
How Pinterest Used Multimodal AI to Help Millions of Shoppers
Inside the multimodal AI pipeline that converted images, metadata and search behavior into scalable shopping discovery.

Fellow Data Tinkerers!
Today we will look at how Pinterest used multimodal AI to organise products into relevant shopping collections
But before that, I wanted to share with you what you could unlock if you share Data Tinkerer with just 1 more person.
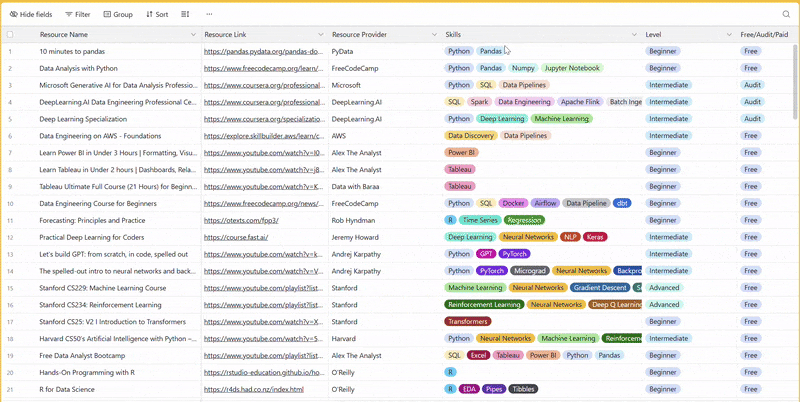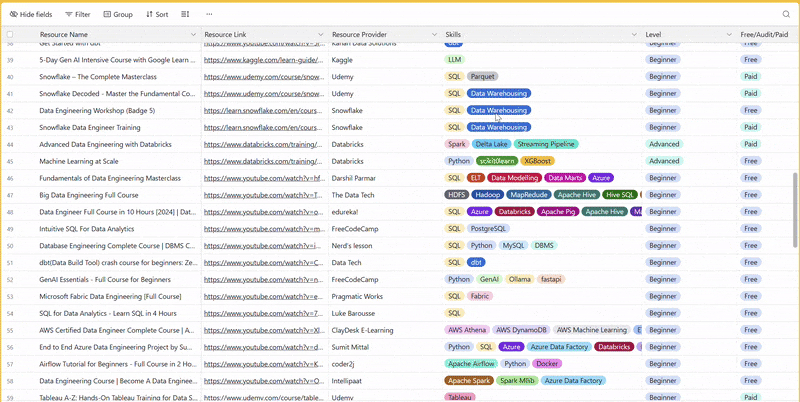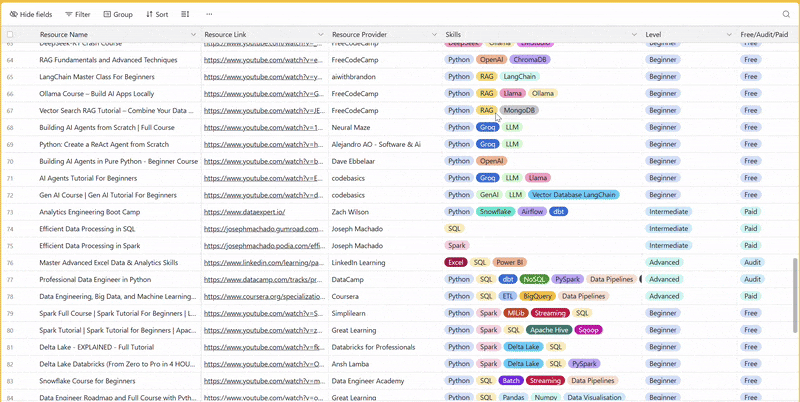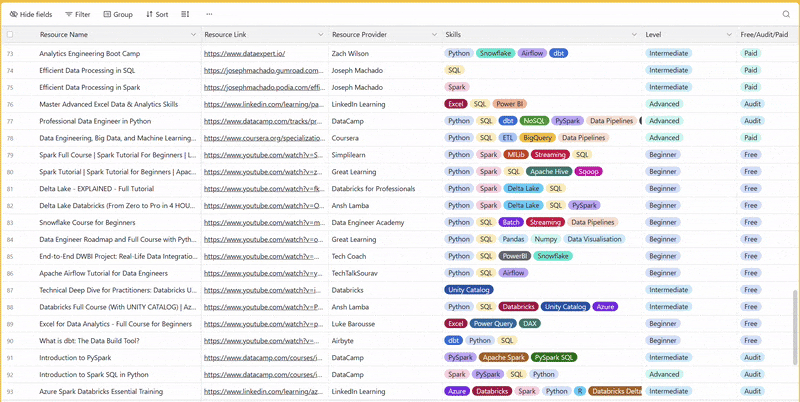
There are 100+ resources to learn all things data (science, engineering, analysis). It includes videos, courses, projects and can be filtered by tech stack (Python, SQL, Spark and etc), skill level (Beginner, Intermediate and so on) provider name or free/paid. So if you know other people who like staying up to date on all things data, please share Data Tinkerer with them!
