
What the Data Crowd Was Reading in February 2026
Tools, techniques and deep dives worth reading that I came across in February 2026.

Fellow Data Tinkerers
It’s time for another round-up on all things data and AI!
But before that, I wanted to share with you what you could unlock if you share Data Tinkerer with just 1 more person.
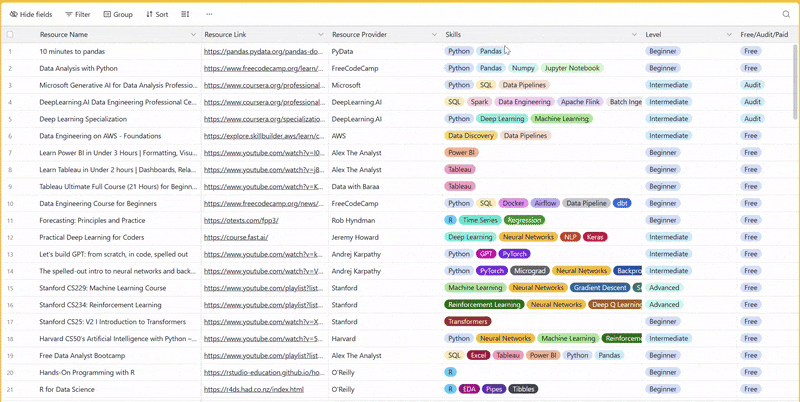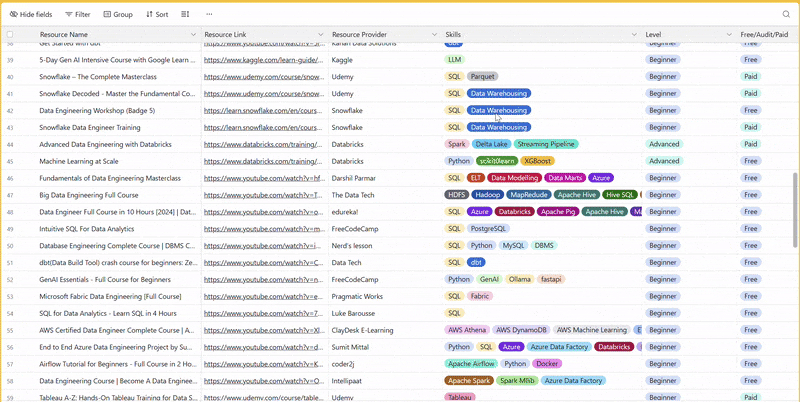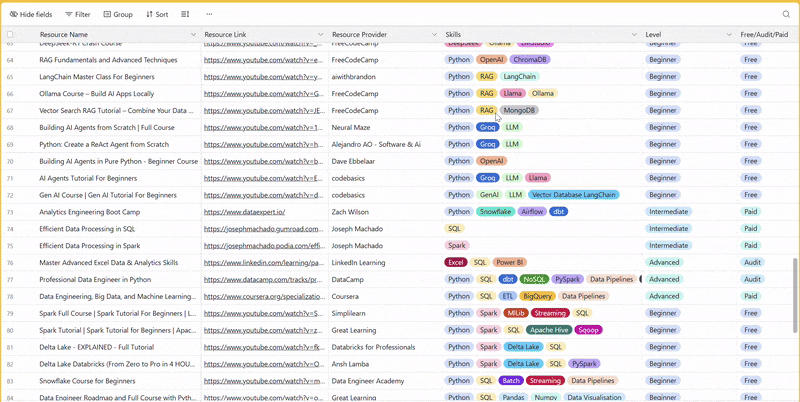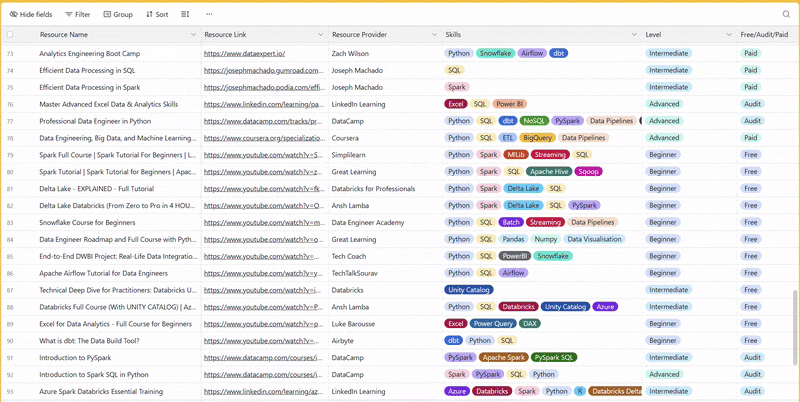
There are 100+ resources to learn all things data (science, engineering, analysis). It includes videos, courses, projects and can be filtered by tech stack (Python, SQL, Spark and etc), skill level (Beginner, Intermediate and so on) provider name or free/paid. So if you know other people who like staying up to date on all things data, please share Data Tinkerer with them!
