
How Snap Rebuilt Its ML Platform to Handle 10,000+ Daily Spark Jobs
Inside Prism, the system that turned scattered Spark workflows into a unified, ML-ready platform.

Fellow Data Tinkerers!
Today we will look at how Snap unified Spark, ML workflows and 10k+ daily jobs under one platform.
But before that, I wanted to share with you what you could unlock if you share Data Tinkerer with just 1 more person.
There are 100+ resources to learn all things data (science, engineering, analysis). It includes videos, courses, projects and can be filtered by tech stack (Python, SQL, Spark and etc), skill level (Beginner, Intermediate and so on) provider name or free/paid. So if you know other people who like staying up to date on all things data, please share Data Tinkerer with them!
Now, with that out of the way, let’s get to Snap’s ML platform transformation.

TL;DR
Situation
Snap’s ML teams relied on Apache Spark for analytics but raw Spark was painful for ML workflows: spiky, iterative training data jobs, multiple data formats, scattered tooling and heavy cluster babysitting for every experiment.
Task
They needed an ML-focused data platform on top of Spark that hid infra, handled diverse formats, supported fast experimentation through to stable production and gave a single, coherent experience for Spark users.
Action
They built Prism, a unified Spark platform with a UI and SDK, config-driven Prism Templates to define jobs in YAML, a control plane with Temporal workflows for cluster lifecycle, centralised metrics, autotuning and deep integration with Snap’s billing, orchestration and lakehouse tools.
Result
Prism grew from a handful of daily jobs to several thousand per day, with peaks over 10k, cut onboarding friction, standardised patterns, improved reliability and let ML engineers focus on experiments and models instead of Spark internals and cluster management.
Use Cases
Feature engineering, batch model pipelines, lakehouse ingestion, experiment workflows
Tech Stack/Framework
Apache Spark, Apache Iceberg, Dataproc, Apache Airflow, Kubeflow, Apache Parquet, Trino
Explained further
Context
Apache Spark has been a core part of Snap’s analytical stack for a long time. It runs the pipelines that feed reports, dashboards and batch data products. For that world, Spark is a good fit.
Machine learning puts new pressure on that foundation.
ML development is inherently iterative. An engineer can spend a week trying variations of the same broad idea: a different label definition, a refined feature set, a new way to slice users, a new pre-processing recipe. Each iteration often means regenerating training data from very large raw sources. Doing that repeatedly is not a nice, predictable nightly job. It is a series of intense, sometimes spiky workloads that hit the platform whenever someone has another idea.
The development lifecycle is also more fluid. Early in a project, ML engineers want freedom. They want to pull ad hoc samples, tweak schemas on the fly, and see results quickly. Once the same model is ready for production, the expectations flip. Pipelines need to be stable, observable and efficient on real traffic. The platform has to support both modes without asking people to throw away all their early work and start again from scratch.
Then there is the question of formats. ML workloads do not live in a single file format. Snap’s teams use:
TFRecord when they are feeding TensorFlow
Protobuf when they are working with gRPC-based serving systems
JSON for lightweight exploration and simple tests
Parquet and Iceberg for analytical and lakehouse-style storage
Forcing everything through a single “blessed” format would only slow teams down. A realistic platform needs to work comfortably across all of these.
Where raw Spark started to hurt ML teams
Spark itself is not the weak link. It is powerful, battle tested and extremely good at scaling SQL and batch workloads. The problem is not capability; it is usability for ML engineers.
Without the right abstractions:
Engineers need to understand Spark internals and distributed systems just to write reasonable jobs.
They rebuild the same boilerplate, like data validation or common preprocessing across teams.
They manage clusters, dependencies, and upgrades themselves.
They spend time in Spark UI and logs chasing down failures that add no value to the model itself.
All of this is on top of their actual core stack: TensorFlow or PyTorch, notebooks, experiment tracking tools, workflow systems like Kubeflow and internal ML platforms. Spark is an ingredient they need for scale, not the centre of their role. When the support around it is thin, that ingredient becomes a constant source of overhead.
Snap’s ML engineers wanted to spend their time on experiments and models, not on reverse engineering cluster failures. That is the capability gap the team set out to close.
