
What the Data Crowd Was Reading in April 2026
Tools, techniques and deep dives worth reading that I came across in April 2026.

Fellow Data Tinkerers
It’s time for another round-up on all things data and AI!
But before that, I wanted to share with you what you could unlock if you share Data Tinkerer with just 1 more person.
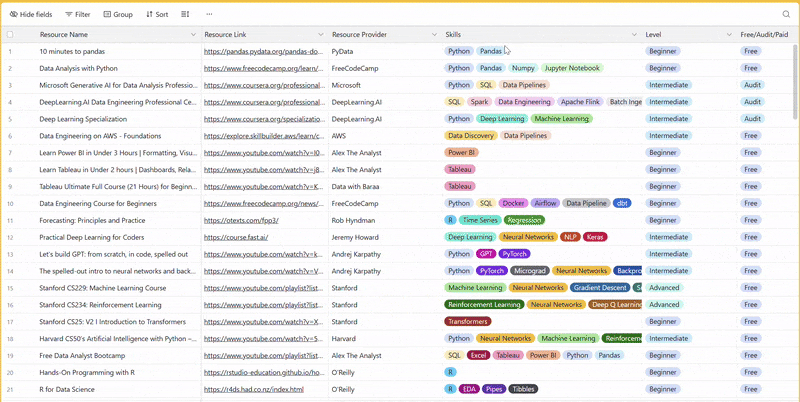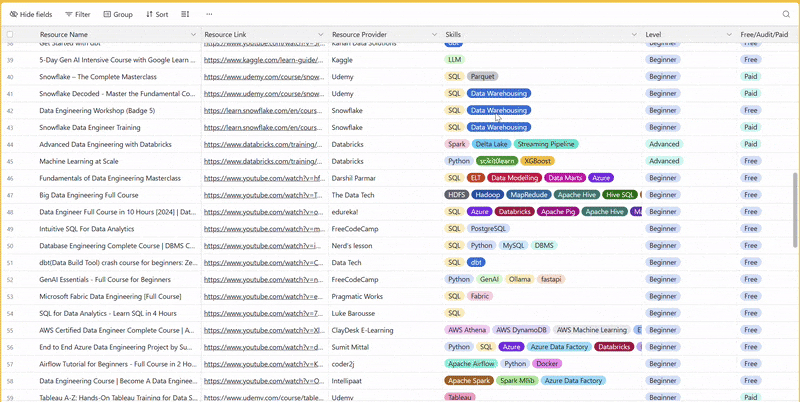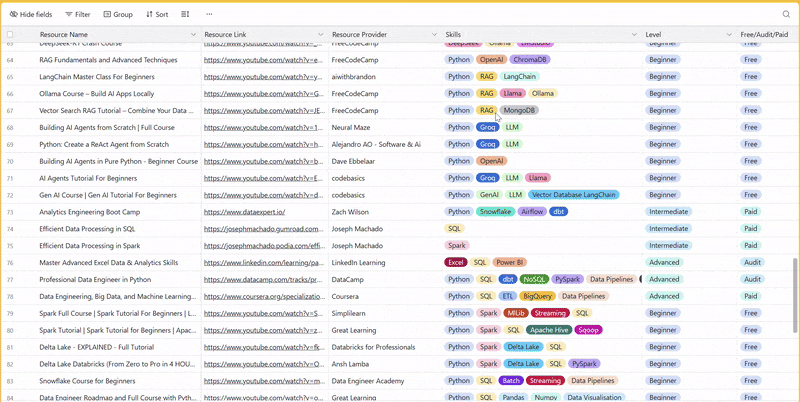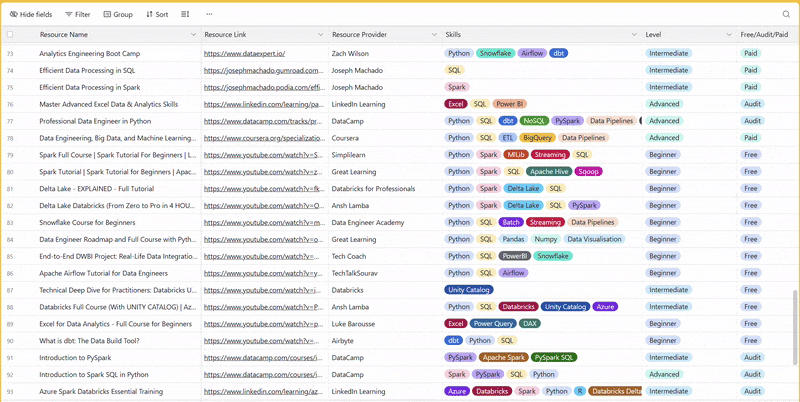
There are 100+ resources to learn all things data (science, engineering, analysis). It includes videos, courses, projects and can be filtered by tech stack (Python, SQL, Spark and etc), skill level (Beginner, Intermediate and so on) provider name or free/paid. So if you know other people who like staying up to date on all things data, please share Data Tinkerer with them!
Without further ado, let’s get to the round up for April!
Data science & AI
Components of a Coding Agent (19 minute read)
Sebastian Raschka, PhD provides a great break down of the six core components of coding agents, showing why tools, repo context, memory, caching and context management often matter as much as the underlying LLM.