Without further ado, let’s get to the round up for February!
Data science & AI
Inside OpenAI’s in-house data agent (14 minute read)
OpenAI explains how its in-house data agent combines rich internal context, live querying and self-learning memory to help employees go from vague business questions to trustworthy analysis in minutes.A Guide to Which AI to Use in the Agentic Era (17 minute read)
Ethan Mollick breaks down the current AI tool landscape into a simple question: which model is best for this specific task, not which one wins the internet on any given day.Judgment isn’t uniquely human (19 minute read)
Steven Adler argues judgment and taste are not uniquely human, and that treating them as off-limits to AI is another case of people underestimating how quickly models can learn high-level cognitive tasks.
I spent $10,000 to automate my research at OpenAI with Codex (6 minute read)
A researcher from OpenAI argues that people still underestimate what Codex can do in real workflows, sharing a high-usage setup and the practical lessons from using it at serious scale.Semantic Linking: the Aboutness of Data (12 minute read)
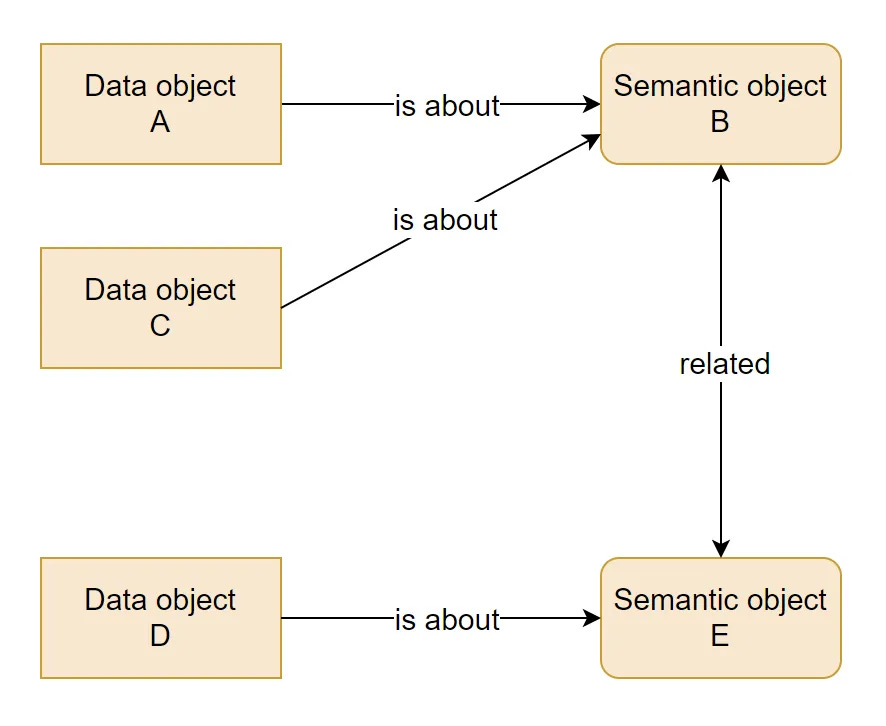
Juha Korpela expalins that semantic linking is the missing connection between data and meaning, where the real job is not adding labels to tables but explicitly mapping data objects to shared business concepts.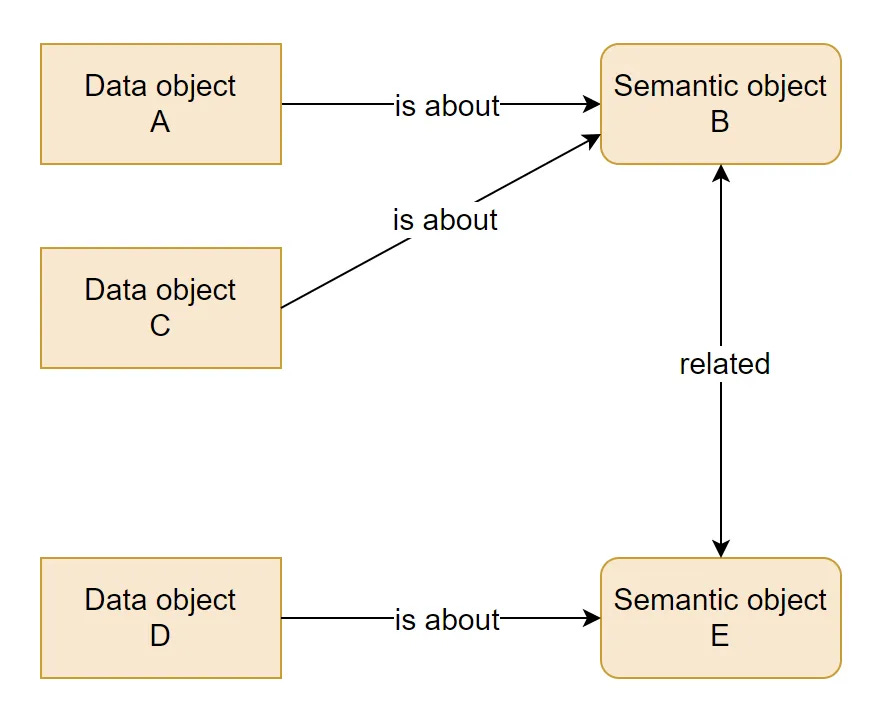
