
How Grab Shrunk Real-Time Queries from 5 Minutes to 1 with FlinkSQL and Kafka
With SQL as the interface, analysts and engineers can now explore streams and deploy pipelines in under 10 minutes.

Fellow Data Tinkerers!
Today we will look at how Grab made real-time processing faster for its users.
But before that, I wanted to share with you what you could unlock if you share Data Tinkerer with just 1 more person.
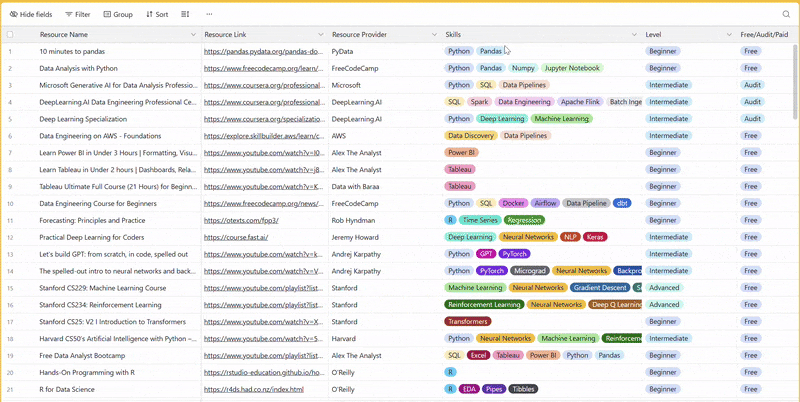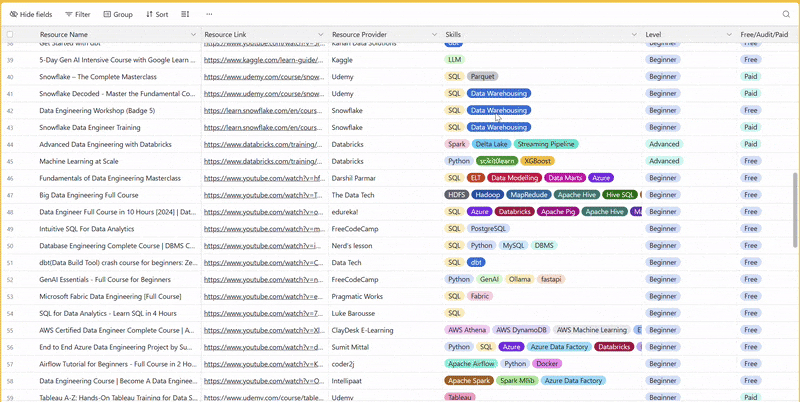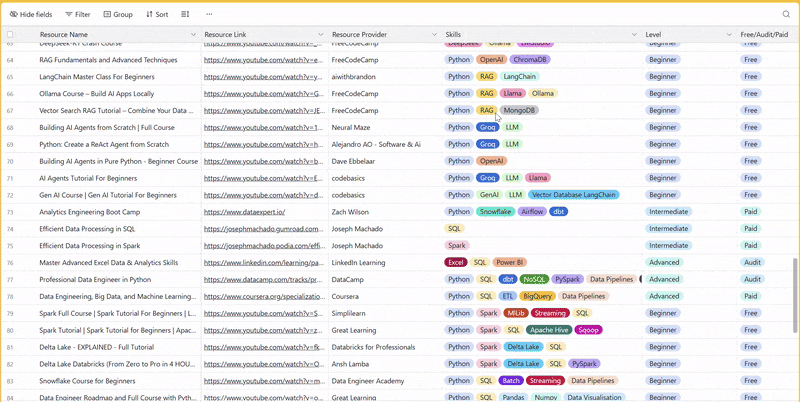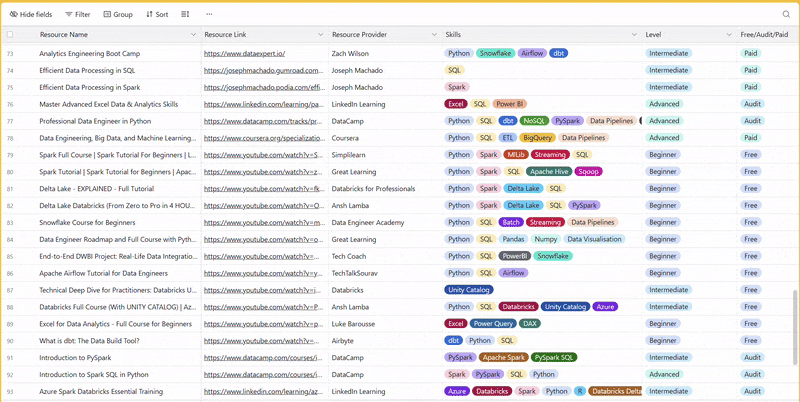
There are 100+ resources to learn all things data (science, engineering, analysis). It includes videos, courses, projects and can be filtered by tech stack (Python, SQL, Spark and etc), skill level (Beginner, Intermediate and so on) provider name or free/paid. So if you know other people who like staying up to date on all things data, please share Data Tinkerer with them!