What Snap wanted from an ML data platform
The Snap team set a clear goal: build an ML-focused data platform on top of Spark that feels consistent, friendly, and scalable, instead of “bare-metal Spark with some helpers”.
The platform should let ML engineers:
Describe what data they need instead of hand-coding how to compute it
Iterate quickly without piles of glue code
Reuse proven, secure patterns for data processing
Spend their energy on model and product logic instead of infrastructure
That means heavy lifting in one place: infrastructure abstraction, patterns, observability, integration with Snap’s internal ecosystem for metrics, billing, cost tracking, scheduling.
With that foundation in place, ML development becomes faster and more consistent, and the platform team can invest in shared improvements instead of firefighting one-off jobs.
Boiling the problem down
So the problem is not “Spark is bad for ML”. The problem is that raw Spark is too low level for the way ML teams actually work.
What Snap’s team built with Prism is a layer on top of Spark that:
Hides cluster-level pain
Standardizes job patterns
Bakes in observability and cost awareness
Fits naturally into ML workflows rather than generic analytics
Prism is the answer built around those constraints. It keeps Spark, but wraps it in a set of tools that match how ML teams at Snap actually work.

Meet Prism: Snap’s ML data platform on Spark
Prism is Snap’s unified Spark platform. From the outside, it looks like one coherent system that handles job authoring, productionisation and post-production operations.
Instead of each team creating its own way of submitting Spark jobs and wiring up clusters, Prism offers a consistent experience. Engineers can define jobs in a configuration-driven way, work in a UI when they want a visual surface, or go through an SDK when they need more control. Underneath, the platform handles cluster lifecycle, resource management, metrics collection and cost accounting.
Prism also aims for a serverless feel. Users submit work and adjust configurations, while the system decides how to spin up clusters, scale them and shut them down. That does not remove Spark, but it changes how people interact with it.
From experiment to production: the Prism user journey
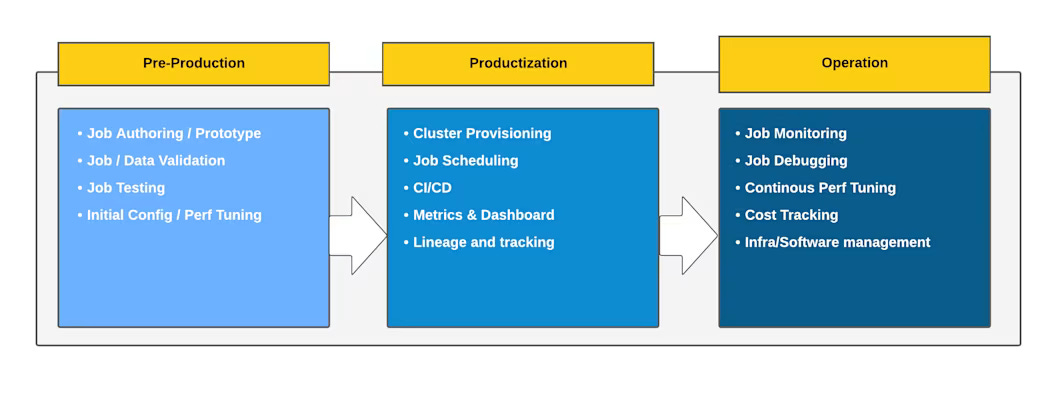
If you follow a typical workflow through Prism, you see three distinct phases.
In pre-production, engineers are experimenting. They want to get a job off the ground quickly, test logic and refine their approach. Prism supports this by offering configuration-based templates and a UI where most of the setup is already done. Predefined profiles cover common use cases which means teams are not spending their first week just tuning cluster settings.
Once a job is ready to run regularly, it enters productisation. At this point, Prism controls cluster setup, scaling and teardown through a unified API. Jobs can be tied into orchestration tools such as Airflow or Kubeflow without every team reinventing the wheel. Dashboards, metrics and metadata tracked by Prism give users a cleaner window into how their jobs behave.
Post-production, attention moves to reliability and efficiency. Prism takes on this work by centralising monitoring and alerts, storing rich metrics and offering autotuning features that can recommend or apply improvements. Job costs are tracked, and infrastructure upgrades happen at the platform layer instead of per-team.
