
How Uber Cut Data Lake Freshness From Hours to Minutes With Flink
Why Uber moved ingestion from Spark batch to Flink streaming and what it took to run thousands of jobs reliably at petabyte scale.

Fellow Data Tinkerers!
Today we will look at how Uber moved from batch to streaming in their data lake.
But before that, I wanted to share with you what you could unlock if you share Data Tinkerer with just 1 more person.
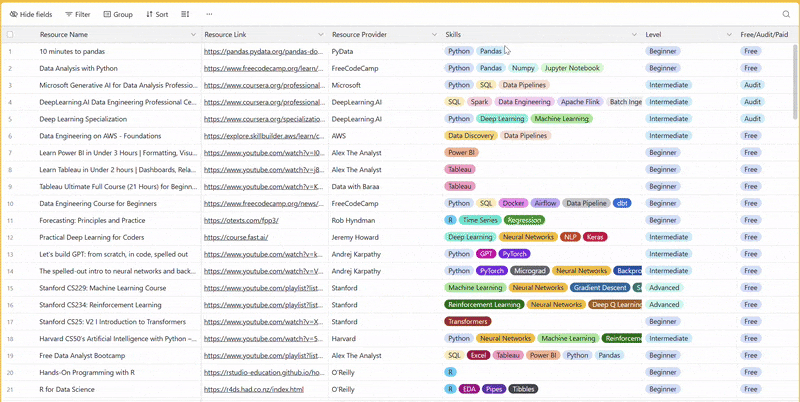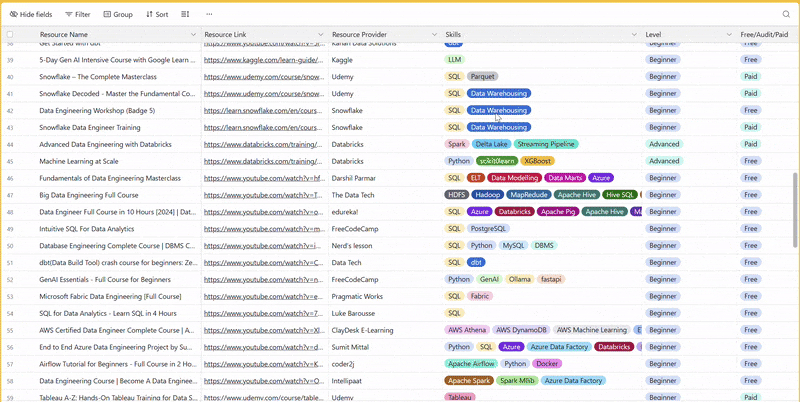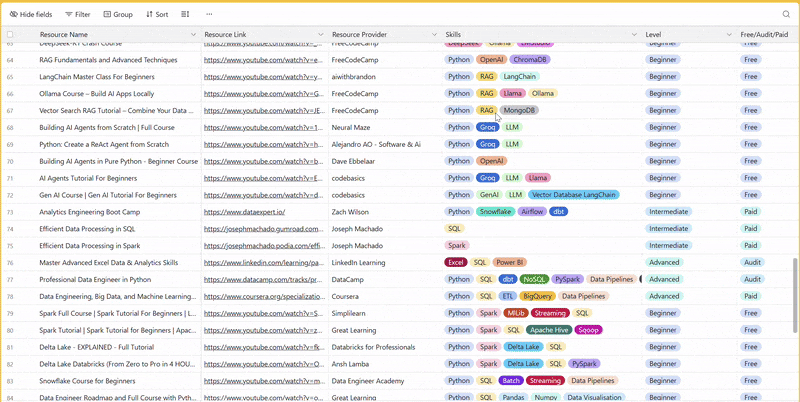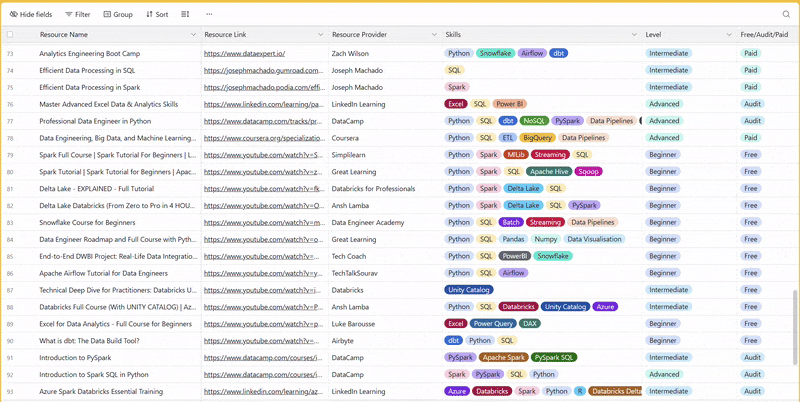
There are 100+ resources to learn all things data (science, engineering, analysis). It includes videos, courses, projects and can be filtered by tech stack (Python, SQL, Spark and etc), skill level (Beginner, Intermediate and so on) provider name or free/paid. So if you know other people who like staying up to date on all things data, please share Data Tinkerer with them!
Now, with that out of the way, let’s get to Uber’s streaming solution