Now, with that out of the way, let’s get to real-time processing at Grab!

TL;DR
Situation
Grab’s early attempt at stream exploration used Zeppelin notebooks on Flink. It worked for single users but had major issues: version drift, 5-minute cold starts and poor integration with other platforms. Adoption stalled.
Task
Build a shared, low-latency, and production-ready way for analysts, engineers, and internal platforms to query and deploy Flink pipelines in real time without the friction of isolated notebooks.
Action
Replaced per-user Zeppelin clusters with a shared FlinkSQL gateway.
Added an integration layer: custom control plane + REST APIs handling auth, orchestration and B2B headless queries.
Built a query layer: SQL editor + Hive Metastore mapping Kafka topics to tables for easy querying.
Enabled productionisation: users express stream logic as SQL, configure connectors, set resources, and deploy pipelines in ~10 minutes.
Result
Adoption rose: more interactive queries, more production pipelines created.
Real-time use cases unlocked across fraud detection, model validation, and event debugging.
Lower barrier to entry for analysts and developers.
Use Cases
Fraud detection, model validation, event streaming, message validation
Tech Stack/Framework
Apache Flink, Hive Metastore, Apache Kafka, SQL
Explained further
About Grab
Grab is often called the Uber of Southeast Asia but that might be selling it short. What started as a ride-hailing app now powers food delivery, groceries, payments and even insurance all bundled into one super app. They run across over 800 cities in 8 Southeast Asian countries. Behind the rides, meals, and payments lies an enormous stream of events flowing through Grab’s systems.
Background
For a company with Grab’s scale, real-time processing is table-stakes. Apache Flink earned its reputation by handling streams with state, time and scale. The Grab team leaned into that and built an interactive FlinkSQL setup that covers the whole path from exploration to production. The goals were clear: speed up the first result, make upgrades less painful and let more people touch streaming data without needing to learn the guts of Flink.
This article walks through that journey. It starts with a notebook-first world, runs into the wall you’d expect, swaps in a shared FlinkSQL gateway then layers on an API, an interactive UI and a configuration-driven way to ship streaming SQL to production. The net effect is lower time-to-insight, fewer moving parts for users and less friction when the Flink team bumps versions.
The Zeppelin days
Last year the team introduced Zeppelin notebooks for Flink. That work was aimed at downstream users who wanted to explore data quickly. But as use cases matured, a few issues started showing up:
Version drift headaches
Zeppelin is maintained by a community that isn’t the Flink community. At the time of writing, Zeppelin supported Flink 1.17 while Flink itself was already at 1.20. That mismatch made upgrades awkward. Every version gap turns into glue code, testing and the sort of workaround nobody enjoys maintaining.
The cold start problem
The design spun up a Zeppelin cluster per user on demand. Cold starts took around five minutes before a notebook was usable. That’s a non-starter for teams who need quick reads on production streams. Unsurprisingly, uptake lagged.
Integration issues
Zeppelin worked fine for a solo developer. It didn’t play as nicely with other internal platforms. Dashboards and automated pipelines needed a way to pull aggregates out of Kafka without copy-pasting code or exporting data manually. The notebook lived off to the side which meant people needed a workaround every time they wanted to reuse results or plug the flow into existing tools. Even something as basic as sending real-time metrics into a monitoring system wasn’t seamless.
