
What the Data Crowd Was Reading in March 2026
Tools, techniques and deep dives worth reading that I came across in March 2026.

Fellow Data Tinkerers
It’s time for another round-up on all things data and AI!
But before that, I wanted to share with you what you could unlock if you share Data Tinkerer with just 1 more person.
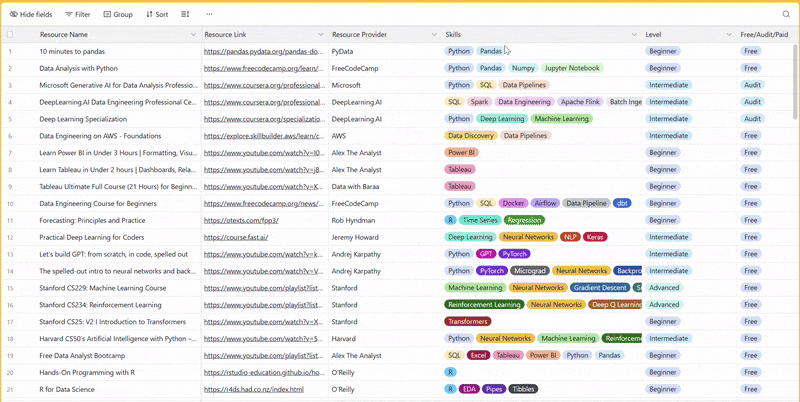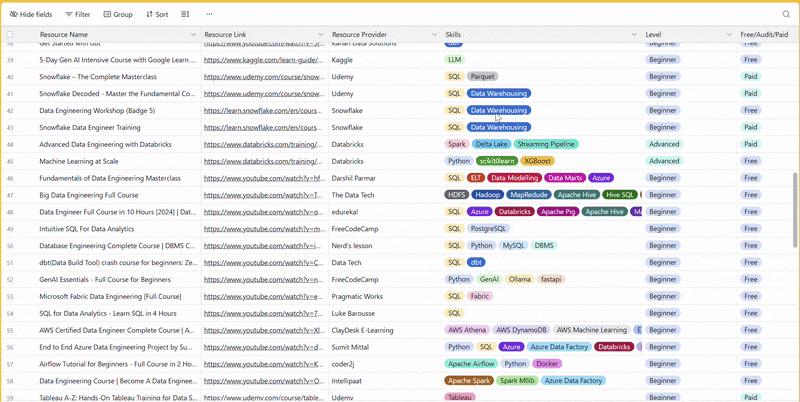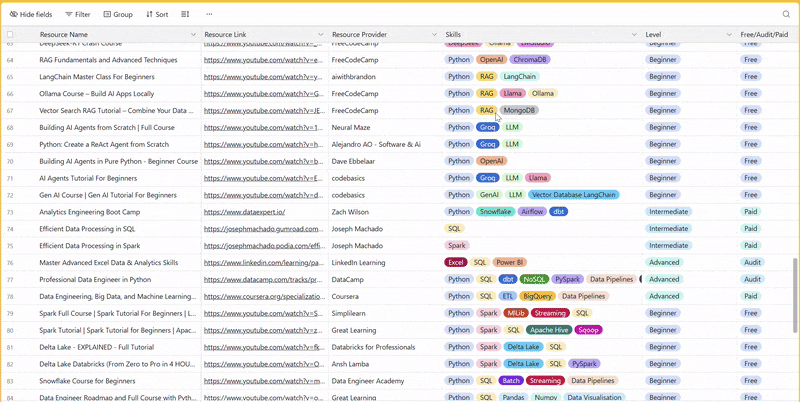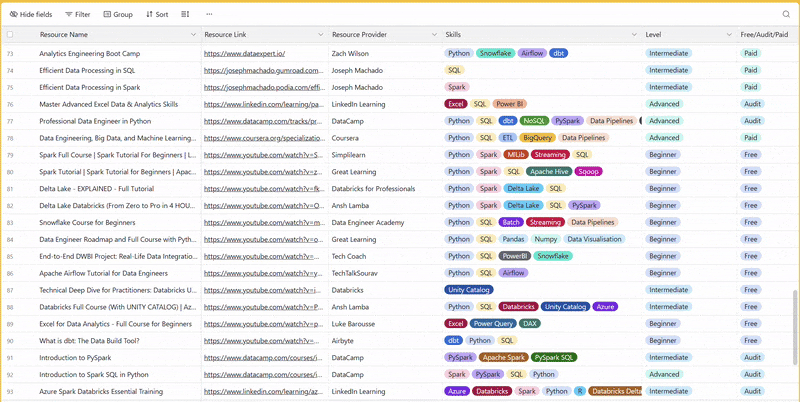
There are 100+ resources to learn all things data (science, engineering, analysis). It includes videos, courses, projects and can be filtered by tech stack (Python, SQL, Spark and etc), skill level (Beginner, Intermediate and so on) provider name or free/paid. So if you know other people who like staying up to date on all things data, please share Data Tinkerer with them!
Without further ado, let’s get to the round up for March!
