
What the Data Crowd Was Reading in November 2025
Tools, techniques and deep dives worth reading that I came across in November 2025.

Fellow Data Tinkerers
It’s time for another round-up on all things data!
But before that, I wanted to share with you what you could unlock if you share Data Tinkerer with just 1 more person.
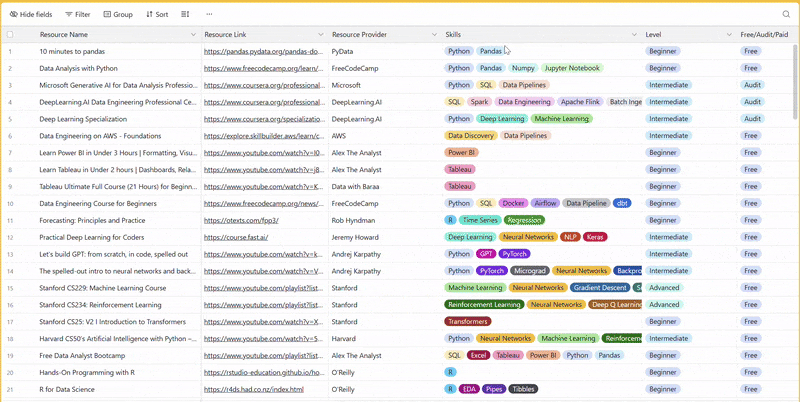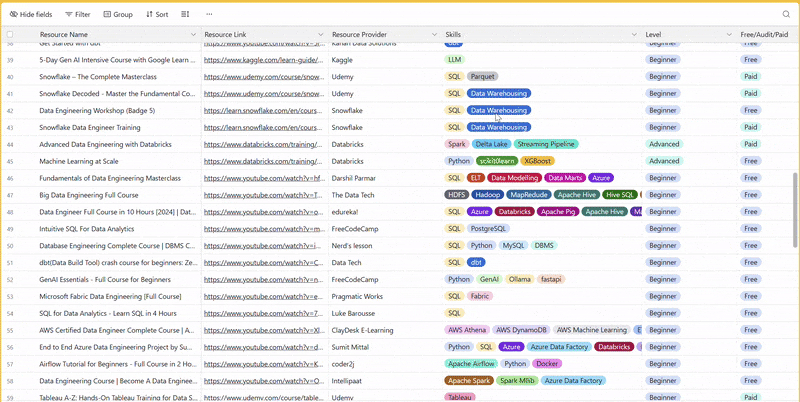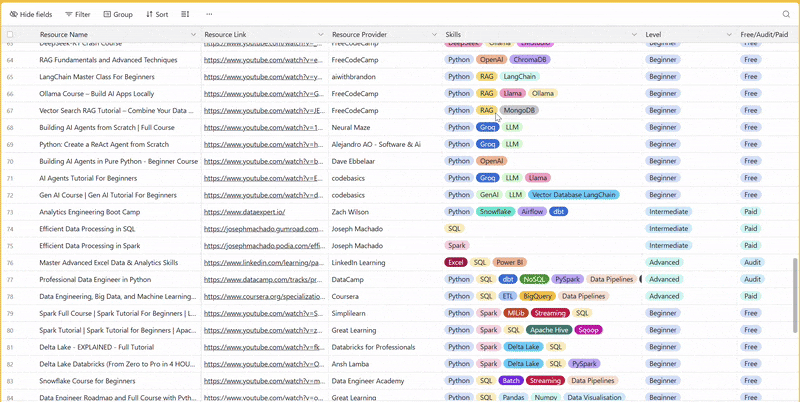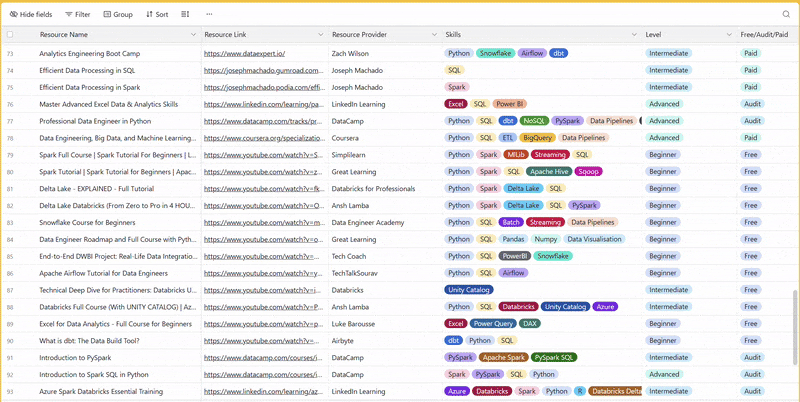
There are 100+ resources to learn all things data (science, engineering, analysis). It includes videos, courses, projects and can be filtered by tech stack (Python, SQL, Spark and etc), skill level (Beginner, Intermediate and so on) provider name or free/paid. So if you know other people who like staying up to date on all things data, please share Data Tinkerer with them!
Without further ado, let’s get to the round up for November.