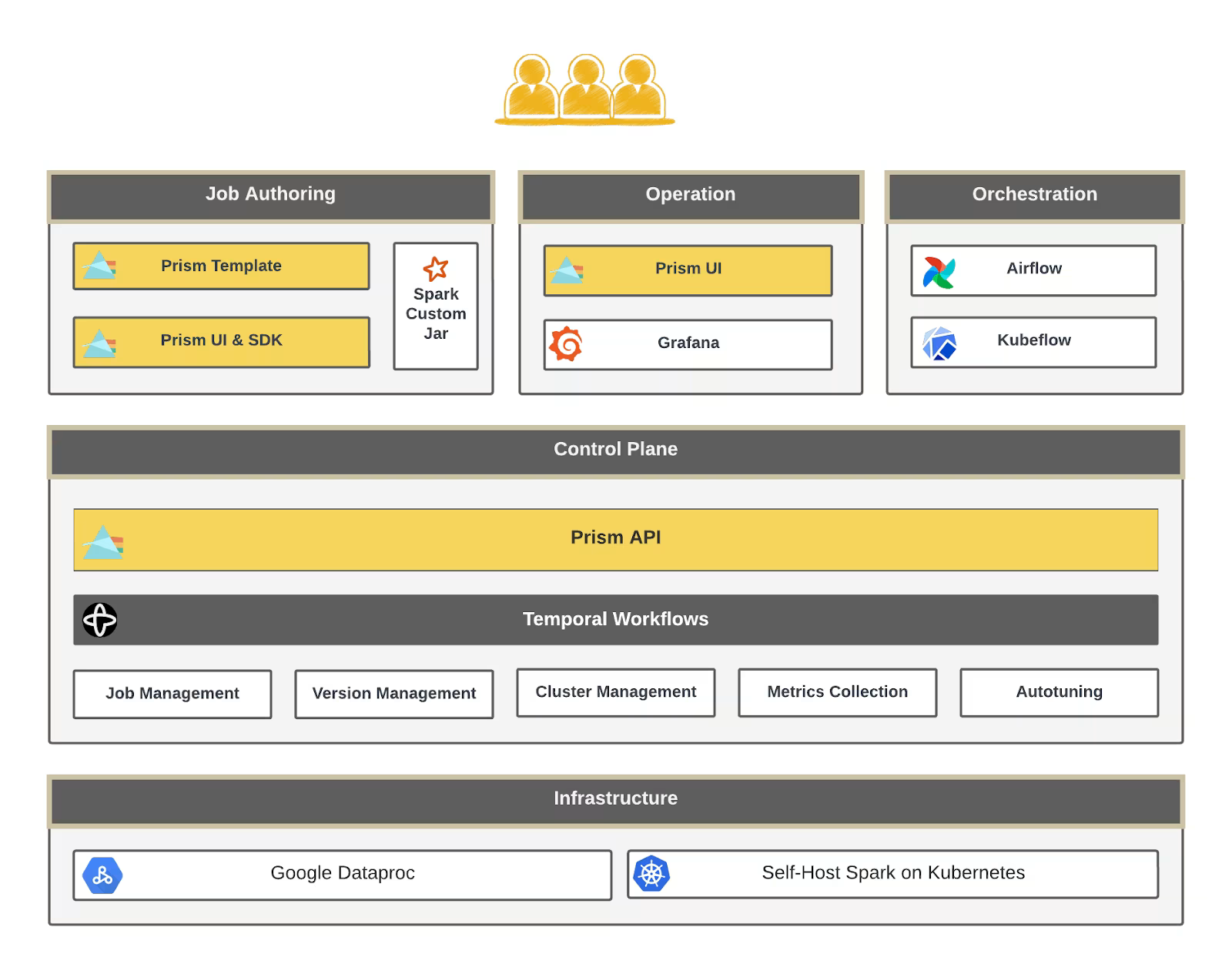
Prism architecture
Prism’s architecture is organised around two main user-facing interfaces and a set of internal systems.