The Revenge of the Data Scientist (8 minute read)
Hamel Husain argues data science is making a comeback in the LLM era because evals, traces, metrics, labels and experimental design are exactly the skills needed to make AI systems work reliably.Machine Learning Visualized (4 minute read)
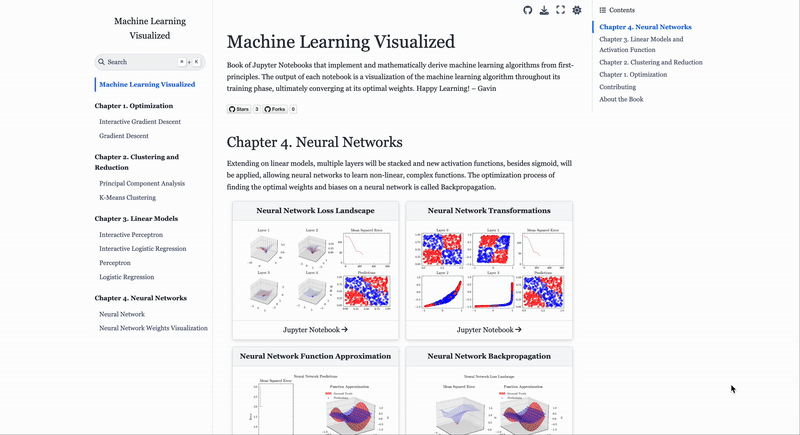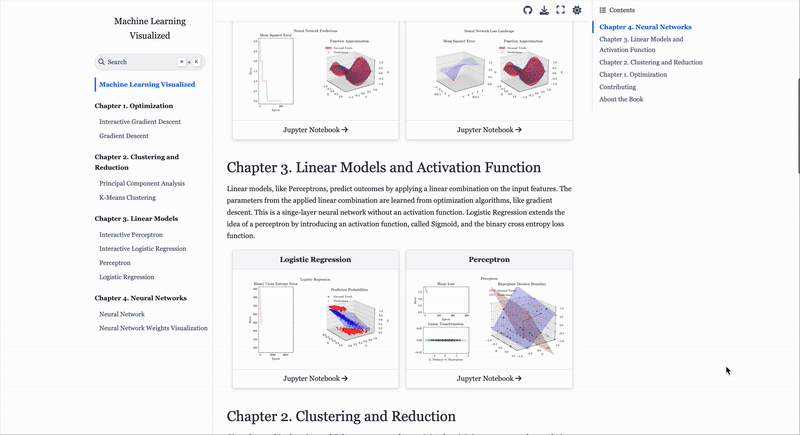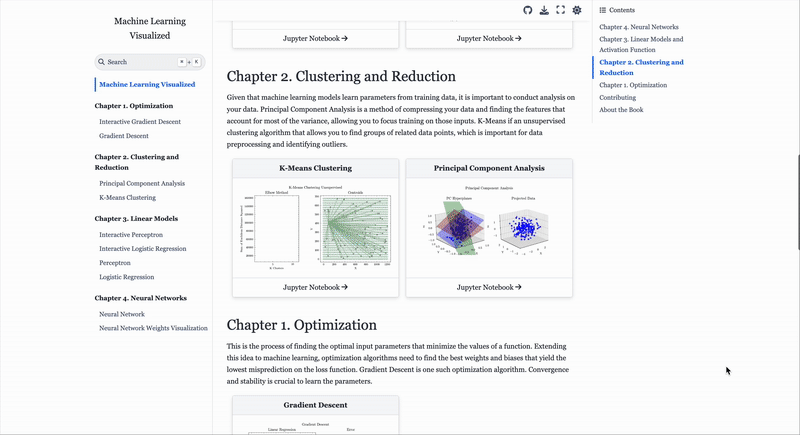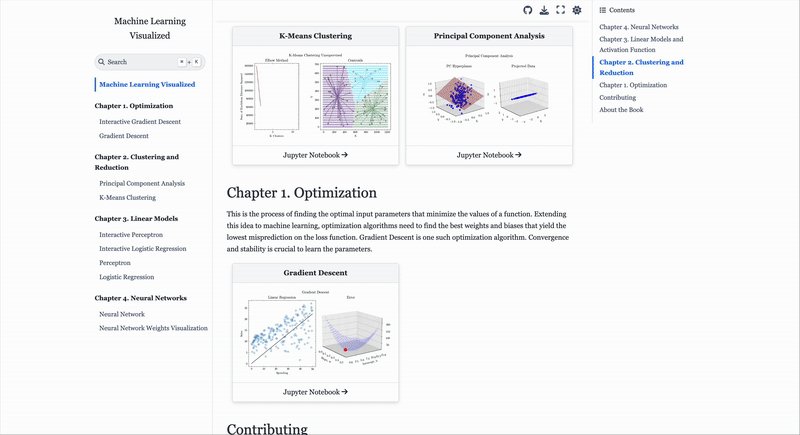
Gavin Hung’s Machine Learning Visualized is a free, notebook-based guide that derives ML algorithms from first principles and uses interactive visuals to show how models train, learn and converge.
Your AI Might be Lying to Your Boss (17 minute read)
William O’Connell argues while AI IDEs can help developers save time, their metrics around AI-generated code are inaccurate and can't be trusted because of their self-serving interests.Why Most Time Series Models Fail Before They Start (18 minute read)
This article explains why many time series models fail before they start, showing how stationarity checks, visual diagnostics and transformations like differencing can stop models from chasing trends instead of learning real signal.Multi-agent coordination patterns: Five approaches and when to use them (5 minute read)