AI Is Finally Eating Software’s Total Market: Here’s What’s Next (11 minute read)
Vin Vashishta argues that AI won’t just disrupt software products, it will collapse whole layers of software value unless companies control the workflow, the customer relationship or the data moat.World Models and the Data Problem in Robotics (13 minute read)
Nvidia researcher makes the case that robotics hits a data wall long before an algorithm wall and that world models learned from human first-person video are the most plausible route to scalable robot intelligence.Lessons learned from scaling data scientists with AI (10 minute read)
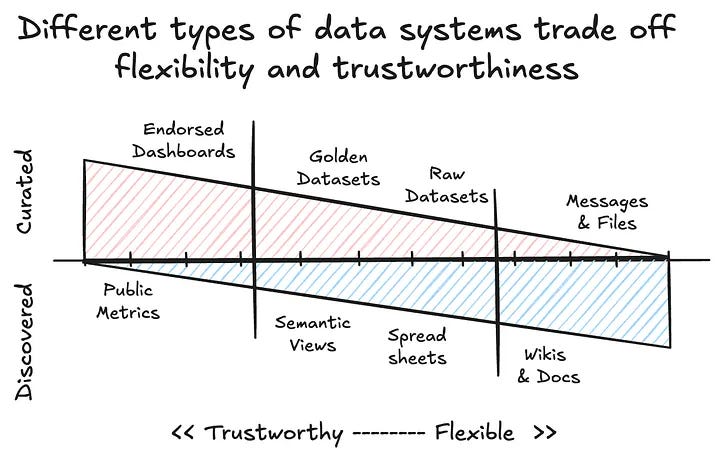
Whatnot’s lesson from deploying AI for data science is that LLMs don’t remove the need for data scientists, they force teams to get serious about semantic layers and production-grade context management.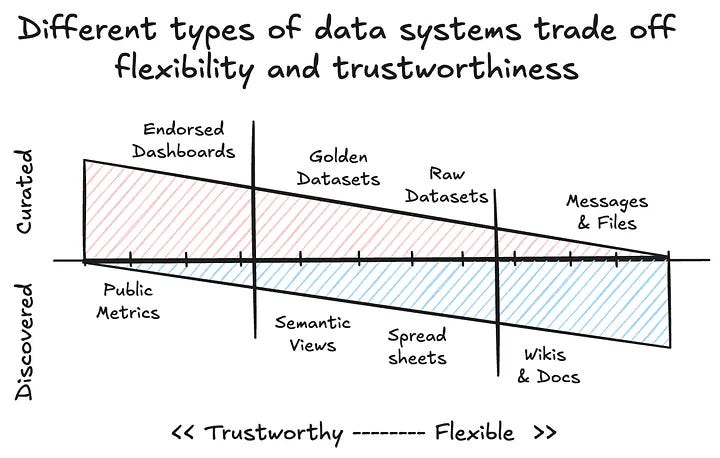
How Shopify Scales Taxonomy Evolution Across 10,000+ Categories With Multi-Agent AI (14 minute read)
This piece breaks down how Shopify moved from reactive manual updates to a multi-agent system that scans taxonomy branches in parallel, proposes new categories/attributes from merchant data, detects duplicates and runs automated QA through domain-specific judges.