Enter FlinkSQL interactive
The team replaced the per-user Zeppelin clusters with a shared FlinkSQL gateway cluster. They trimmed features they didn’t need and kept what mattered for data access and collaboration. The architecture is split into three layers:
Compute layer
Integration layer
Query layer
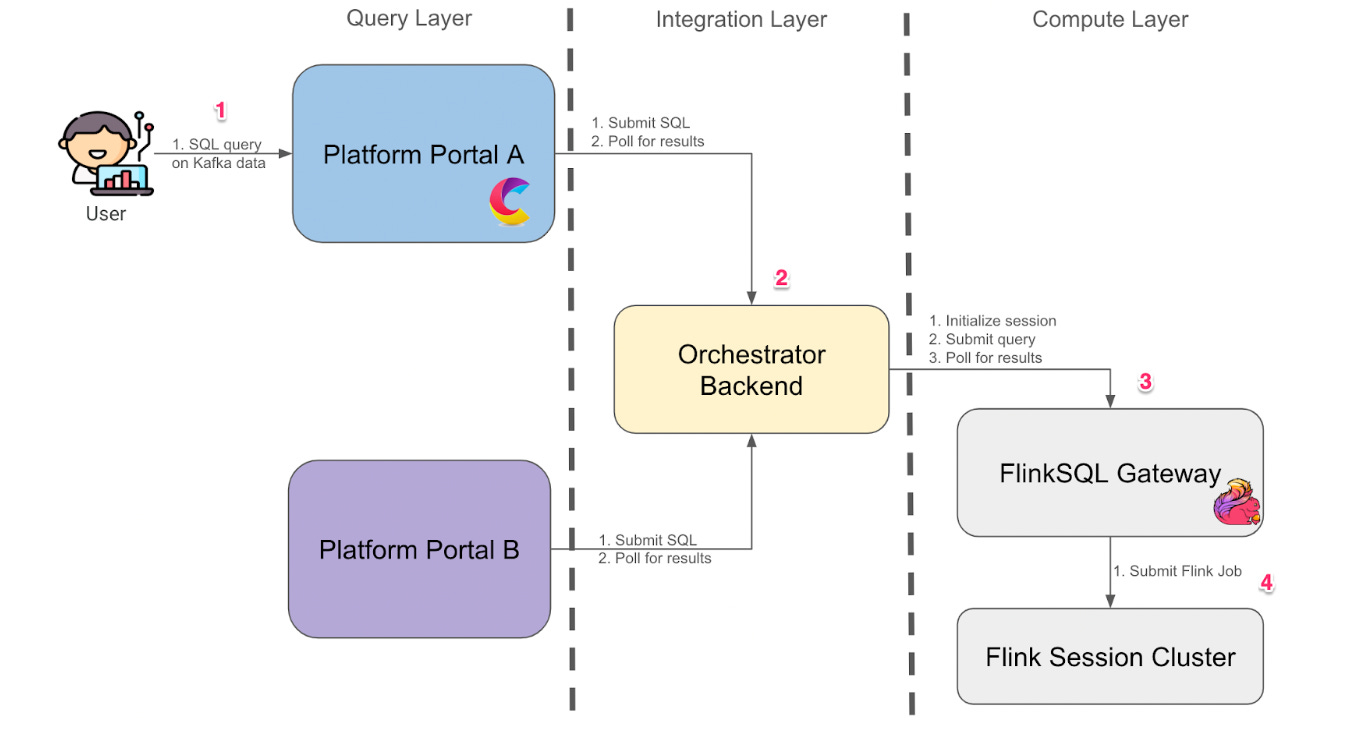
The flow is relatively straightforward:
A user opens the platform portal and submits a SQL query against data in the Kafka online store
The backend orchestrator creates a session
and submits the SQL to the FlinkSQL gateway through its REST API
The gateway packages the SQL into a Flink job and submits it to a Flink session cluster. Results are polled and streamed back to the query layer.
Now let’s get to each of the layers.