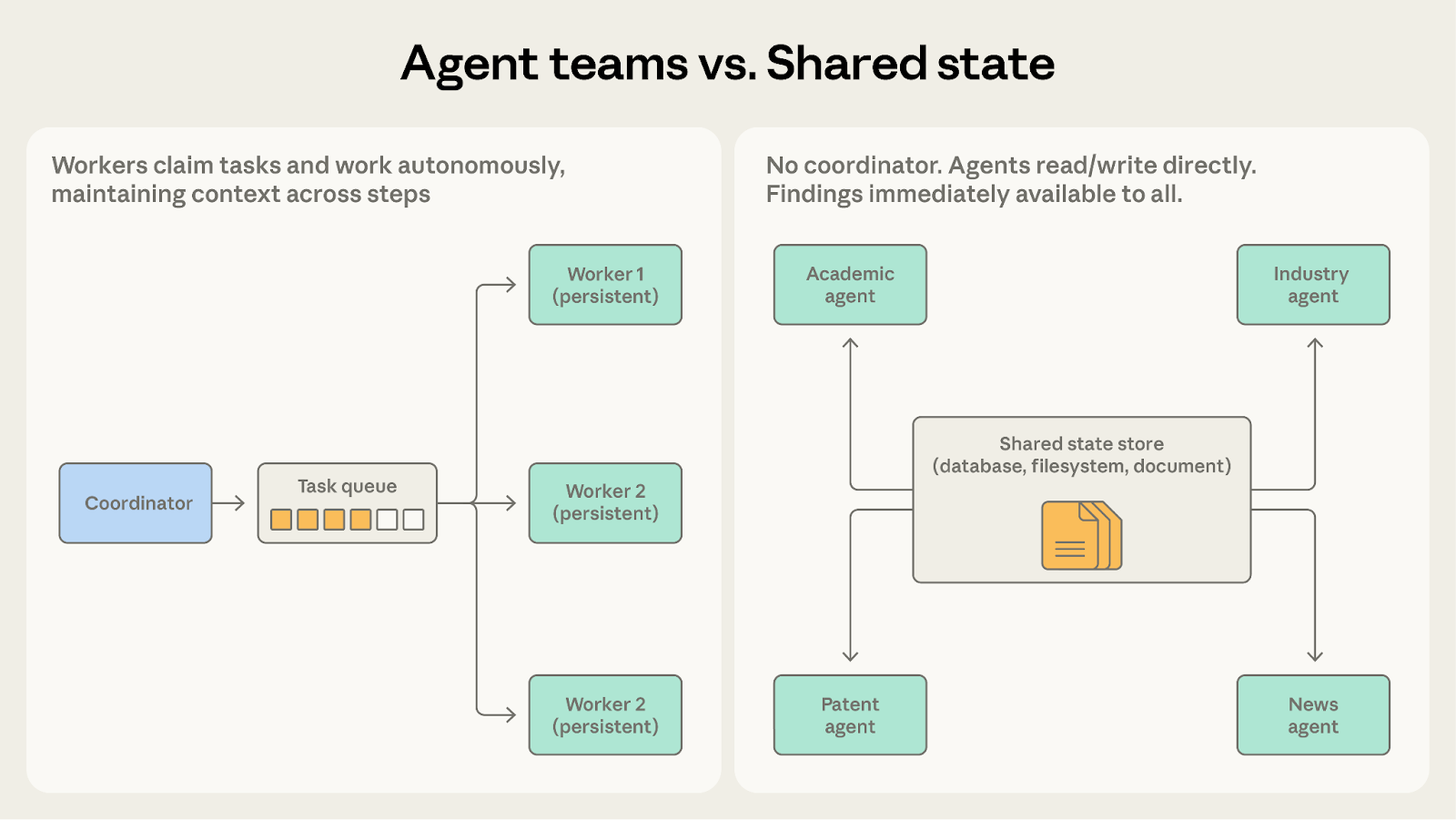
Anthropic breaks down five multi-agent coordination patterns, showing when to use generator-verifier, orchestrator-subagent, agent teams, message bus or shared state instead of overcomplicating agent systems too early.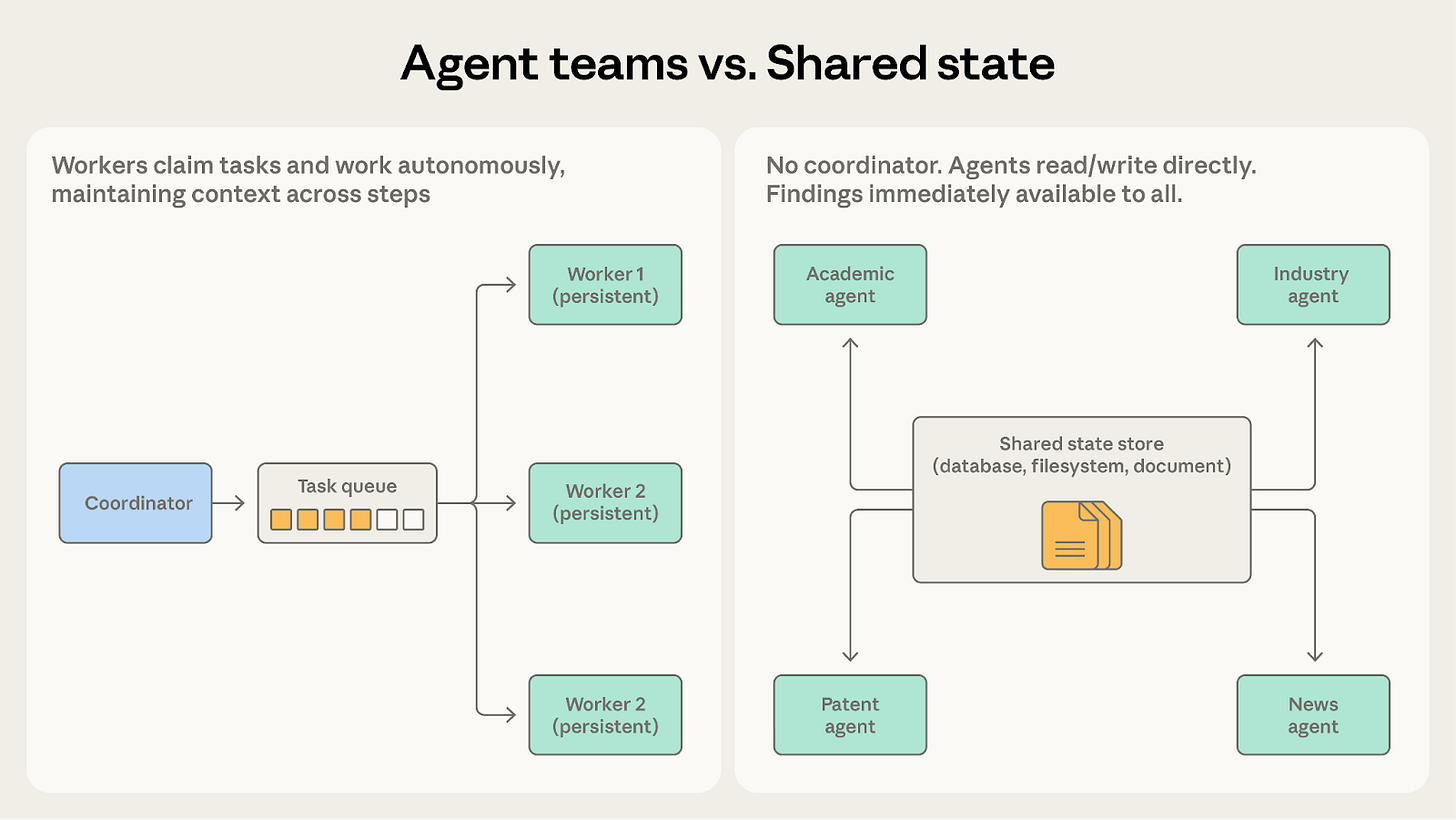
AIs can now often do massive easy-to-verify SWE tasks and I’ve updated towards shorter timelines (20 minute read)
Ryan Greenblatt argues that AIs are now much better at massive, easy-to-verify software engineering tasks than expected, which has pushed him toward shorter AI timelines even though judgment-heavy work remains a major bottleneck.Being a Staff+ Data Scientist in 2026 (14 minute read)
Brandon Rohrer argues staff+ data science is less about fancy models and more about navigating messy stakeholder incentives, uncertainty, self-serve myths and the human work needed to turn data into decisions.How Pinterest Used Multimodal AI to Help Millions of Shoppers (14 minute read)
Pinterest turned billions of products into 4.2 million shopping landing pages and improved search performance by 35%. This piece breaks down how Pinterest used vision-language models, contrastive learning and distributed inference to make products easier to discover.