For users, the first touchpoint is the Prism UI, a console where they can author jobs, inspect runs, debug failures and tune performance. The second is a client SDK that exposes Prism’s capabilities programmatically. Together, these give ML and data engineers both an interactive and an automated way to work with Spark.
Behind those sits Prism Template, a framework for composing Spark jobs out of structured, reusable blocks. Instead of asking every engineer to shape their own Spark application, Prism Template gives them a vocabulary of modules they can chain together with YAML.
All external requests hit a central API and then flow into the Prism Control Plane. This control plane is responsible for managing job metadata and configuration. It delegates orchestration work to a workflow system powered by Temporal. Temporal workflows handle cluster provisioning, job submission, retries, cancellation and similar runtime tasks.
The whole stack ties into Snap’s internal services for metrics, cost tracking and orchestration. The idea is to have one platform that understands both the Spark world and the rest of Snap’s infrastructure landscape.
A single home for Spark users: Prism UI console
Before the Prism UI, Spark users at Snap lived inside a messy toolkit. They had an infra-owned library and CLI to standardise job submission, then Spark UI and History Server to debug jobs, HDFS tooling for storage, Dataproc Console and Stackdriver for cloud-level views, and separate internal systems for metrics and cost.
Each of these tools did something useful, but taken together, they were a scattered experience. New users had to learn not only Spark, but also the map of where to click when something went wrong. Even experienced teams were wasting time stitching context together from five tabs.
The Prism UI Console was built to compress this spread. It gives Spark users a single place to search jobs, view runs, understand configuration, inspect metrics and author new work. Platform teams now have a clear surface to invest in, and engineers have one source of truth for their Spark workloads.
The result is lower friction, faster onboarding and a much clearer path for incremental usability improvements in the future.
What you can do in the Prism UI
The Prism UI is the primary surface area for Spark users at Snap. Key capabilities include:
Unified job search: A central search page lets users filter by job name, namespace, cluster ID, and other attributes. When something breaks, they no longer have to bookmark multiple systems.
Metadata storage: Job and cluster metadata, such as configurations, metrics, and lineage, are stored in a scalable backend. This supports analytics, audits, and better platform decisions.
Logical job grouping for trend analysis: Jobs are grouped by orchestration task IDs, for example from Airflow or Kubeflow. This makes it easy to look at long-term trends in runtime, cost, and resource use for a specific workflow.
Integrated real-time cost estimation: Through integration with internal billing systems, users can see cost estimates while jobs run. This is especially helpful during heavy experimentation when budgets matter.
One-click utilities and deep links: Utilities like job cloning, as well as deep links into Spark UI, logs, and output tables, make iteration and debugging faster.
Integrated job authoring: Users can
Configure sources and sinks with built-in support for Iceberg, TFRecords, Parquet, and BigQuery
Use an SQL editor with autocomplete powered by a metastore-aware schema integration
Pick preconfigured job profiles created by Spark experts
Jump directly to the Lakehouse UI for Iceberg-backed outputs and query them via Trino
Create low-code jobs using Prism Templates
This is where most ML users feel the impact. Instead of wrestling with scattered tools, they have a single console designed for how they work.
Prism templates: opinionated Spark jobs without the boilerplate
Spark’s flexibility is both a strength and a risk. The same workload can be written in very different ways which leads to wide differences in structure, resource usage and maintainability. In a large organisation, that turns into a support headache.
Prism Template is Snap’s way of putting structure on top of that flexibility. Instead of everyone writing full Spark applications, users define jobs in YAML using reusable modules and standardised patterns. The platform takes ownership of job bootstrap, configuration and core logic wiring.
This approach makes experimentation easier for ML engineers. They can assemble pipelines quickly without having to understand every detail of Spark’s internals. Later on, as jobs move toward production, teams can adjust centralised configurations and modules to scale more gracefully, without rewriting their application code.
Why templates matter in practice
The core benefits of this approach:
Simplified job authoring: Users describe jobs via a YAML file instead of writing low-level Spark boilerplate. The same definition can move from local development to staging and then production.
High-quality, reusable components: The platform ships with modules that cover tasks like:
Iceberg ingestion
Feature extraction
Sequence building and manipulation
These modules encode best practices, which reduces user errors and keeps jobs consistent.