Data science & AI
State of Context Engineering in 2026 (12 minute read)
Aurimas Griciūnas argues that context engineering is evolving from prompt tinkering into a structured discipline where managing memory, retrieval and state becomes the core challenge of building reliable AI systems.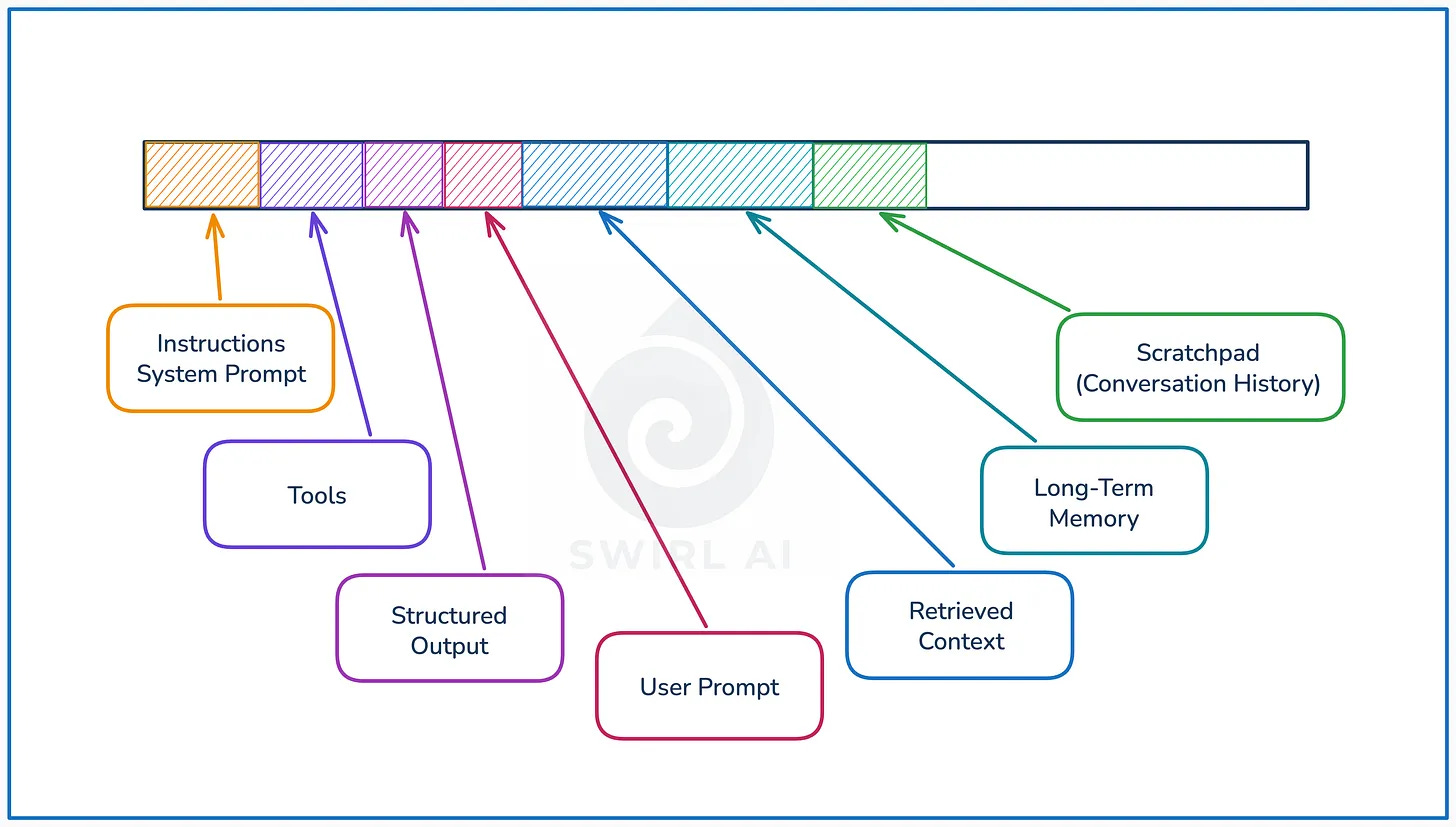
Bayesian statistics for confused data scientists (15 minute read)
Nicolas Chagnet explains Bayesian statistics in plain terms by showing that its real strength is not mathematical elegance but giving data scientists a cleaner way to reason about uncertainty and sparse real-world data.Agentic AI Engineering Guide (10 minute read)
Paul Iusztin argues that most agentic AI systems fail not because the model is weak, but because teams make avoidable engineering mistakes around context, architecture, planning and evaluation.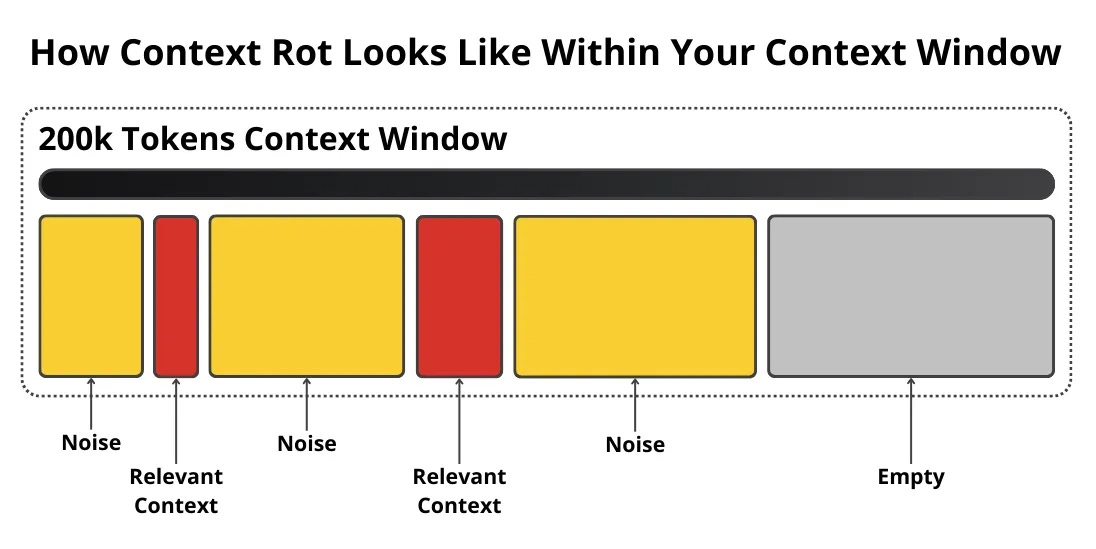
The Context Problem (29 minute read)
Jessica Talisman argues that the AI industry has turned context into a token-priced billing unit even though context should really mean the relational structure that makes information coherent and useful.A Visual Guide to Attention Variants in Modern LLMs (26 minute read)
