <prompt-id>
traffic_percent: 10
evaluator:
model: <reasoning-model>
fallback: <fallback-model>
prompt: <prompt-id>
reasoning_effort: medium
locale_overrides:
<locale_code>:
evaluator:
reasoning_effort: highThrough experimentation, Lyft found that faster and cheaper models perform comparably to frontier models for initial generation, while reasoning-focused models do much better at catching subtle evaluation errors.
Tuning prompts to each locale
Different locales need different handling.
Lyft saw this clearly with English variants such as en-GB and en-CA. These variants often require spelling, punctuation and vocabulary adjustments rather than full translation.
For example:
color → colour
trunk → bootWithout clear constraints, the model can overdo it. A simple ‘Try again’ button can become ‘Have another go’. That may be valid British English, but it changes the product voice. It may feel too playful or inconsistent with Lyft’s product voice.
To prevent this, Lyft uses locale-specific overrides that narrow the scope of transformation:
LOCALE_OVERRIDE_EN_GB = """
You are adapting American English text for British English speakers.
IMPORTANT: This is an ORTHOGRAPHIC adaptation, not a full translation.
Only change:
- Spelling (color → colour, center → centre, organize → organise)
- Punctuation conventions where required
DO NOT change:
- Tone or voice
- Sentence structure
- Casual vs. formal register
- Idioms or expressions (unless they are specifically American and would confuse UK readers)
The goal is that a British reader sees familiar spelling, not that the text "sounds British."
"""This reduced over-adaptation while keeping Lyft’s brand voice consistent across locales.
What Lyft’s localisation pipeline gets right
Lyft’s localisation pipeline shows how LLMs can be useful in production when the system is designed around their strengths and weaknesses.
The models generate candidates quickly. A separate evaluator reviews them against a rubric. Retry loops repair failures. Context injection keeps terminology aligned with Lyft’s glossary. Deterministic guardrails protect placeholders, URLs, formatting and structured content. Human linguists still review the final output inside the TMS.
That combination reduced translation latency from days to minutes while keeping quality control in place.
The most interesting part is the balance. Lyft uses AI to remove the slowest parts of the workflow, while still relying on deterministic checks and human review where they matter most. The system does not ask the model to be perfect. It gives the model a well-defined job, checks the output and escalates hard cases.
Through this setup, Lyft sees 95% of translations needing no significant changes after linguist review. The remaining 5% tend to be the hard cases: regional idioms, legal language and brand voice decisions.
That feels like the right division of labour. Let the machine handle the repeatable work at speed. Let deterministic systems catch mechanical failures. Let humans focus on the judgment calls where context, nuance and risk actually matter.
Also, keep the placeholders alive. Somewhere out there, {driver_name} is depending on it.
The full scoop
To learn more about this, check Lyft's Engineering Blog post on this topic.
If you are already subscribed and enjoyed the article, please give it a like and/or share it others, really appreciate it 🙏
Keep learning
How Pinterest Used Multimodal AI to Help Millions of Shoppers

Pinterest turned billions of products into 4.2 million shopping landing pages and improved search performance by 35%.
Behind that was a content-first system built to understand product images and metadata, compress noisy attributes into a usable vocabulary and match products to topics across a massive catalog.
This piece breaks down how Pinterest used vision-language models, contrastive learning and distributed inference to make products easier to discover.
How Shopify Scales Taxonomy Evolution Across 10,000+ Categories With Multi-Agent AI

Shopify frames taxonomy at scale as three problems: volume, expertise, and consistency.
When you’re operating a taxonomy with 10,000+ categories, manual review will not work. and by the time you react, merchants are already listing products that don’t fit.
This piece breaks down how Shopify moved from reactive manual updates to a multi-agent system that scans taxonomy branches in parallel, proposes new categories/attributes from merchant data, detects duplicates via equivalence relationships and runs automated QA through domain-specific judges.