Integrated observability and tooling: Because Prism owns the bootstrap and core modules, it can inject metrics, logging, and other operational hooks in a uniform way.
Managed versioning: Job definitions, driver JARs, and plugin JARs are versioned and managed centrally. This supports safe upgrades and stable behavior across environments.
Customisable templates: Users can start from pre-built templates, then add their own parameters or chain modules in new ways.
The example below shows a Prism Template YAML snippet that combined two modules in one job: one that builds an ordered sequence column and one that ingests the result into an Iceberg table.
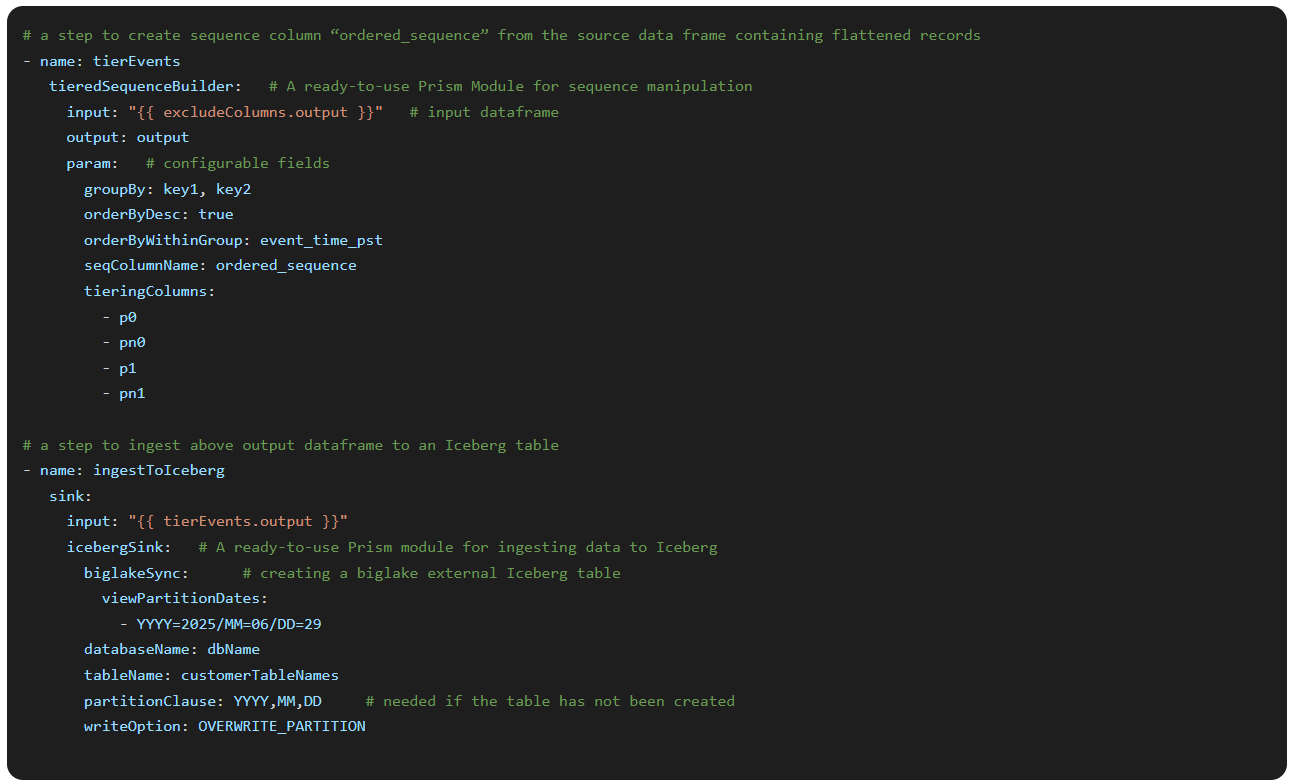
The structure is easy to read and the heavy logic lives in reusable modules.
The Prism control plane: making Spark feel serverless
The first take on a control plane at Snap was lean. It wrapped Dataproc APIs, handled some permissions and exposed separate concepts for clusters and jobs. Orchestration tools such as Airflow still had to own cluster lifecycle, including creation, reuse, teardown and failure handling.