Sebastian Raschka, PhD shows how modern LLM attention has evolved from standard multi-head attention into a growing set of variants each designed to balance quality, memory use and inference efficiency.
The Boon of Dimensionality (6 minute read)
Amandeep Singh shows that high-dimensional space creates the geometric conditions that make embeddings, random projections and feature separation work in modern machine learning.GPT 5.4 is a big step for Codex (9 minute read)
Nathan Lambert writes that GPT 5.4 feels like a real step forward for Codex, with gains in usability, speed, context handling and agent reliability that matter more in practice than benchmark scores alone.How Shopify Scales Taxonomy Evolution Across 10,000+ Categories With Multi-Agent AI (14 minute read)
This piece breaks down how Shopify moved from reactive manual updates to a multi-agent system that scans taxonomy branches in parallel, proposes new categories/attributes from merchant data, detects duplicates and runs automated QA through domain-specific judges.
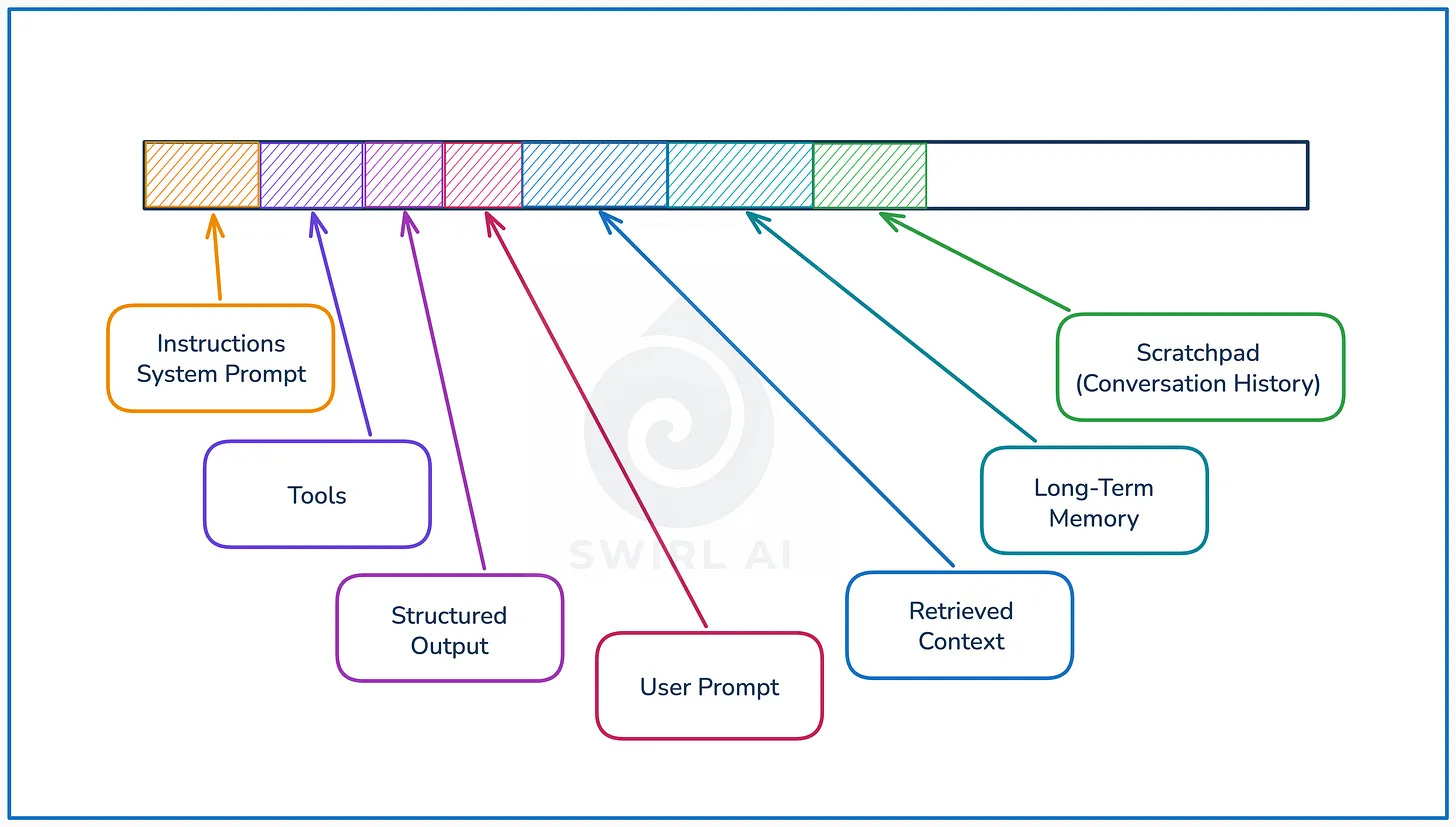
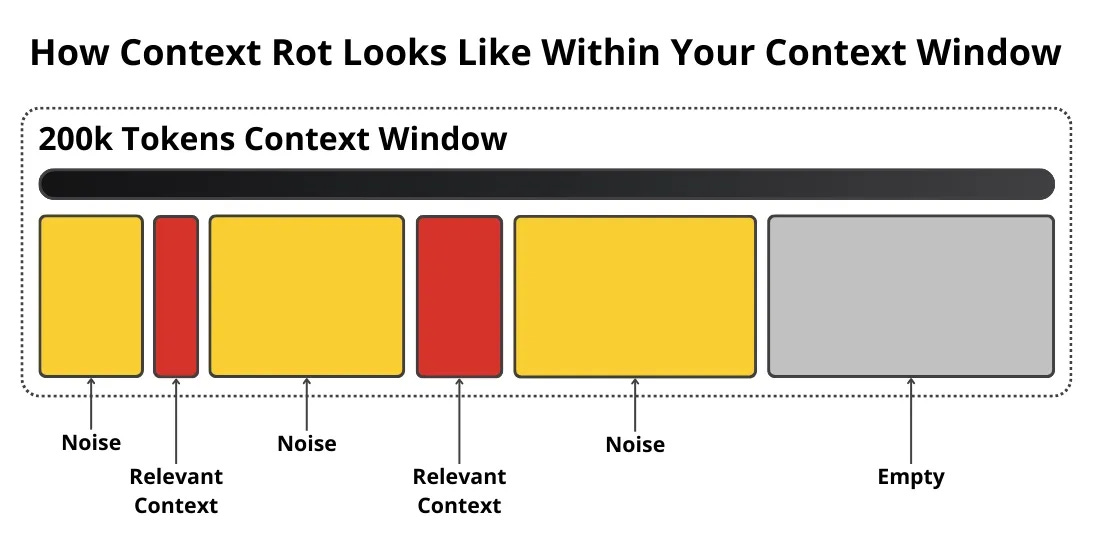

Data engineering
Layer by Layer, We Built Data Systems No One Understands (9 minute read)
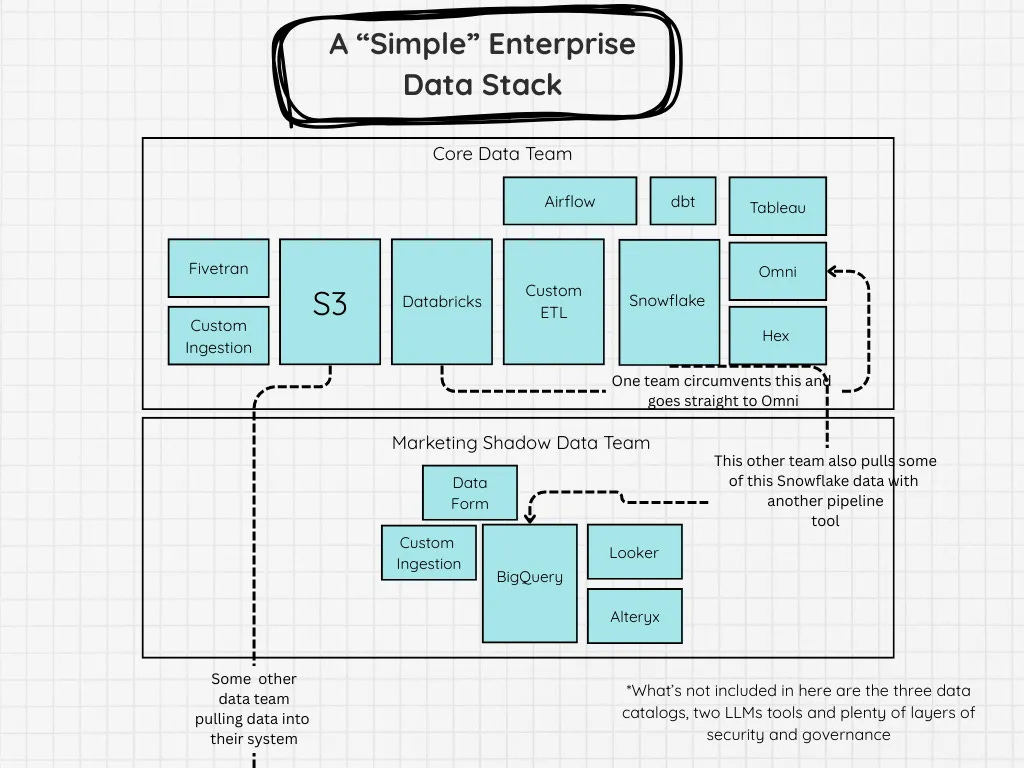
SeattleDataGuy writes that modern data stacks keep piling on layers in the name of simplicity but the result is often more sprawl, more cost and systems that are harder to understand or tie back to business outcomes.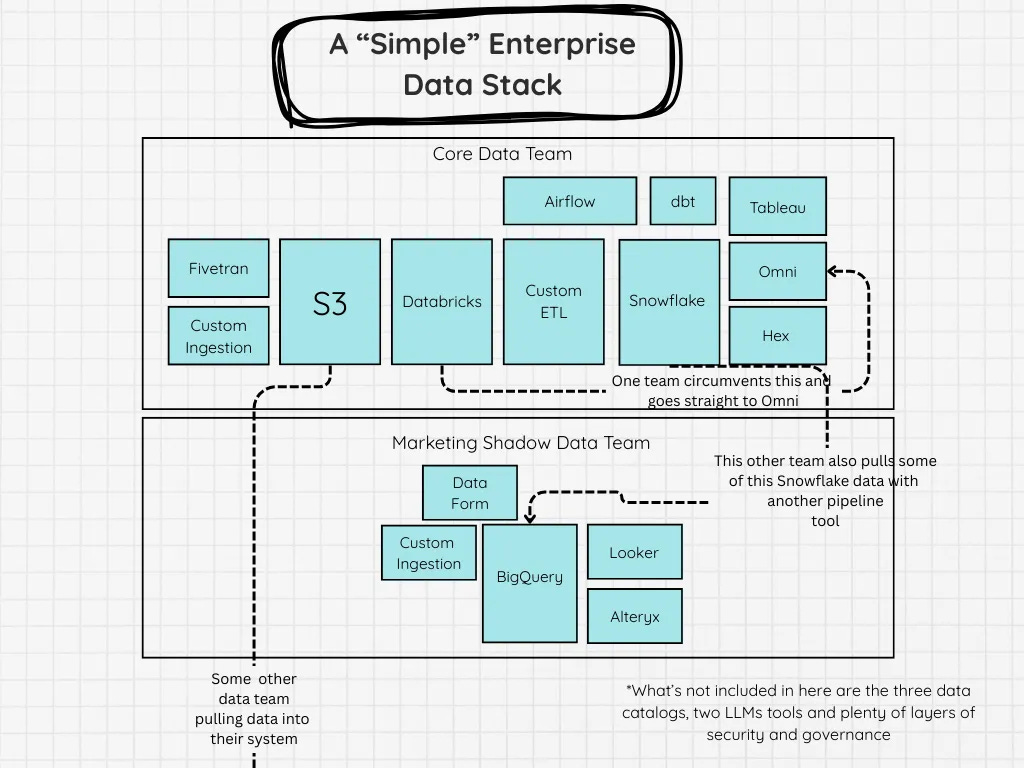
ETL is Dead (12 minute read)
Ananth Packkildurai argues that ETL is not disappearing in volume but it is fading as the core identity of data engineering as AI shifts the real work toward context and semantics.The Data Engineer’s GitHub Portfolio (2026 Edition) (10 minute read)
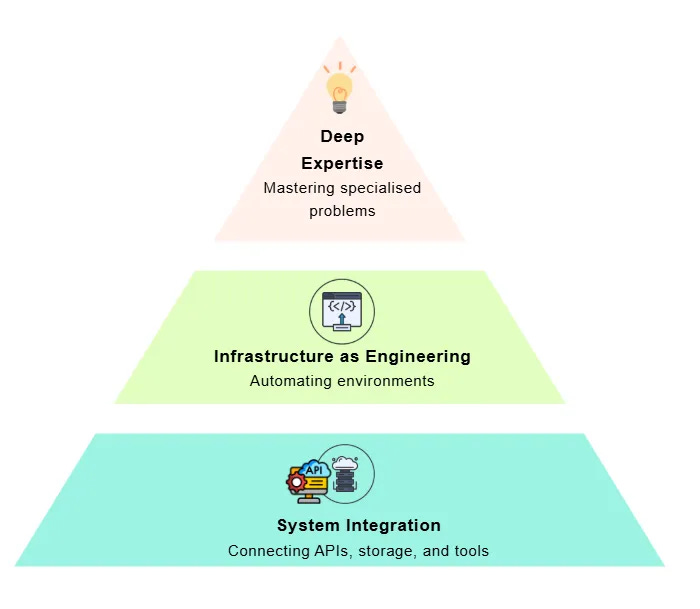
Yordan Ivanov writes that a strong data engineering GitHub portfolio should prove technical taste, system thinking and real-world problem solving, not just show a pile of tutorial projects.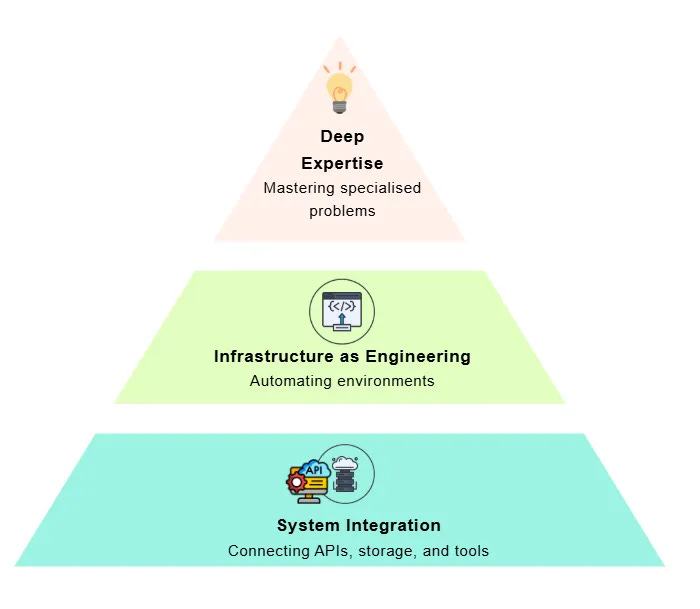
The Data Engineering Mindset Every AI Builder Needs (14 minute read)