Now, with that out of the way, let’s get to PinLanding: Pinterest’s AI system for shopping collections

Situation
Traditional shopping collections built from search logs and manual curation were not enough to cover the growing mix of detailed, compositional and AI-native shopping queries.
Task
Build a scalable system that could generate precise, searchable shopping collections directly from product content while still aligning with real user shopping intent.
Action
Pinterest built PinLanding, a multimodal pipeline that used search behavior to identify intent gaps, vision-language models to extract product attributes, clustering and LLM-as-judge to clean and validate a shopping vocabulary, a CLIP-style model to assign curated attributes at scale and Ray plus Spark to run large-scale inference and feed construction.
Result
The system generated 4.2 million shopping landing pages, expanded unique topics by 4x, improved average Precision@10 from 0.84 to 0.96 and delivered a 35% lift in search performance.
Use Cases
Search relevance improvement, attribute tagging, catalog enrichment, cold-start collection generation
Tech Stack/Framework
Apache Spark, Ray, PyArrow, CLIP, VLM
Explained further
Context
Online retailers and social platforms now manage catalogs with billions of items. Pinterest is one example, but the underlying problem is much broader: how do you organize massive product inventories into shopping collections that people can actually browse?
Pinterest has been dealing with exactly that. Historically, shopping collections were mostly shaped by user search history and manual curation. That worked well enough when search behavior was more predictable and the long tail was smaller. It works a lot less well when people start searching in full sentences, asking for vibes, aesthetics and combinations of constraints all at once.
That shift is what makes PinLanding interesting.
Instead of waiting for search logs and human curation to define the collection space, Pinterest’s team flips the process around. The system starts from the product content itself, then builds shopping collections from that foundation while still staying grounded in how people actually search. In other words, it is content-first, but not content-only.
The system is built around four components: understanding user search patterns, building and validating a shopping collection vocabulary using multimodal LLMs and LLM-as-judge, constructing feeds from attributes and evaluating the system while adapting to AI-native search behavior.
1. Mapping what shoppers actually want
The system starts with something fairly practical: understanding what users are actually trying to do.
Pinterest aggregates signals from search history, autocomplete interactions, filter usage and browse paths to estimate the distribution of shopping intents across the catalog. The goal here is not to build a giant list of every possible topic. It is to get a grounded picture of current demand, current coverage and where the system is falling short.
Two clear patterns show up.
The first is the head of the distribution: high-volume, well-formed shopping queries like ‘black cocktail dress’ or ‘white linen pants.’ These are the kinds of searches traditional collection systems already handle reasonably well. They are structured, frequent and easy to tie back to existing ranking and merchandising logic.
The second is where things get more interesting. There is a growing long tail of conversational and compositional queries, especially as users get more comfortable interacting with AI systems. These are requests that blend style, occasion, constraints and subjective framing like ‘what to wear for Italian summer vacation’ or ‘long red satin dress with lace trim under $200’. They are describing a scenario or aesthetic.
That distinction matters because it reveals the limitations of a purely query-driven collection pipeline. The head is manageable. The tail is messy, sparse and expanding.
Pinterest uses these behavioral signals in three ways. First, they highlight product spaces where user demand is strong but collection coverage is still thin. Second, they reveal which attribute dimensions users care about, including things like color, occasion, style, fit, price and brand, across 20 categories. Third, they create the baseline against which the rest of the pipeline is evaluated.