At small scale, that model works. As usage grows, human-managed cluster lifecycle turns into a liability. Teams end up carrying subtle differences in how they handle errors and retries. Operational load rises. Reliability drops.
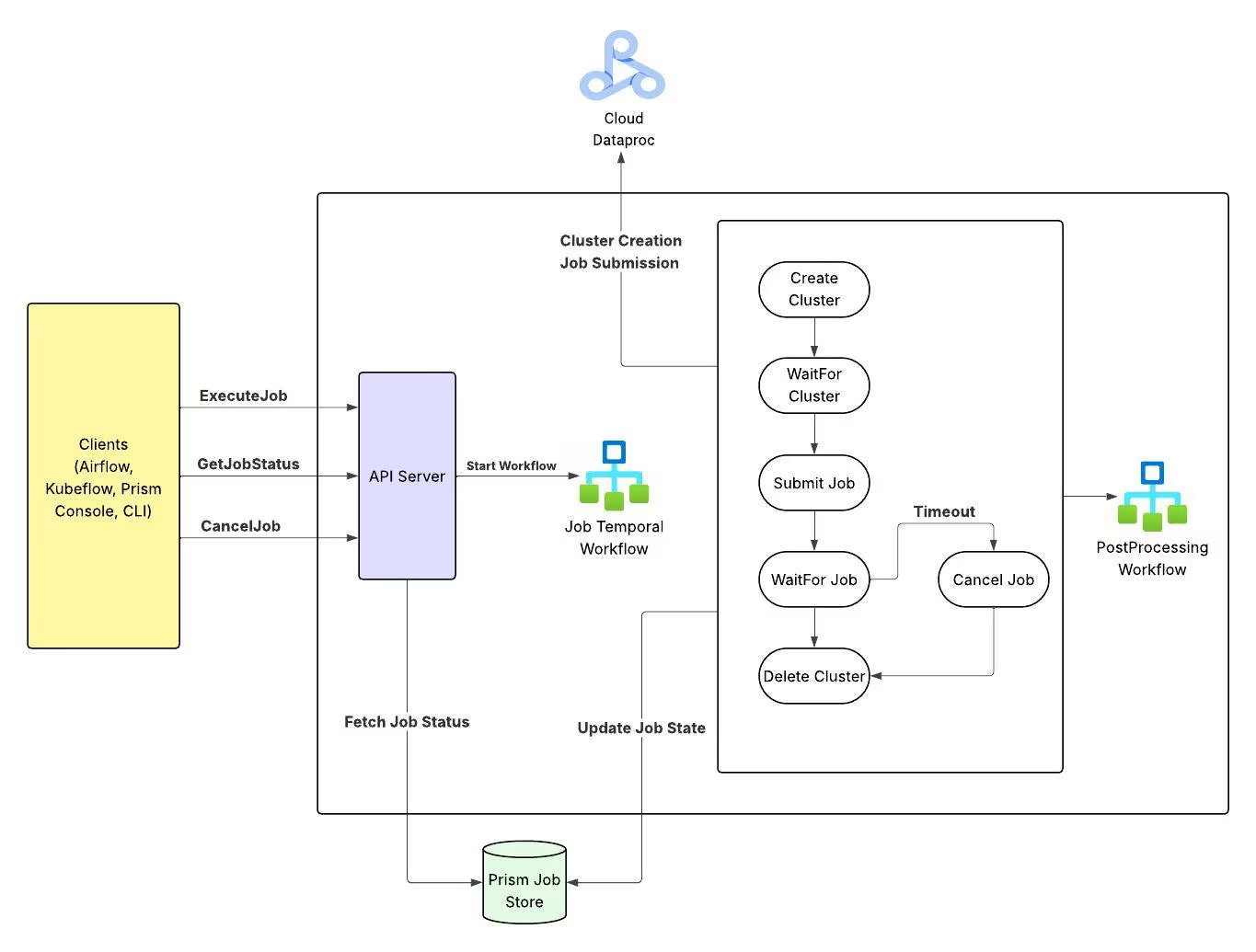
The team redesigned the control plane around a different principle: one simple job submission interface that hides cluster lifecycle.