Data engineering
A Portable Analytics Stack (13 minute read)
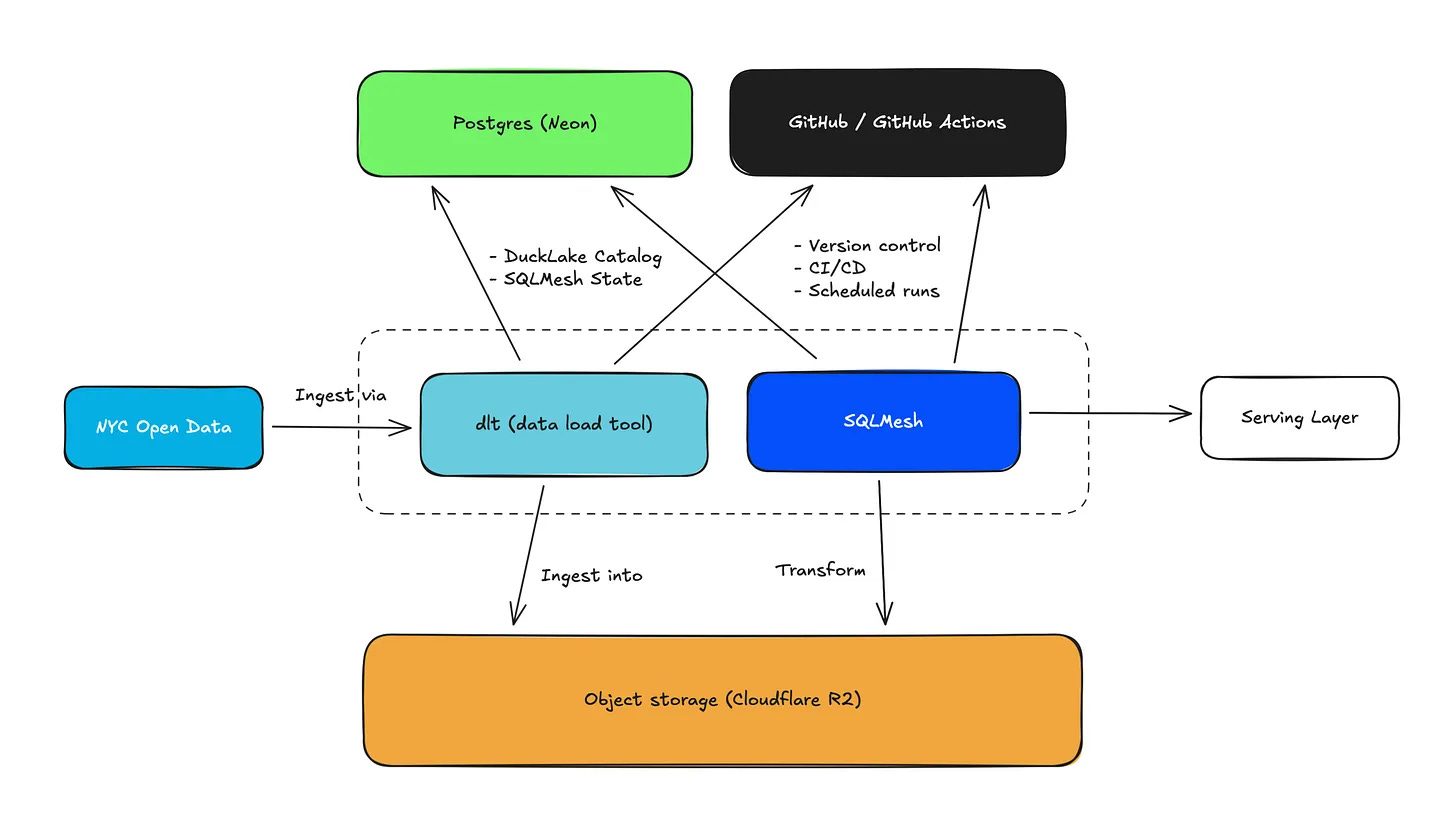
Yuki shows how a portable analytics stack built on DuckDB, DuckLake, dlt and SQLMesh can replace warehouse-heavy setups with lightweight, version-controlled pipelines that run locally or on cheap scheduled compute.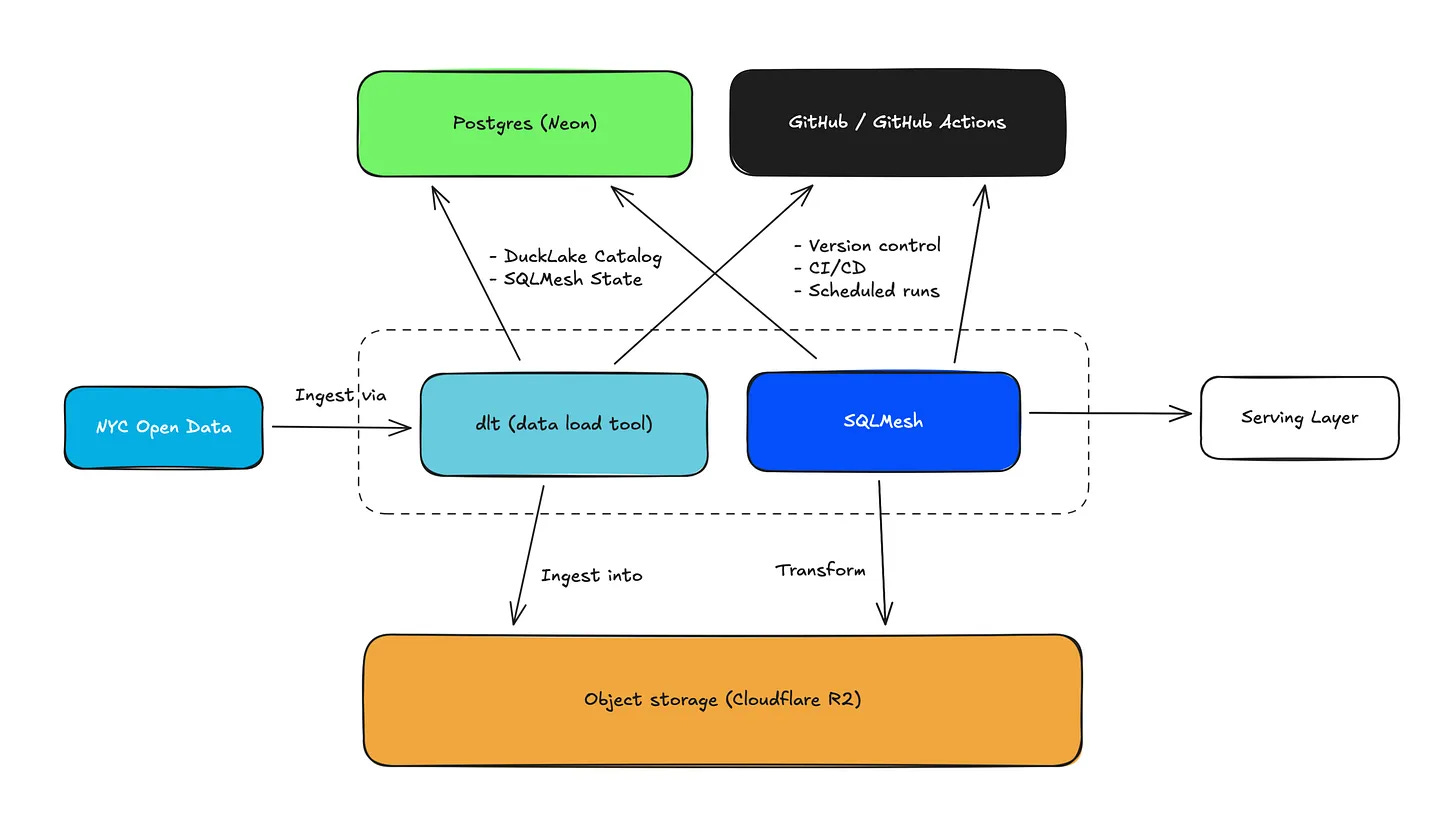
Healing Tables: When Day-by-Day Backfills Become a Slow-Motion Disaster (24 minute read)
Chris Hillman shows why incremental historical backfills corrupt dimensions and proposes a healing table pattern that separates change detection from period building so history can be rebuilt cleanly.2028 - THE GREAT DATA RECKONING (16 minute read)
A speculative but funny take by Joe Reis where he imagines a 2028 data industry shakeout where AI wipes out much of the tooling and data theater while the people who survive are the ones with real business context and architecture skills.Data Engineers Are Becoming MetadataOps Engineers (10 minute read)
An interesting take by Alejandro Aboy that the next layer of data engineering is MetadataOps: building AI-ready metadata, semantic structure and agent-facing governance so LLMs stop guessing and start using data reliably.