Compute layer
With the FlinkSQL gateway as the compute engine for ad-hoc queries, upgrades got easier. The gateway ships with the main Flink distribution, so the team doesn’t have to maintain shims between a Zeppelin cluster and the Flink cluster. One fewer custom adapter is one fewer source of drift.
Cold starts also dropped. Instead of booting a fresh Notebook world per user, everyone shares the same FlinkSQL cluster. No cluster boot during session init means the time to first results fell from roughly five minutes to about one minute. There’s still a small delay since task managers are provisioned on demand to balance availability with cost but the order-of-magnitude improvement is what users feel.
Integration layer
The integration layer is the glue. It sits between the user-facing query layer and the compute layer, handling session lifecycle, authentication, authorisation and orchestration across internal platforms.
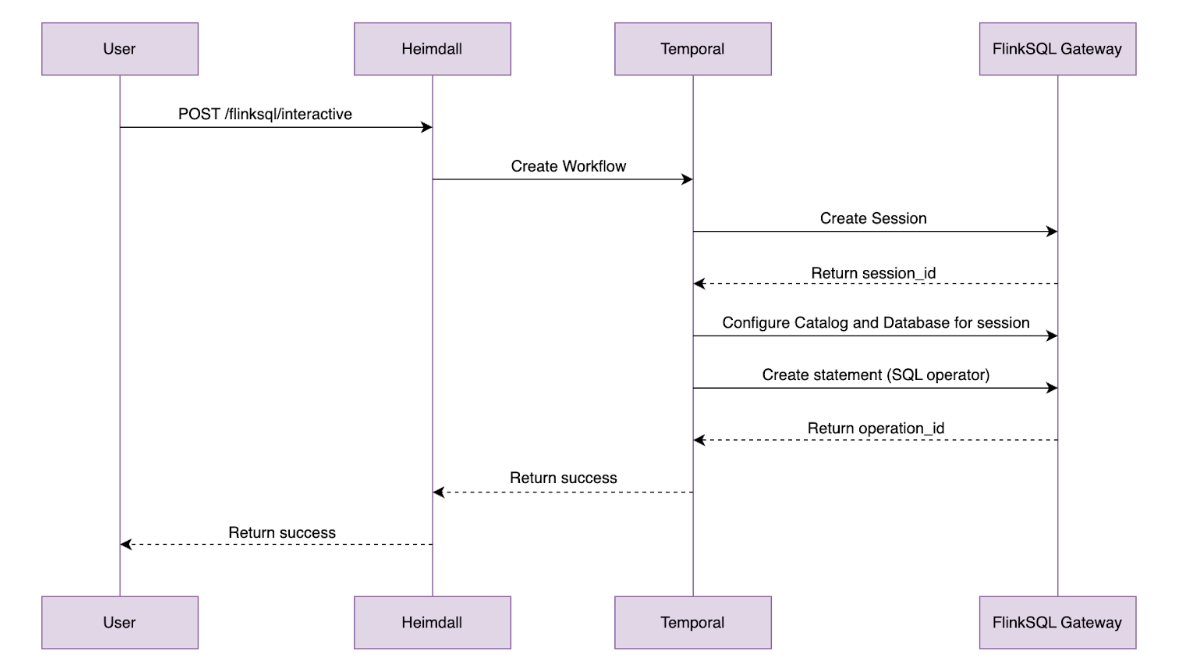
The FlinkSQL gateway has a REST API which is useful for basic submission but the pattern required multiple POSTs to do anything nontrivial, including fetching results. To smooth that out, the team added a custom control plane with its own REST APIs on top of the gateway.
This control plane integrates with in-house auth systems. Each query is authenticated, a lightweight session is created and the plane manages communication with the Flink Session Cluster.
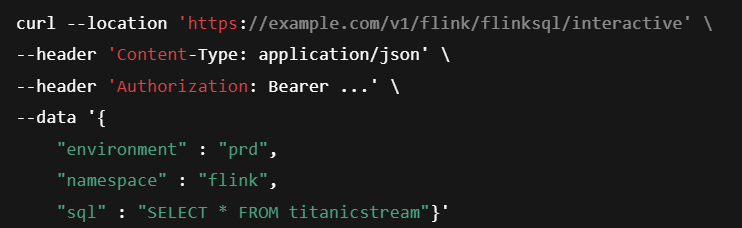
The integration layer also supports B2B needs with Headless APIs. Programs can POST a SQL query, receive an operation ID then use GET requests to receive paginated results for an unbounded query. That pattern lets internal platforms tap Kafka programmatically without learning Flink’s native interface. It’s a small thing that removes a lot of friction.