Data engineering
Architectural Foundations & Infrastructure (12 minute read)
Daniel Beach kicks off a good data platform architecture series, arguing that good infrastructure choices start with business requirements, data shape and boring fundamentals like scalability, resilience, modularity, observability and cost.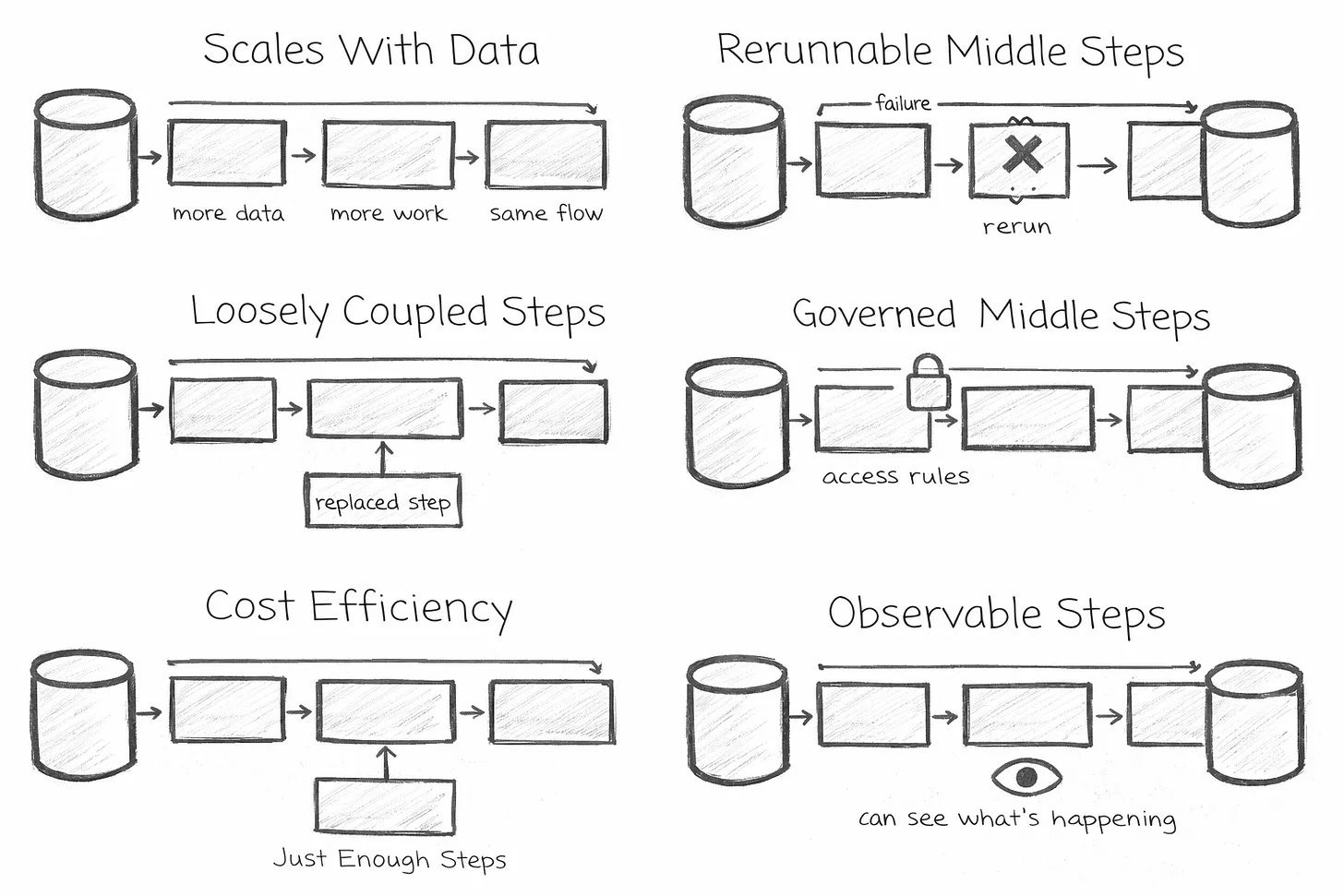
The 5 Silent Failures in Data Pipelines (11 minute read)
SeattleDataGuy breaks down five silent pipeline failures, from schema drift to stale data and brittle logic, showing how bad data can reach dashboards without throwing a single error.