How Data Engineers Can Leverage AI Tools Without Losing Fundamentals (13 minute read)
Jenny Ouyang makes the case that data engineers should use AI to accelerate the boilerplate, not outsource the fundamentals because the real leverage still comes from owning modeling, architecture and performanceBackfills - The Necessary Evil of Data Engineering (12 minute read)
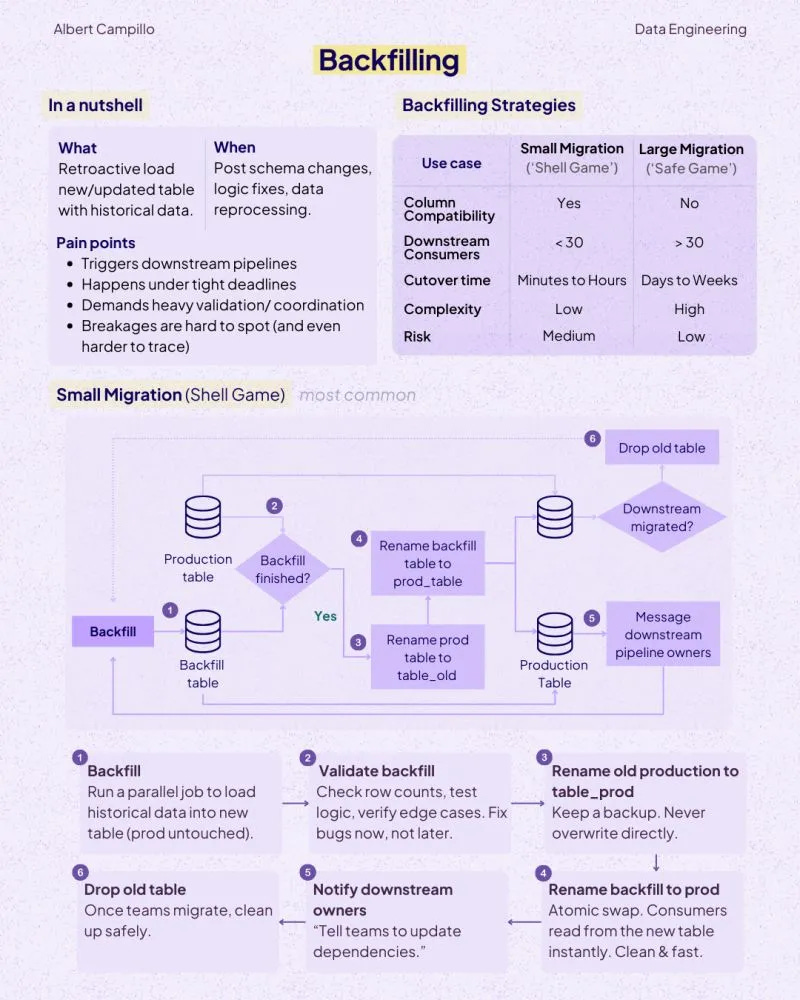
A practical look by SeattleDataGuy at why backfills happen, why engineers hate them, and how better parameterization, rerunnability, and storage-aware design can make them less painful.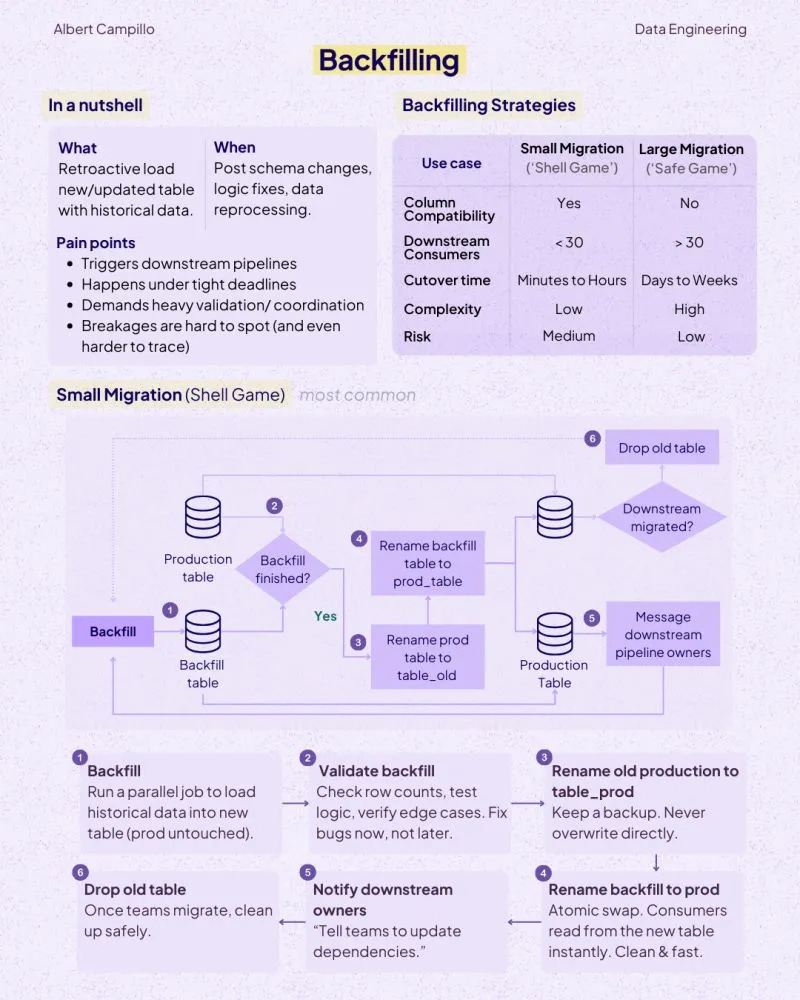
Why Your 5-Second BigQuery Query Isn’t Cheap (13 minute read)
A practical breakdown of BigQuery pricing by luminousmen that shows why short query runtimes are a misleading proxy for cost, and why slots are the compute metric that actually matters.How LinkedIn Built a Pipeline That Scales to 230M Records/sec Without Breaking SLAs (12 minute read)
LinkedIn pushed Venice to handle 175M+ lookups per second while ingesting 230M writes per second. This piece breaks down how they balanced compaction, CPU bottlenecks and adaptive throttling to scale ingestion under eventual consistency.