Query layer
APIs are great. Humans still like a screen. The team paired those APIs with an interactive UI that serves human workflows end to end.
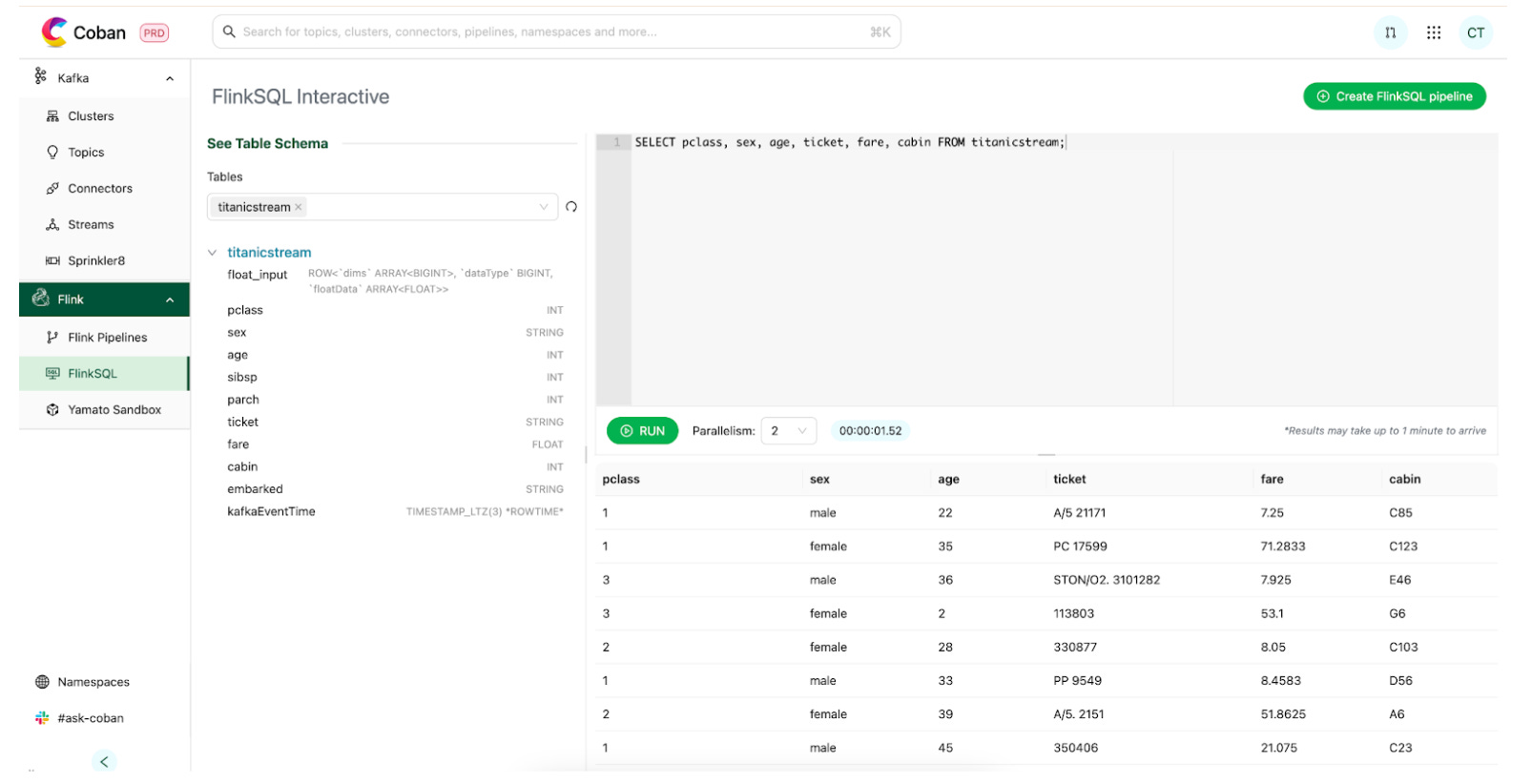
Users land in a clean SQL editor inside the platform portal. A Hive Metastore catalog maps Kafka topics to tables, so analysts don’t need to decode stream internals. Pick a table, write SQL, hit run. The integration layer routes the query through the control plane to the gateway. Results show up in the UI within about a minute which is a very different experience from waiting out a five-minute cold start.