Data Observability Fundamentals for Data Engineers (18 minute read)
Good article by Pipeline to Insights explaining data observability as a tool-agnostic way to catch silent pipeline failures, using freshness, volume, schema, quality and lineage signals to keep data and AI systems trustworthy.The Power of Data Sketches: A Comprehensive Guide (19 minute read)
luminousmen explains how data sketches trade perfect accuracy for tiny memory, fast queries and bounded error, making them useful when exact counts and aggregations become too expensive at scale.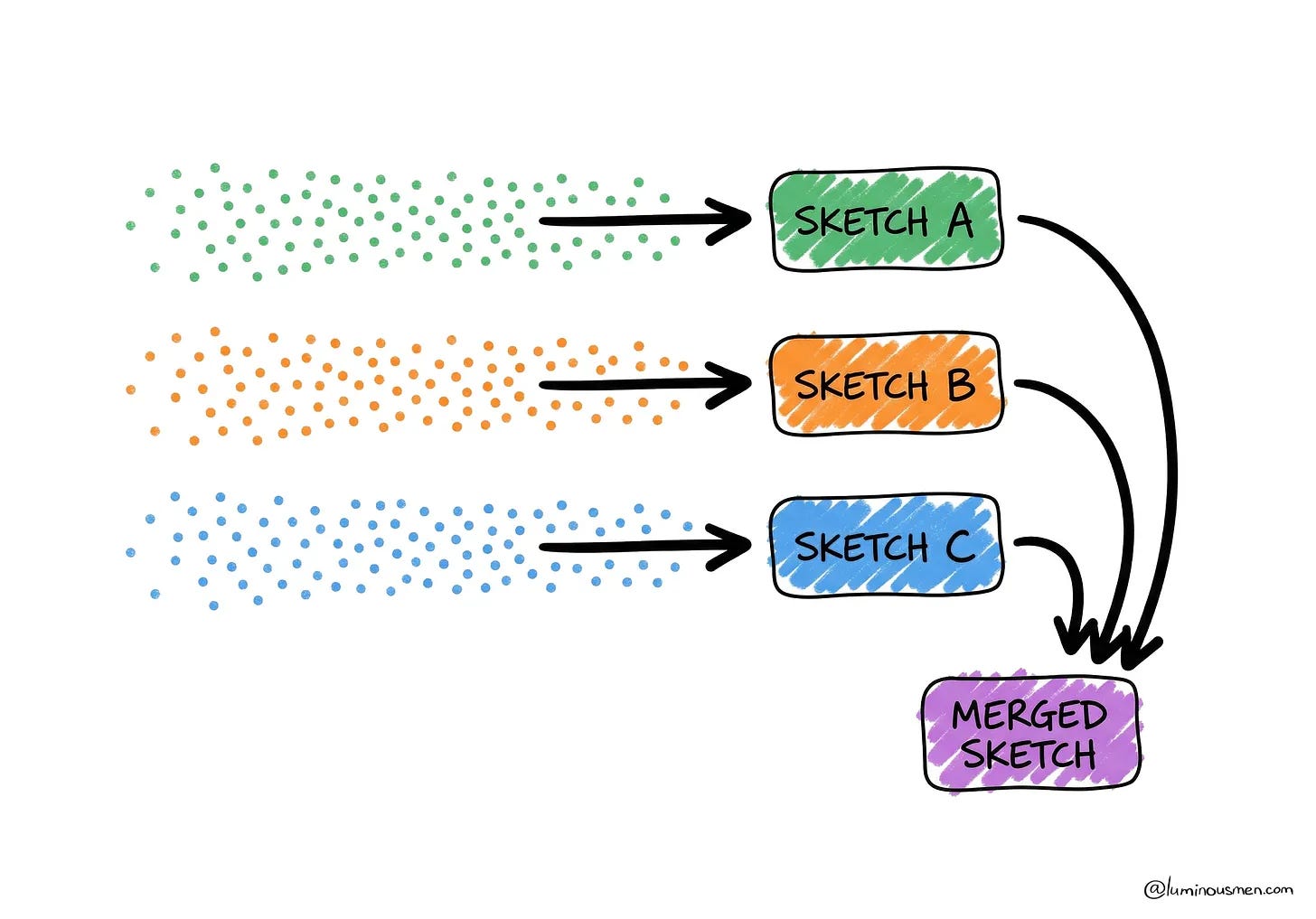
Stop Letting Tools Lead Your Platform Decisions (5 minute read)
Andreas Kretz argues data platform decisions should start with use cases, constraints and users, not fashionable tools, because the simplest architecture is often the one that actually fits.Databases Were Not Designed For This (16 minute read)
Arpit Bhayani argues agentic AI makes databases riskier, so teams need defensive patterns like least privilege, timeouts, idempotency, soft deletes and query tagging before giving agents access to production data.The Last Mile to Apache Iceberg - Building a Basement Data Platform (13 minute read)