Data analysis and visualisation
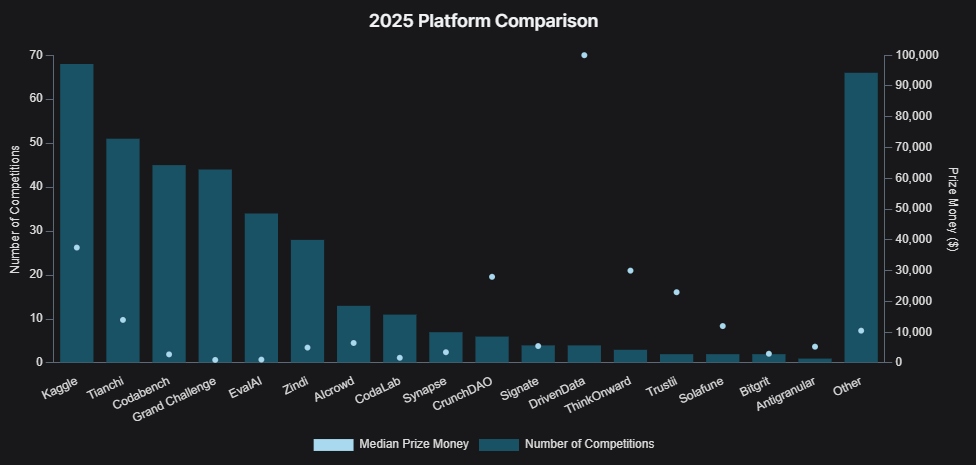
The State of Machine Learning Competitions (34 minute read)
This report maps the 2025 competition landscape and finds that winning solutions are getting more compute-hungry, transformer-heavy and increasingly shaped by Qwen in NLP while classic tabular methods still hold their ground.
Other interesting reads
AI Doesn’t Reduce Work - It Intensifies It (9 minute read)
Interesting findings in HBR that AI doesn’t really remove work so much as intensify it, speeding up expectations and raising the risk of burnout instead of delivering the productivity gains companies hoped for.The Anthropic Hive Mind (21 minute read)
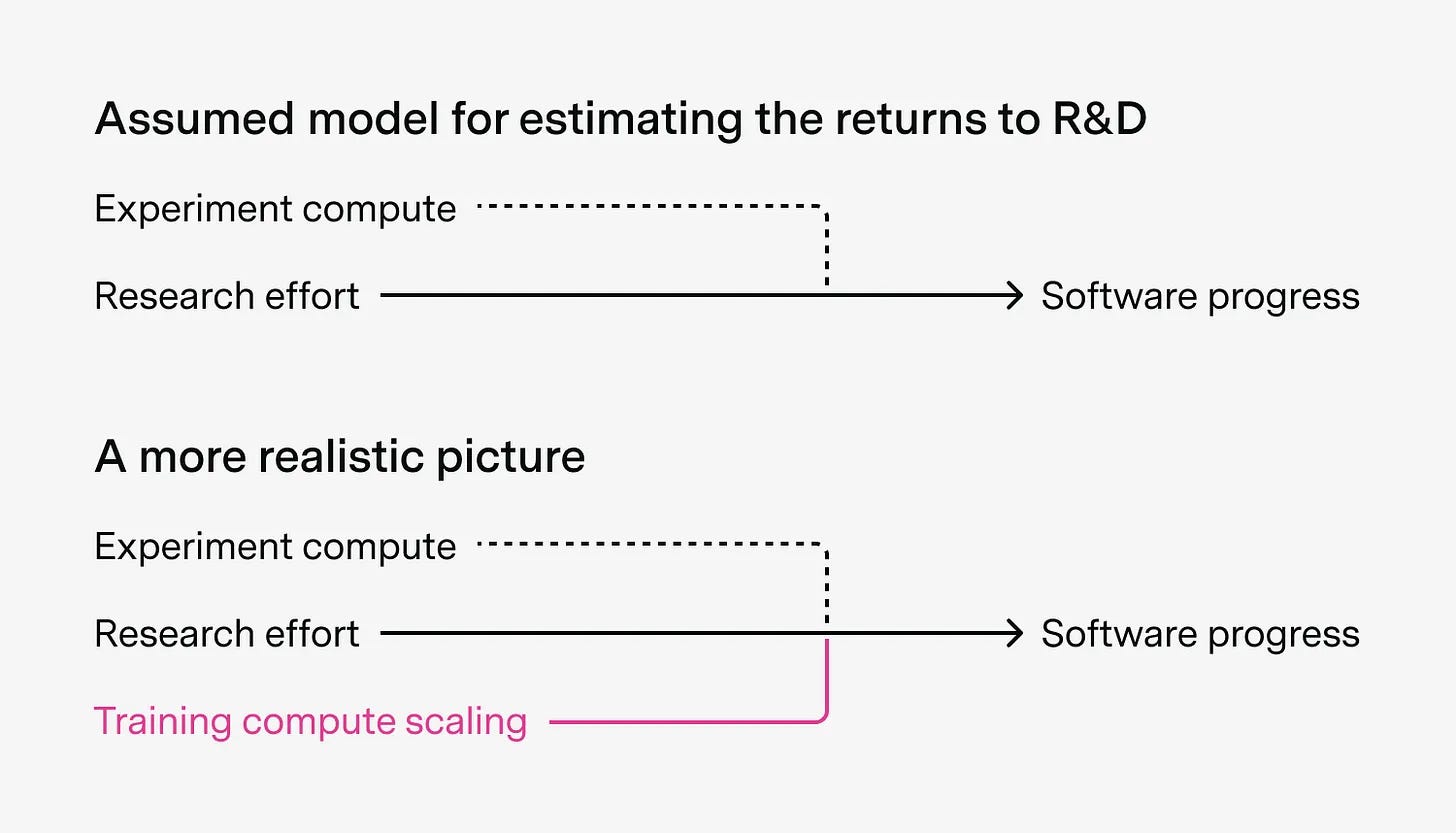
Steve Yegge’s take is that Anthropic’s real edge is not just Claude but a hive-mind way of working where humans and AI operate in a shared, high-speed loop that most companies aren’t built for yet.The least understood driver of AI progress (36 minute read)
Anson Ho highlights that software progress, not just bigger chips or more spending, is a major and underappreciated reason AI keeps getting better faster than many people expect.
Quick favor - need your take
Was there any standout article or topic from February I missed? Feel free to drop a comment or hit reply, even a quick line helps.
If you are already subscribed and enjoyed the article, please give it a like and/or share it others, really appreciate it 🙏
Keep learning
What the Data Crowd Was Reading in January 2026

It's time for another data/AI roundup and here are the highlights from January👇
𝐃𝐚𝐭𝐚 𝐒𝐜𝐢𝐞𝐧𝐜𝐞 & 𝐀𝐈
Why ‘use agents or be left behind’ is mostly about practical automation