Erfan Hesami writes that most AI products do not break because of the model but because builders ignore the data foundations early on, especially data flow design, data quality and monitoring.The absolute beginners guide to databasemaxxing (18 minute read)
This article walks through database internals from a beginner’s perspective, showing how concepts like parsing, binding, scans and index seeks fit together under the hood.Your Data Model Isn’t Broken, Part I: Why Refactoring Beats Rebuilding (12 minute read)
Chris Hillman makes the case that most broken data models are really bundles of hard-won business knowledge and that careful refactoring is usually smarter than blowing everything up and starting again.ClickHouse -> Real-time insight in 15 minutes (19 minute read)
Phi Vu Trinh shows that ClickHouse is built for real-time analytics but getting that performance in production usually means handling enough operational complexity that makes platforms like Tinybird appealing.
How Notion Scaled AI Q&A to Millions of Workspaces (14 minute read)
This article walks through how Notion scaled AI Q&A to millions of workspaces while increasing onboarding throughput 600x and cutting costs by up to 90%.

Other interesting reads
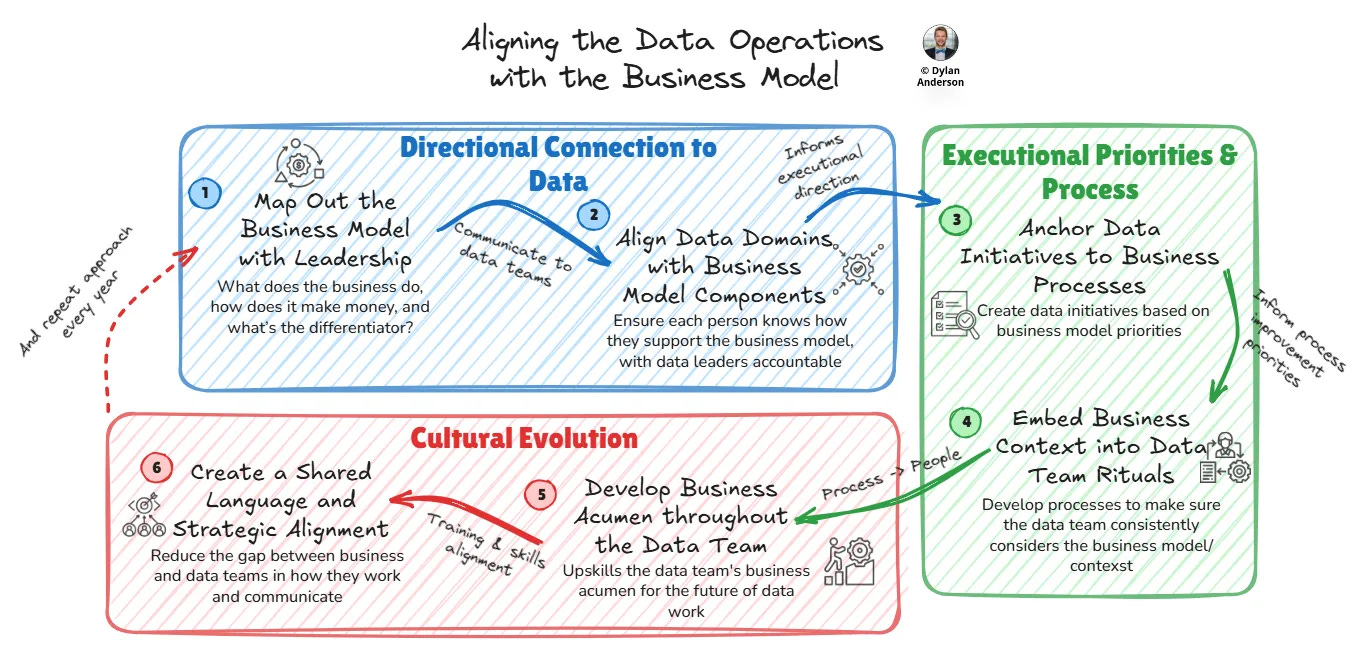
Relevance of Business Models for Data (10 minute read)
Dylan Anderson makes the case that data teams should start with the business model first, because strategy, architecture, governance and analytics all work better when they are tied to how the company actually creates and captures value.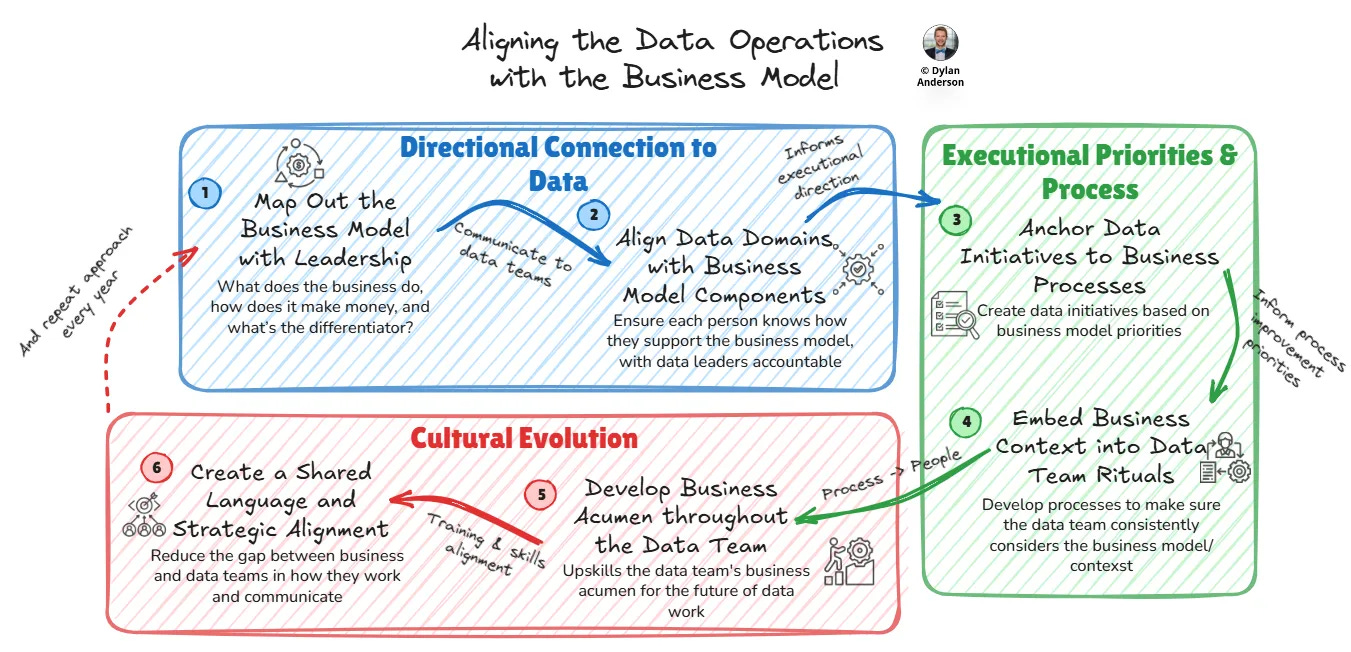
It’s about the strategy, stupid (14 minute read)
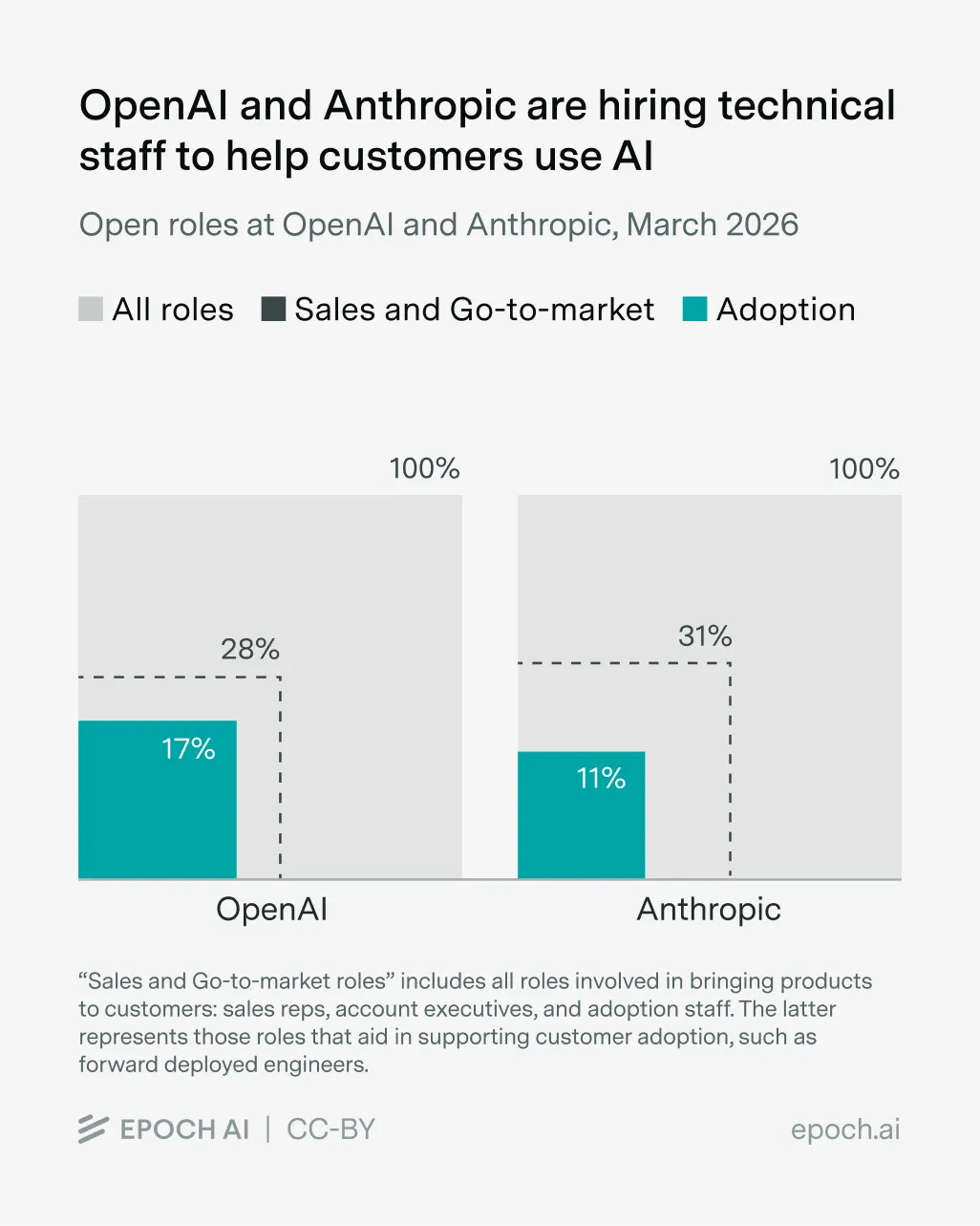
Timo Dechau makes the case that data work becomes far more useful when it starts with business strategy, not with dashboards, tracking audits or whatever tactic happens to be fashionable.What do frontier AI companies’ job postings reveal about their plans? (9 minute read)
Interesting article suggesting that frontier labs’ job postings reveal where the market is heading, with hiring patterns pointing to heavier go-to-market pushes, new product bets and different strategies for securing compute and data.
Quick favor - need your take