That last point is important. PinLanding is not trying to throw away query understanding. It is trying to improve topical coverage and precision relative to the old query-driven baseline. Search behavior still matters. The difference is that the system no longer depends on search logs alone to decide what collections can exist.
2. From raw product content to searchable shopping topics
Once Pinterest understands the behavior surface, the next step is to describe each product in a structured way that is useful for collection generation.
Each product is modeled as a multimodal tuple made up of an image plus metadata like title, description, merchant tags and price. A vision-language model (VLM) is then used to generate candidate attributes for that product. Rather than producing free-form descriptions, the model is prompted to return normalized key-value pairs. That design choice makes downstream processing far easier because it turns messy visual and textual information into something closer to structured data.
The initial output is broad and useful in one sense because it has high recall. It captures lots of possible attributes. The problem is that it is too messy to use directly.
The raw VLM output tends to overproduce highly specific descriptors like ‘black insoles’ or ‘lace-trim hem with side slit.’ It also produces near-duplicate variants such as ‘boho,’ ‘bohemian’ and ‘boho-chic’ for what is basically the same shopping concept. That creates a sparse attribute space where too many labels apply to too few products. Once that happens, collection quality starts to fall apart. You end up with lots of tiny fragments instead of reusable shopping topics.
Pinterest addresses this with a curation pipeline designed to build a compact and reusable attribute vocabulary.
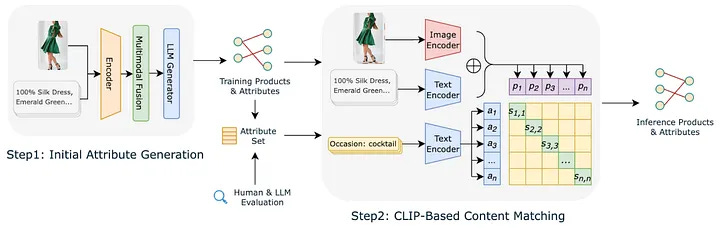
The first step is frequency filtering. Attributes that appear only on a tiny number of products are rarely useful as collection keys, so they are removed. This strips out many ultra-specific descriptors while keeping the attributes that are more likely to reflect reusable shopping concepts.
The second step is embedding-based clustering. Dense text embeddings are generated for the remaining attributes and highly similar attributes are merged. When multiple variants express the same idea, the more frequent surface form becomes the canonical one.
The final step uses LLM-as-judge to score candidate topic-query pairs. Given an attribute tuple and its generated query, a second LLM evaluates whether the pair is semantically coherent, whether it sounds like a plausible shopping intent and whether it matches typical search phrasing. This helps rank and filter candidate topics not just for internal consistency but for searchability.
That last part is the key difference between extracting attributes and building shopping topics. Attributes by themselves are too granular and too raw. The curation pipeline turns them into a vocabulary that is compact enough to scale and natural enough to match how people actually search.
2.1 Scaling attribute assignment with a CLIP-style model
Once the curated attribute vocabulary exists, the next question is how to assign those attributes across the full product catalog.
Running the original vision-language model on every product at production scale would be expensive and brittle. So Pinterest trains a dual-encoder model inspired by CLIP instead.
One encoder takes product image and text as input and produces a product embedding. The other encoder takes an attribute phrase and produces an attribute embedding in the same vector space. During training, product-attribute pairs generated from the VLM are treated as positive examples, while non-matching pairs act as negatives.
The training objective is bidirectional contrastive loss. Matching product-attribute pairs are pulled closer together in embedding space and mismatched pairs are pushed apart.

At inference time, the system embeds all products and all attributes once. An attribute is assigned to a product when the similarity between the two embeddings crosses a calibrated threshold. That threshold can also be adjusted with frequency-based weighting to counter long-tail smoothing.
This architecture solves a few problems at once.
It is cheaper than running the VLM everywhere. It creates a denser and more consistent attribute graph. And it reduces the explosion of distinct attributes that came from raw model outputs.
Interestingly, they note that the resulting system ends up with fewer distinct attributes overall, while increasing the average number of attributes per product. That is a useful tradeoff. Fewer labels does not mean less information here. It means the information is compressed into a vocabulary that is actually reusable.