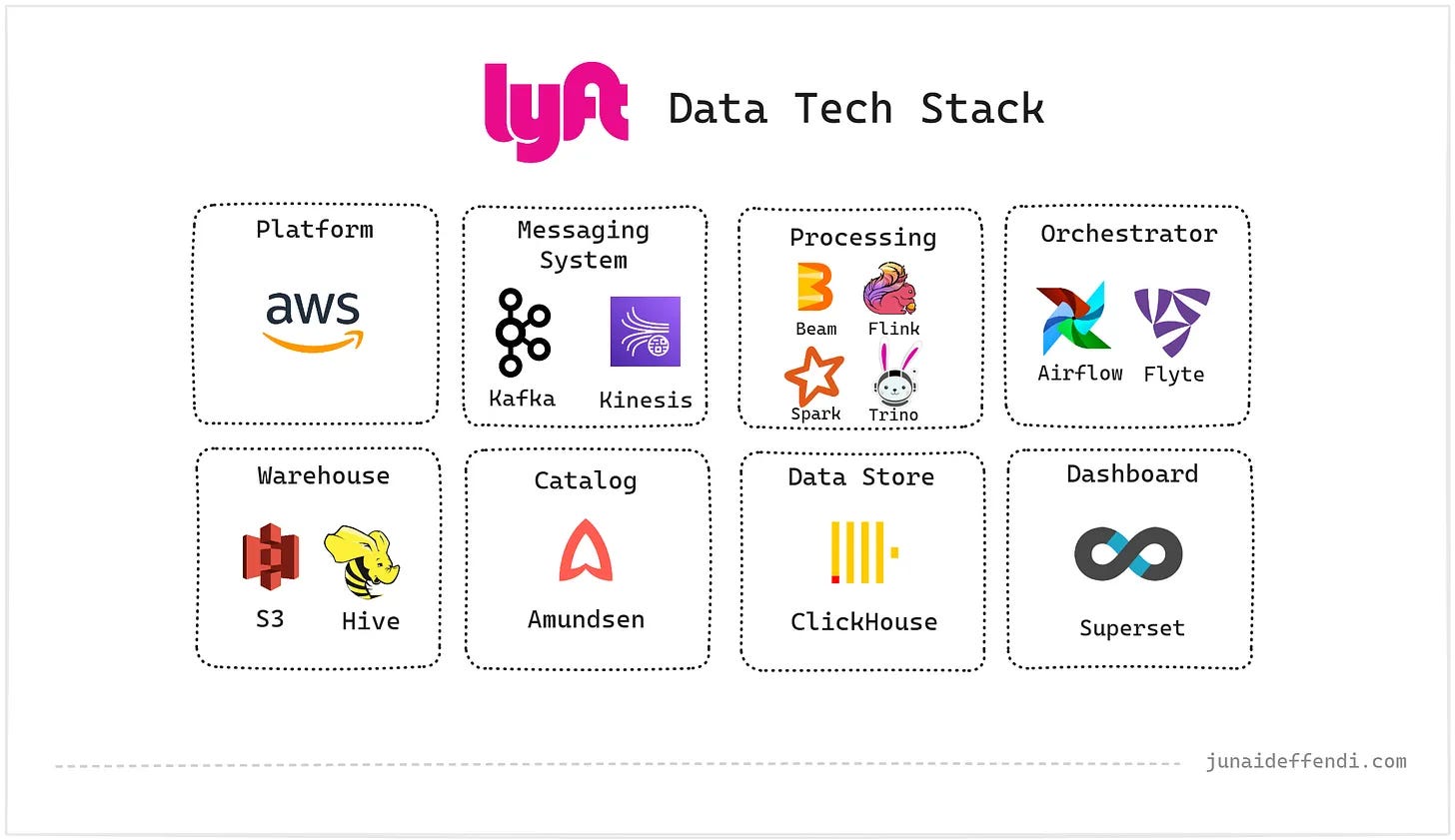
Arturas Tutkus shows how he solved the ‘last mile’ into Apache Iceberg by building a tiny low-cost event ingestion path for side-project analytics without Kafka, SaaS pipelines or a scary cloud bill.Lyft Data Tech Stack (5 minute read)
Junaid Effendi breaks down Lyft’s data stack, showing how Kafka, Flink, Trino, Airflow, Flyte and 100+ PB on S3 support real-time analytics, ML and millions of daily rides.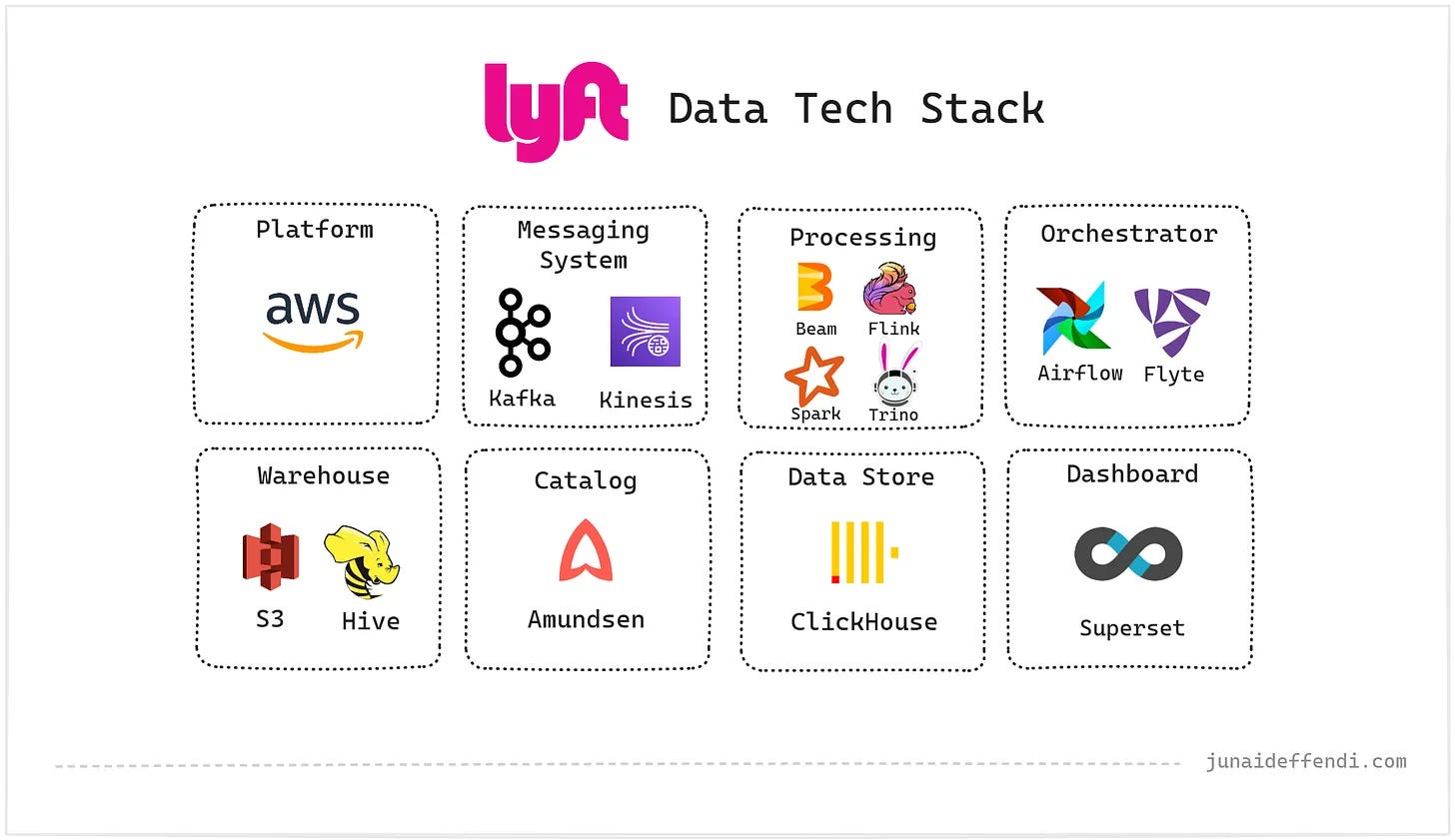
30 BI Engineering Interview Questions That Actually Matter in the AI Era (32 minute read)
Anusha Kovi reframes BI engineering interviews for the AI era around the skills that still matter: SQL judgment, semantic modeling, data governance, trustworthy metrics and turning messy business questions into reliable analytics.How Airtable Saved Millions by Cutting Archive Storage Costs by 100x (16 minute read)
Airtable moved petabytes of archive data out of MySQL, made storage 100x cheaper and kept interactive query latency intact. This piece breaks down how Airtable handled the migration, why it chose DataFusion and the optimizations that made cold storage feel fast.