The redesigned system:
Presents a single API endpoint for job submission
Internally handles cluster provisioning, monitoring, retries, and shutdown
Uses a workflow engine built on Temporal to orchestrate these steps
The division of responsibilities is clear:
The control plane manages metadata and configuration
Temporal workflows manage the runtime orchestration
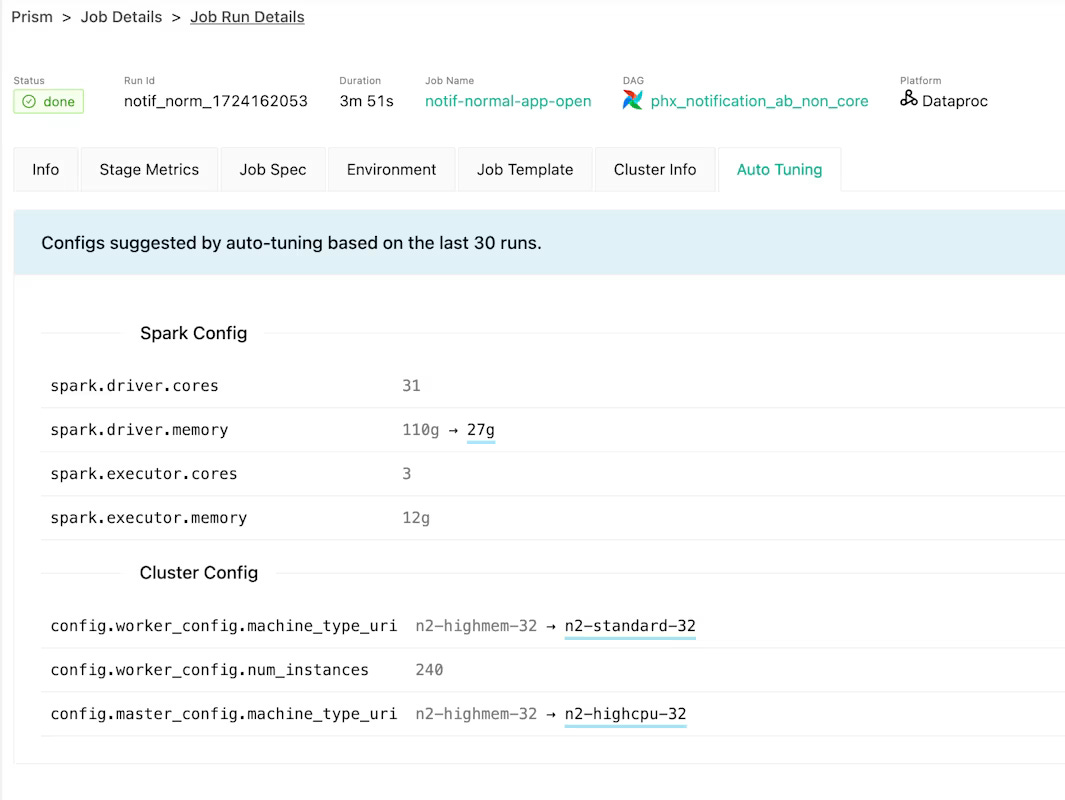
This improves reliability and reduces cognitive load for users. It also creates a base for smarter features such as autotuning and intelligent retry policies, since the platform now owns the whole lifecycle rather than just parts of it.
Metrics and autotuning: turning Spark signals into smarter defaults
Spark and Dataproc expose a large amount of metrics out of the box. The problem is not availability, it is usability.
The raw metrics:
Exist at multiple levels: job, stage, task, cluster
Are not always structured for time-series analysis
Use inconsistent naming and retention policies across sources
Are difficult to use as inputs for automation
To fix this, Snap built a dedicated metrics system for Spark workloads in Prism.