Was there any standout article or topic from March I missed? Feel free to drop a comment or hit reply, even a quick line helps.
If you are already subscribed and enjoyed the article, please give it a like and/or share it others, really appreciate it 🙏
Keep learning
What the Data Crowd Was Reading in February 2026

It’s time for another data/AI roundup and here are the highlights from February👇
𝐃𝐚𝐭𝐚 𝐒𝐜𝐢𝐞𝐧𝐜𝐞 & 𝐀𝐈
Inside OpenAI’s in-house data agent
A practical guide to which AI to use in the agentic era
Why judgment may not be uniquely human after all
How Codex is being used for serious research automation
Why semantic linking matters for giving data meaning
𝐃𝐚𝐭𝐚 𝐄𝐧𝐠𝐢𝐧𝐞𝐞𝐫𝐢𝐧𝐠
A portable analytics stack built on DuckDB, DuckLake, dlt and SQLMesh
Why healing tables beat slow-motion backfill disasters
The case for MetadataOps engineers
How to use AI tools without losing data engineering fundamentals
Why 5-second BigQuery queries can still be expensive
𝐃𝐚𝐭𝐚 𝐀𝐧𝐚𝐥𝐲𝐬𝐢𝐬 & 𝐁𝐈
The state of machine learning competitions in 2025
Plus: why AI is eating software’s TAM, what world models could unlock in robotics and why AI may intensify work instead of reducing it.