The flow is straightforward. Here’s an example query that pulls a simple sanity check on a stream most folks recognise:
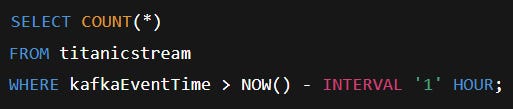
That setup unlocked common cases across teams:
Fraud analysts debug and spot patterns in suspect transactions in real time
Data scientists pull live signals to validate model behavior
Engineers confirm messages are structured correctly and delivered as expected
The key is that all three groups share the same mental model. Kafka topics look like tables. SQL does the heavy lifting. The UI stays out of the way.
From exploration to production
Exploration is good. You still need a way to ship. As more teams built on the online store and used the interactive tools to design pipelines expressed as SQL, the last mile became the next focus. The team built a way to create configuration-based stream processing pipelines with business logic expressed in a SQL statement.
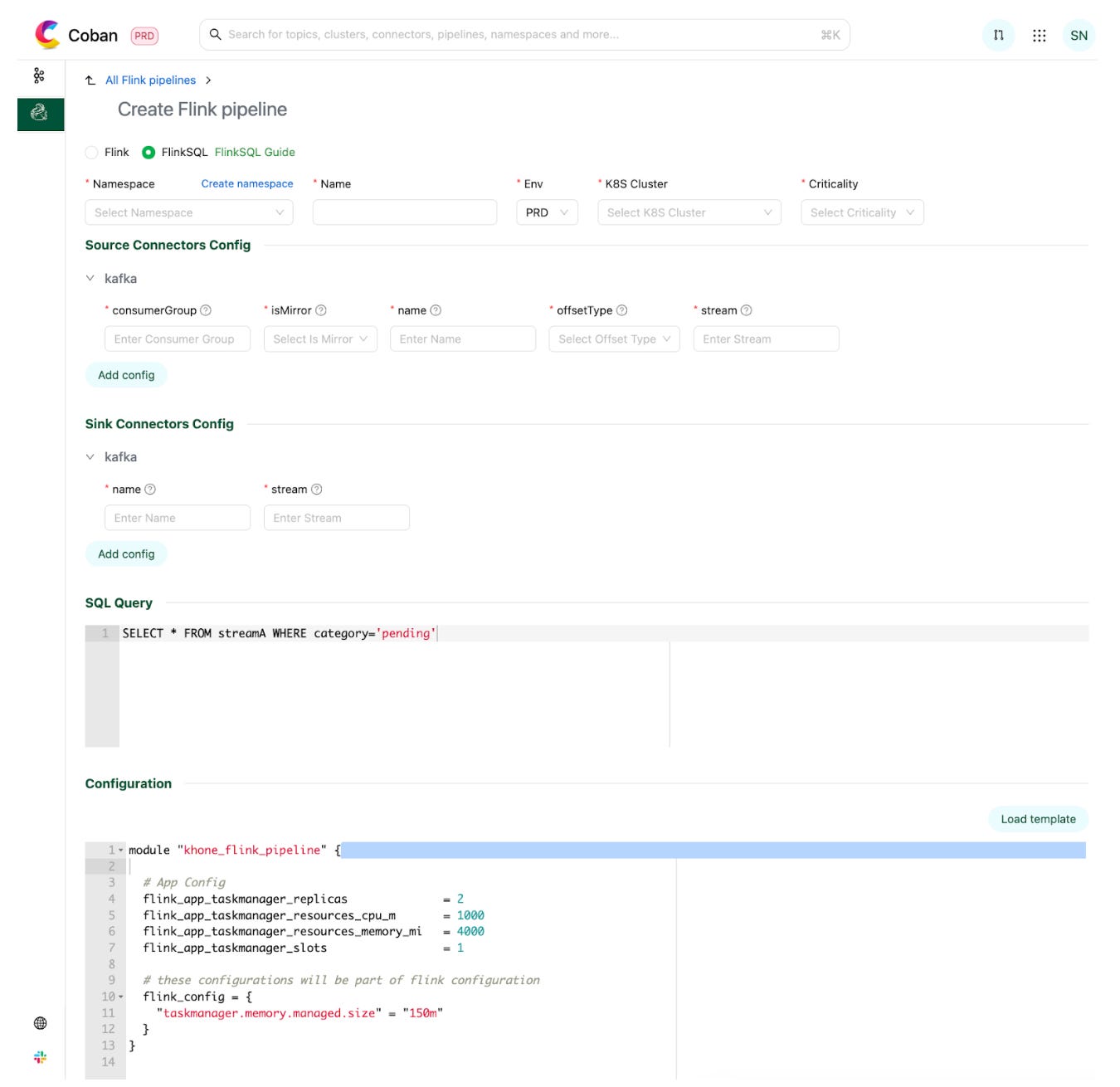
There’s a portal for pipeline creation. Connectors are hosted for internal platforms like Kafka and feature stores. Users can pick what they need off the shelf, set configuration and deploy their streaming pipeline. The logic itself is a SQL statement. The example in the diagram is a simple filter on a Kafka stream with the filtered events written to a separate Kafka stream.
Users can define the parallelism and the resources for their Flink jobs. On submission, resources are provisioned and the pipeline is deployed. Behind the scenes, the platform manages the application JAR that parses the configuration and translates it into a Flink job graph which gets submitted to the cluster. The moving parts are hidden, which is the kindest thing you can do for your colleagues.
From start to finish, a user can deploy a stream processing pipeline to production in roughly ten minutes.
Why the approach works
Nothing here depends on a silver bullet. It’s the sum of cleaner defaults.
Shared gateway reduces cold starts and cuts version drift
Control plane wraps the gateway in APIs that match real workflows
Headless endpoints let other platforms query streams without glue code
Interactive UI makes SQL on Kafka feel like SQL on any other table
Config-driven deploys turn a working query into a production job without hand-rolling jars per team
