
What the Data Crowd Was Reading in July 2025
Tools, techniques and deep dives worth reading that I came across last month.

Fellow Data Tinkerers!
As I mentioned last week, I’m making a few changes to the newsletter based on your feedback. Here’s what’s new:
1- Data roundup: I’m trialing a new format that focuses more on deep dives, practical how-tos, and longer-form content to help you sharpen your craft. Less hype about the latest model, more substance. Each month, I’ll share a curated roundup of the most useful pieces I’ve come across in AI and data across data science, data engineering and data analysis.
So: less news, more depth.
2- Referral prizes: I’m changing the referral prizes to:
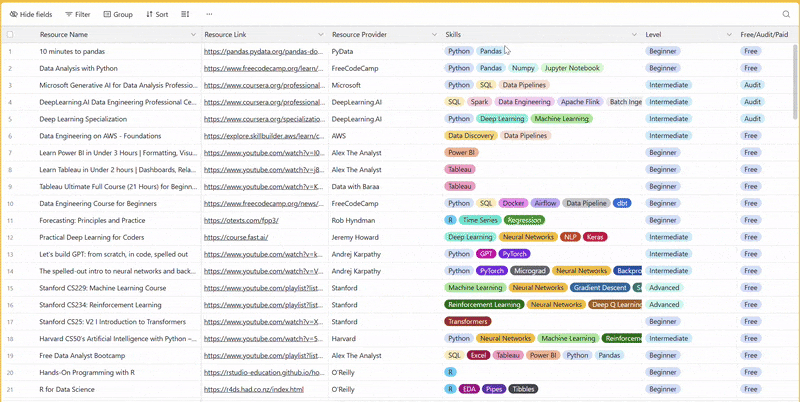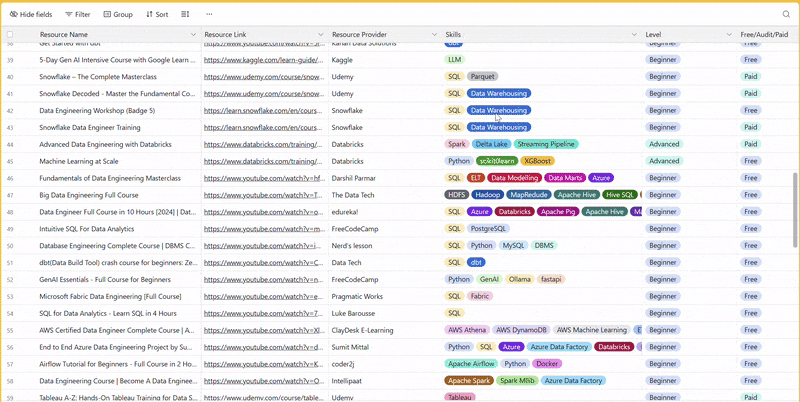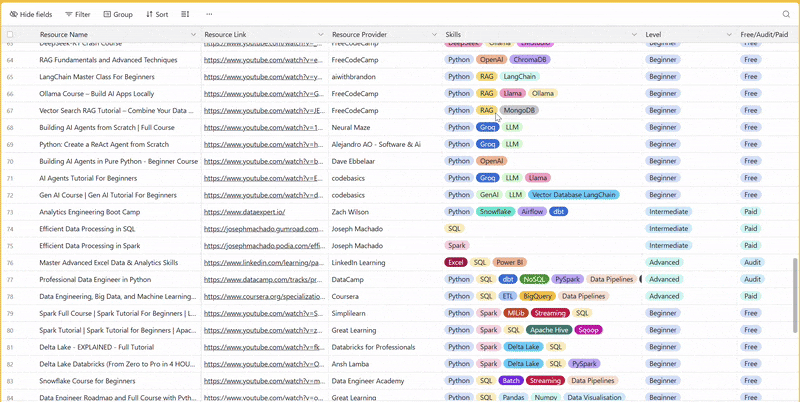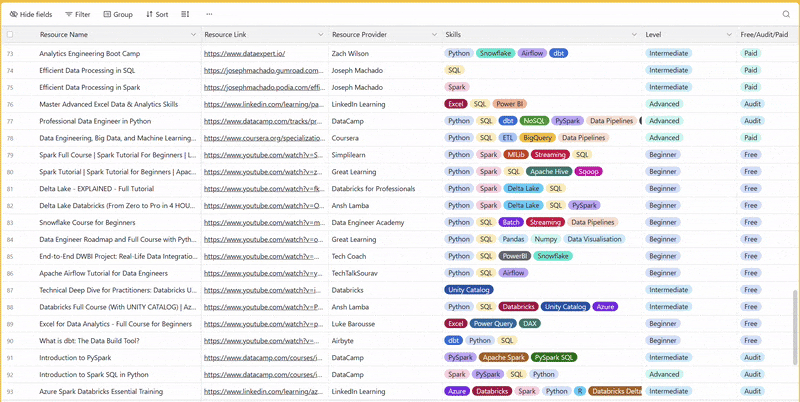
1 share - 100+ resources to learn all things data (science, engineering, analysis). It includes videos, courses, projects and can be filtered by skill, level or free/paid
2 shares - 100+ cheatsheets for all things data (science, engineering, analysis)