Piecewise regression for spotting regime shifts in time series
Why AI benchmarks are hitting a measurement wall
What the data actually says about the state of open models
How large-scale recommendation systems are built in the real world
𝐃𝐚𝐭𝐚 𝐄𝐧𝐠𝐢𝐧𝐞𝐞𝐫𝐢𝐧𝐠
How Unity Catalog really works under the hood
Databricks Lakeflow vs Airflow in practice
End-to-end agentic data modeling with OpenMetadata
A candid look at the day-to-day reality of data engineering
How Uber cut data lake freshness from hours to minutes with Flink
𝐃𝐚𝐭𝐚 𝐀𝐧𝐚𝐥𝐲𝐬𝐢𝐬 & 𝐁𝐈
The best data visualization projects of 2025
Why storytelling matters more than chart tricks
Designing more accessible line charts
Practical rules for dashboard filter placement
Plus: ontologies explained, hard lessons from building AI agents in finance and new data on who’s really buying AI compute.
What the Data Crowd Was Reading in December 2025

It's time for another data/AI roundup and here are the highlights from December👇
𝐃𝐚𝐭𝐚 𝐒𝐜𝐢𝐞𝐧𝐜𝐞 & 𝐀𝐈
The state of LLMs in 2025
Building a data cleaning agent with LangGraph
Making sense of memory in AI agents
Exploring TabPFN: a foundation model built for tabular data
𝐃𝐚𝐭𝐚 𝐄𝐧𝐠𝐢𝐧𝐞𝐞𝐫𝐢𝐧𝐠
Opinionated data platforms vs. open-source
Data quality design patterns
LLM for PDF data pipelines
DuckDB: the Swiss army knife for data engineers
𝐃𝐚𝐭𝐚 𝐀𝐧𝐚𝐥𝐲𝐬𝐢𝐬 & 𝐁𝐈
A comprehensive guide to data visualization
Broken charts and 9 visualization alternatives
Plus: The most useful skill to learn as a data professional, predictions about AI in 2026 and the next data bottleneck
Thank you for sharing my work with Erfan!
Thanks for the shoutout man!!