Every step makes the system easier to touch, which draws in more users. Once the path from idea to production is short enough, people walk it.
The impact after release
After the release, the team saw an uptick in pipelines created and more interactive queries. That’s the outcome you want. More pipelines mean more use cases moved from we should to we did. More interactive queries mean people are actually using the thing when they need real-time answers.
The tradeoffs
The team removed some of what notebooks offered and focused on features that push data access to more people. That means a shared control plane and a gateway, not a personal compute island per user. In return, teams get faster first results, easier upgrades, and a route to production that matches how they already think about SQL.
Key takeaways
With a shared FlinkSQL gateway, a control plane that fits real workflows, an interactive UI and a configuration-driven deployment path, the team simplified how people work with streaming data.
The changes cut time to first result from about five minutes to about one minute, reduced the pain of version upgrades, and gave both humans and systems a clean way to query Kafka.
For users who just need an answer, the UI makes it feel like querying any other table. For developers and internal platforms, the headless APIs keep the loop tight. When a query deserves to live in production, the pipeline portal turns that SQL into a running job within ten minutes.
The full scoop
To learn more about this, check Grab's Engineering Blog post on this topic
If you are already subscribed and enjoyed the article, please give it a like and/or share it others, really appreciate it 🙏
Keep learning
How Expedia Monitors 1000+ A/B Tests in Real Time with Flink and Kafka

Expedia had a problem: bad A/B tests were slipping through the cracks in the first 24 hours and hurting revenue. So they built a real-time circuit breaker using to monitor 1,000+ experiments.
If you want to learn how it works and what makes it tricky, check out this article!
How Bolt Reconciles €2B in Revenue Using Airflow, Spark and dbt

Bolt processes billions in payments across 45+ countries, but their reconciliation system doesn’t rely on magic (or prayers). It runs on batch jobs, Delta tables and smart modelling choices.
If you're into financial data engineering, this one’s worth your time.