This system:
Ingests selected signals from jobs, clusters, and infrastructure
Normalizes them into a coherent schema
Stores them in a centralized Spanner database for durability and consistency
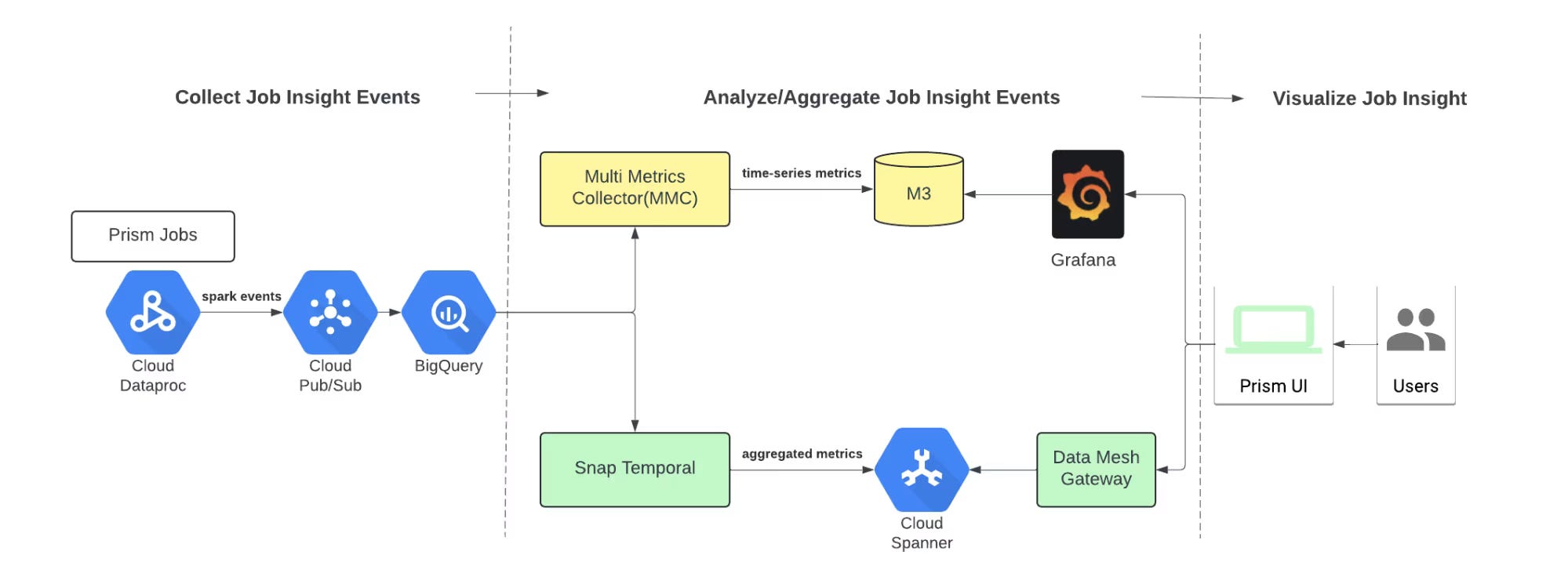
With this foundation, Prism can:
Show actionable metrics in the UI console
Back features like autoscaling and intelligent retries
Support autotuning features that adjust configuration based on observed behavior
Importantly, this metrics work was done in parallel with the UI console, so both evolved together. The result is a unified experience where what the user sees and what the automation uses come from the same underlying system.
How Prism spread across Snap
The clearest sign that a platform is working is usage. Prism’s daily job counts have climbed from single digits to several thousand per day, with peaks above 10,000 jobs.
The pattern of adoption falls into two main buckets.
Direct use by advanced Spark teams: Teams with complex Spark needs use Prism directly. Their workloads often involve:
Large joins
Tight coupling with specific data models
Custom logic that does not fit into a narrow “standard pipeline” box
These teams still get value from Prism’s abstractions and control plane, but they stay close to the underlying capabilities.
Integration into internal platforms: Other teams do not think in terms of Spark at all. They work with internal tools for:
ML data preparation
Feature engineering
Experimentation
Those tools, in turn, embed Prism. The teams’ users get domain-specific interfaces, while Prism quietly runs the heavy Spark work in the background.
Supporting both direct and embedded use is a crucial design choice. It lets Prism spread across Snap without forcing every user into the same interface or abstraction level.
The full scoop
To learn more about this, check Snapchat's Engineering Blog post on this topic
If you are already subscribed and enjoyed the article, please give it a like and/or share it others, really appreciate it 🙏