What the Data Crowd Was Reading in January 2026

It's time for another data/AI roundup and here are the highlights from January👇
𝐃𝐚𝐭𝐚 𝐒𝐜𝐢𝐞𝐧𝐜𝐞 & 𝐀𝐈
Why ‘use agents or be left behind’ is mostly about practical automation
Piecewise regression for spotting regime shifts in time series
Why AI benchmarks are hitting a measurement wall
What the data actually says about the state of open models
How large-scale recommendation systems are built in the real world
𝐃𝐚𝐭𝐚 𝐄𝐧𝐠𝐢𝐧𝐞𝐞𝐫𝐢𝐧𝐠
How Unity Catalog really works under the hood
Databricks Lakeflow vs Airflow in practice
End-to-end agentic data modeling with OpenMetadata
A candid look at the day-to-day reality of data engineering
How Uber cut data lake freshness from hours to minutes with Flink
𝐃𝐚𝐭𝐚 𝐀𝐧𝐚𝐥𝐲𝐬𝐢𝐬 & 𝐁𝐈
The best data visualization projects of 2025
Why storytelling matters more than chart tricks
Designing more accessible line charts
Practical rules for dashboard filter placement
Plus: ontologies explained, hard lessons from building AI agents in finance and new data on who’s really buying AI compute.
Thank you for the mention :)