That dense attribute graph becomes the foundation for everything that follows.
3. Building shopping feeds at catalog scale
Once products have been tagged with curated attributes, Pinterest needs to construct feeds at catalog scale. That means dealing with millions of Pins and millions of possible topics.
That is where Ray and large-scale batch inference come in.
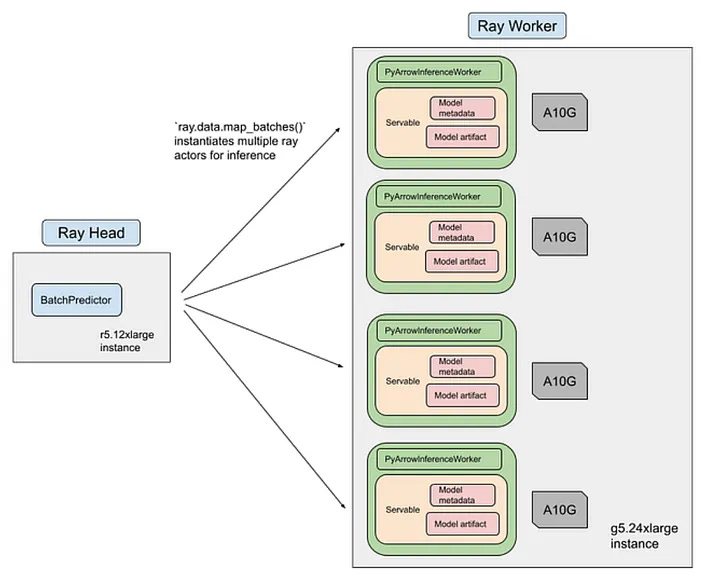
Attribute inference runs as a Ray streaming job with three main stages.
The first stage handles data loading and preprocessing. Product images and metadata are downloaded, tokenized and serialized into PyArrow tables, then sharded across a CPU cluster.
The second stage handles ML inference. Ray schedules preprocessed batches onto a GPU pool where the CLIP-based classifier performs forward passes and produces attribute scores.
Because execution is streamed, data loading, preprocessing and inference can overlap instead of waiting on one another. The use of heterogeneous clusters also allows CPU-heavy preprocessing and GPU-heavy inference to scale independently. The training and inference pipeline for the classifier completes in roughly 12 hours on 8 NVIDIA A100 GPUs at an estimated cost of about $500 per training run. For a system operating at this scale, that is pretty reasonable.
Once attribute assignments are available, feed construction moves to a matching layer built around ANN-style and strict attribute matching via Spark.
Each shopping topic is defined as an attribute tuple. For example: category equals dress, color equals yellow, season equals summer, occasion equals party.
Spark is then used to compute relevance scores between topics and products. The scoring aggregates shared attributes between topic and product, weighted by attribute-level confidence.
To keep this tractable, candidate joins are pruned through attribute-based partitioning and minimum-overlap prefilters.
This part is easy to underestimate. Generating a topic vocabulary is one thing. Turning that vocabulary into feeds across millions of products is where many systems fall apart. Pinterest’s design works because the modeling and infrastructure choices line up. The attribute space is structured enough to match efficiently and the batch inference stack is built to operate at the right scale.
4. Measuring whether the system actually works
Pinterest evaluates the system at both the attribute level and the collection level.
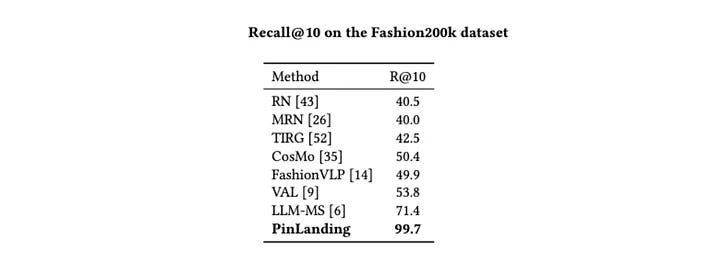
For attribute quality, the CLIP-based model is tested on Fashion200K, a standard benchmark for fashion attribute prediction. The reported result is 99.7 percent Recall@10, which substantially exceeds prior methods that sit in the 50 percent range on the same metric. That suggests the model has learned a strong mapping between product imagery and fashion attributes.
Pinterest also looks at the distribution of generated attributes. Compared with raw GPT-4-V outputs, the CLIP-based system produces a much more usable attribute space. There are fewer extremely rare attributes and more attributes that consistently apply across many products.
That is important because quality here is not only about benchmark performance. It is also about whether the resulting label space can support downstream shopping tasks without collapsing into noise.
For collection quality, human raters compare feeds produced by the content-first pipeline against a traditional search-log-derived baseline. The evaluation uses Precision@10, measured as the fraction of the top ten products in a collection that match the collection’s title attributes.
Across attribute families including color, main material, fit and stretch, shape, style, season and festival, occasion and brand, the new system improves average Precision@10 from 0.84 to 0.96. Several categories, including style and brand, reach 1.00.
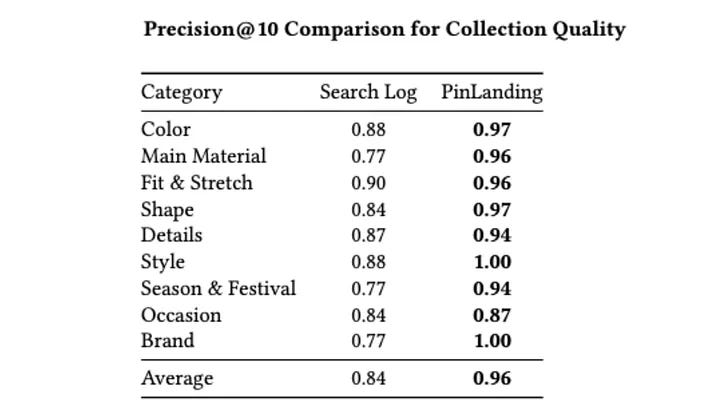
That is a meaningful jump. It suggests the collections are not just broader in coverage, but also more precise in the items they surface.
In production, the pipeline generates 4.2 million shopping landing pages. That represents a fourfold increase in unique topics relative to the previous search-log-based approach and leads to a 35% improvement in search performance.
That combination is what makes PinLanding interesting because it is not only producing cleaner labels in an offline benchmark but also expanding coverage and improving relevance in production.
Summary
PinLanding is a strong example of what multimodal AI looks like when it is pushed into production with actual constraints.
The system does not rely on a single model to do everything. Instead, Pinterest breaks the problem into stages: measure intent, generate structured attributes, compress them into a usable vocabulary, scale assignment with a dual encoder and then construct collections with distributed matching.
That decomposition is probably the most useful lesson here.
There are plenty of teams experimenting with multimodal models for product understanding. The harder part is turning those outputs into something dense, normalized and operationally stable enough to support search and discovery at web scale. Pinterest’s team shows a fairly clear path for doing that.
The broader shift is also worth noting. Search-log-derived collections are not going away, but they are no longer enough on their own. As people search in more conversational, compositional and trend-driven ways, systems need to infer collections from the content itself while still staying anchored to user intent.
That is the balance PinLanding is aiming for.
And for platforms sitting on billions of products, that balance is probably becoming less of a nice-to-have and more of a survival requirement.
The full scoop
To learn more about this, check Pinterest's Engineering Blog post on this topic
If you are already subscribed and enjoyed the article, please give it a like and/or share it others, really appreciate it 🙏
Keep learning
How Shopify Scales Taxonomy Evolution Across 10,000+ Categories With Multi-Agent AI

Shopify frames taxonomy at scale as three problems: volume, expertise, and consistency.
When you’re operating a taxonomy with 10,000+ categories, manual review will not work. and by the time you react, merchants are already listing products that don’t fit.
This piece breaks down how Shopify moved from reactive manual updates to a multi-agent system that scans taxonomy branches in parallel, proposes new categories/attributes from merchant data, detects duplicates via equivalence relationships and runs automated QA through domain-specific judges.
How to Build a Recommendation System at Scale: Insights from Instacart

Production ML isn’t only about clever architectures. It’s about judgment, trade-offs and systems that hold up when data is messy.
I sat down with Ahsaas Bajaj , Senior ML Engineer at Instacart, to talk about how they handle product substitutions at scale, what actually moves business metrics and what changes when you move into a senior ML role.