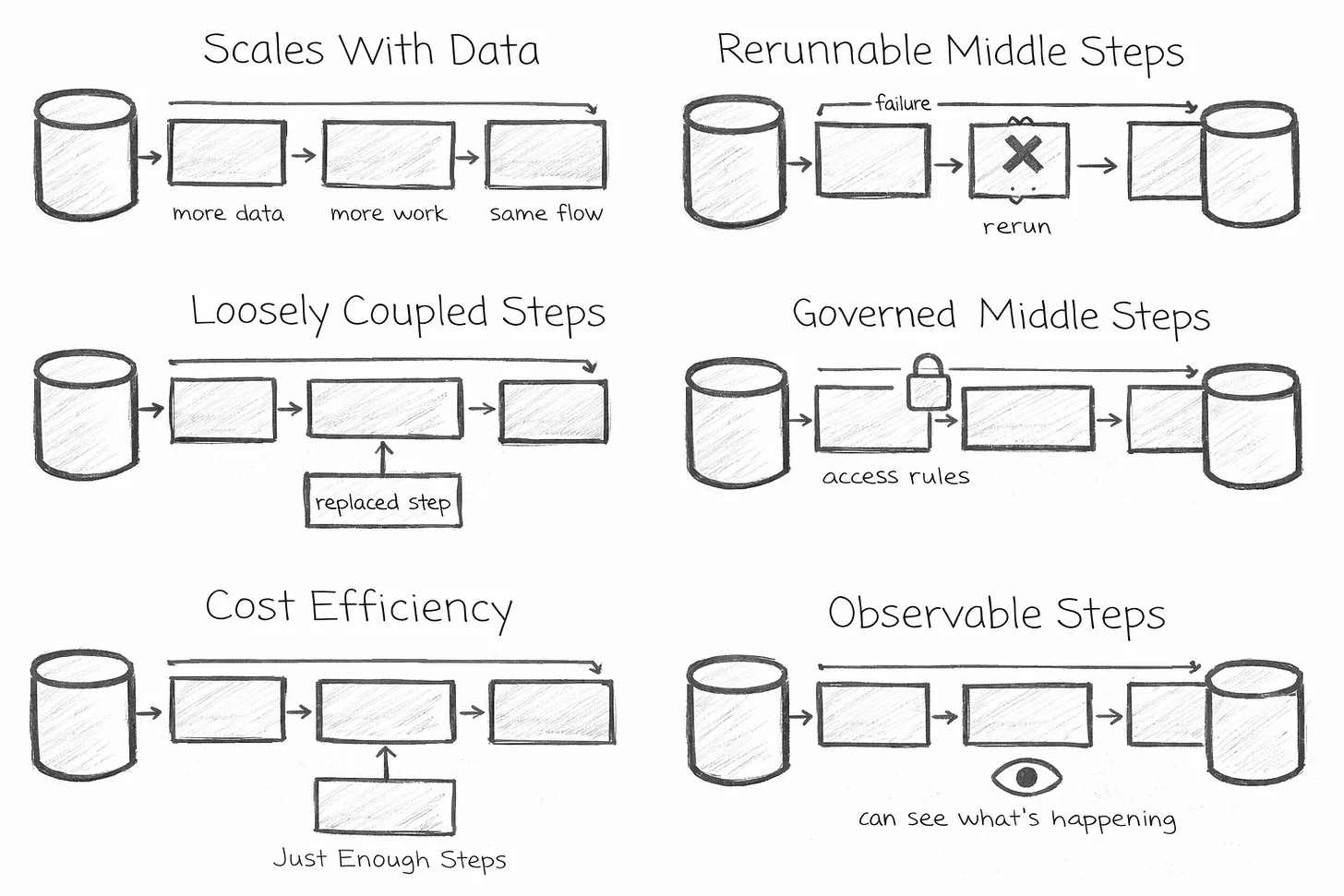

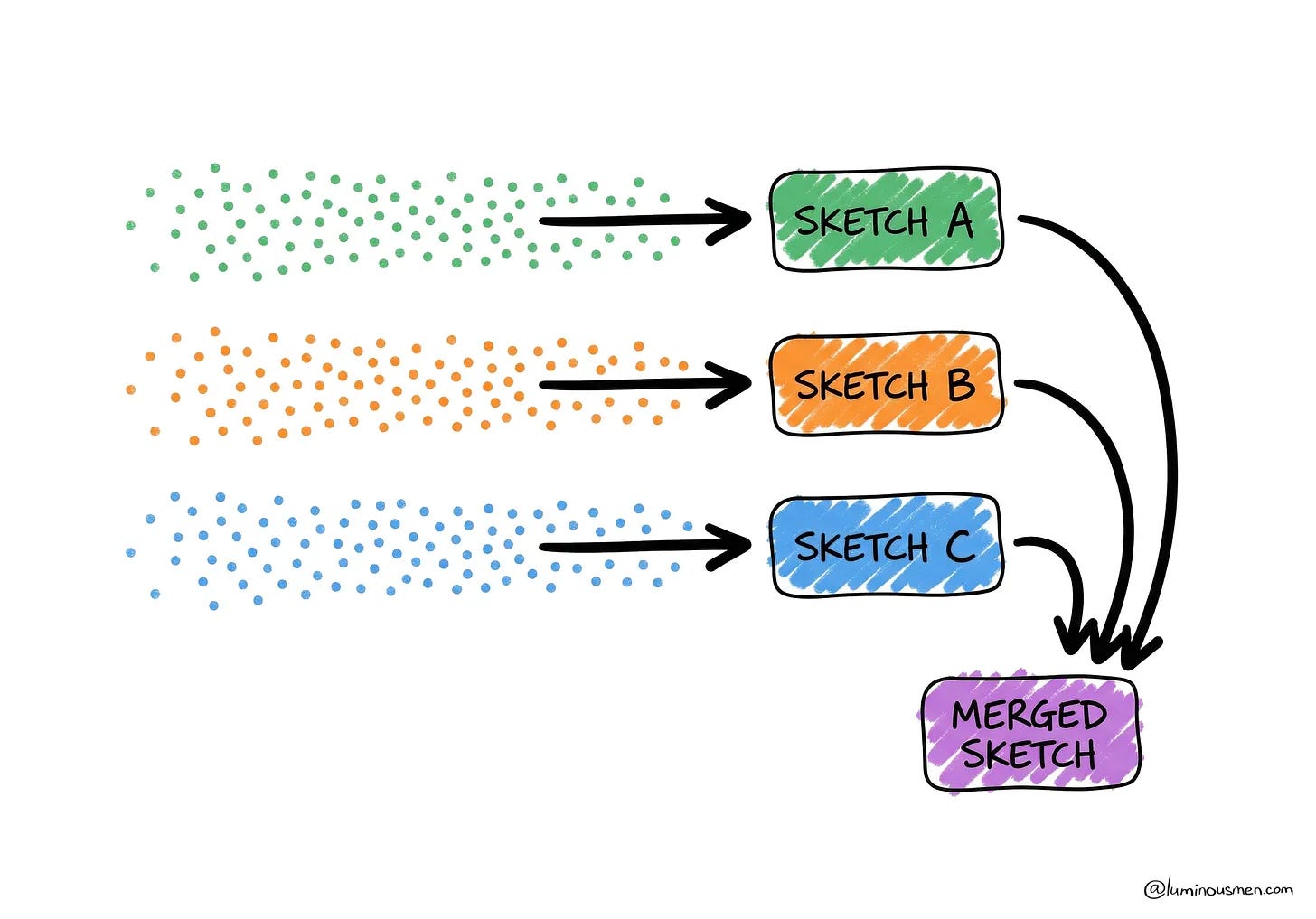
Data analysis and visualisation
The data role is being reborn (8 minute read)
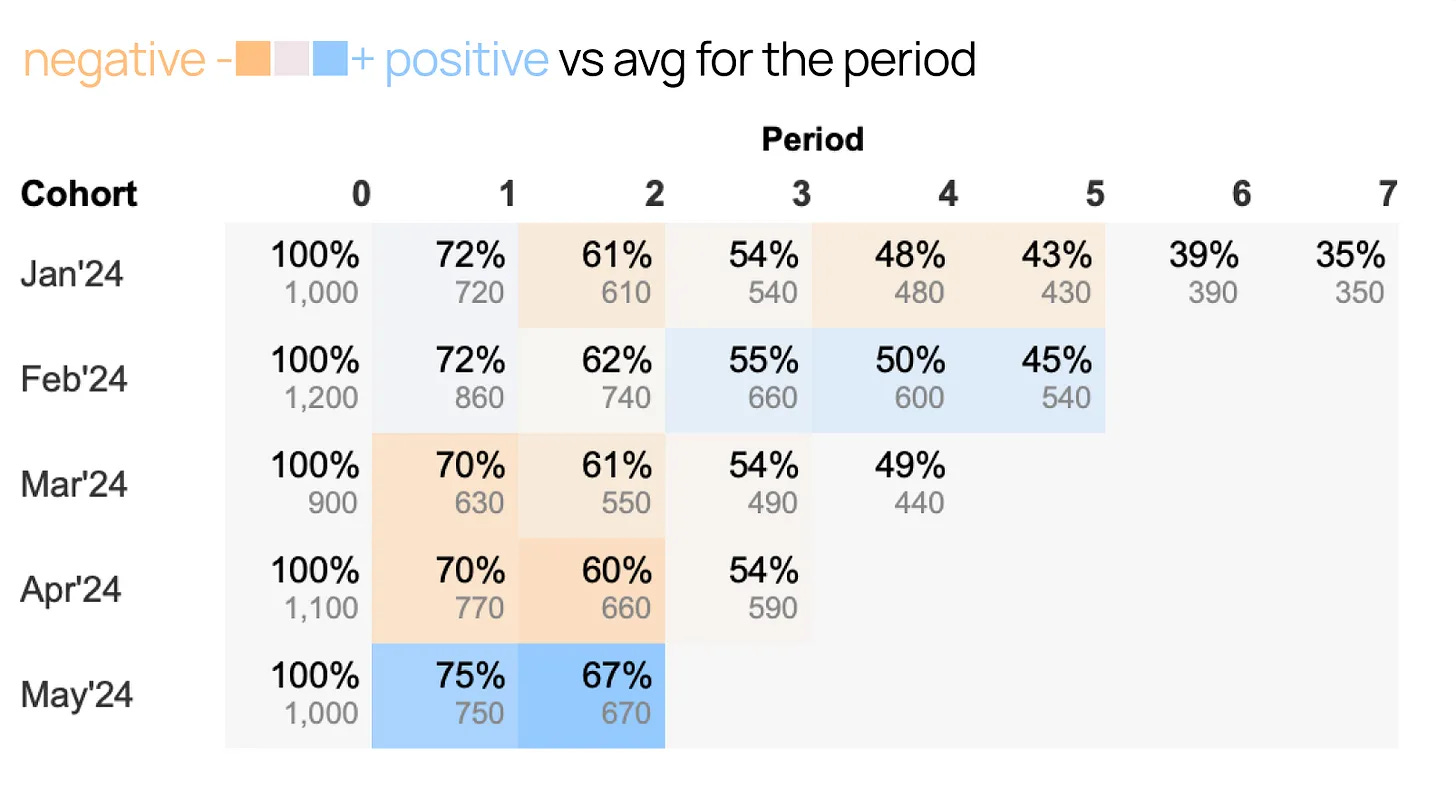
Thais Cooke thinks the data role is being reborn, with AI shrinking old output-heavy analyst work while increasing the need for judgment, business context and decision-shaping.Stop Coloring Retention Tables the Classic Way (3 minute read)
Anastasiya Kuznetsova shows that retention tables become much more useful when you color cohorts by deviation from the period average, rather than using classic gradients that mostly show the obvious decline over time.
Dashboard rot as org attention grave markers (10 minute read)
Randy Au argues dashboard rot is not really a dashboard problem, but a sign of shifting organisational attention, stale priorities and abandoned decisions fossilised as BI clutter.
Other interesting reads
We’re in 1905: Why Electricity (Not Dot-Com) Is the Right AI Analogy (12 minute read)
Interesting article by Joe Reis arguing AI is less like the dot-com boom and more like early electricity: the technology works but the real productivity gains will only come when companies redesign their workflows, org structures and data “factories” around it.Keeping up with the GPTs (24 minute read)
Anson Ho thinks compute-poor AI labs can narrow the gap through efficiency tricks like distillation, but compute still dominates, so catching up with frontier labs is much easier than overtaking them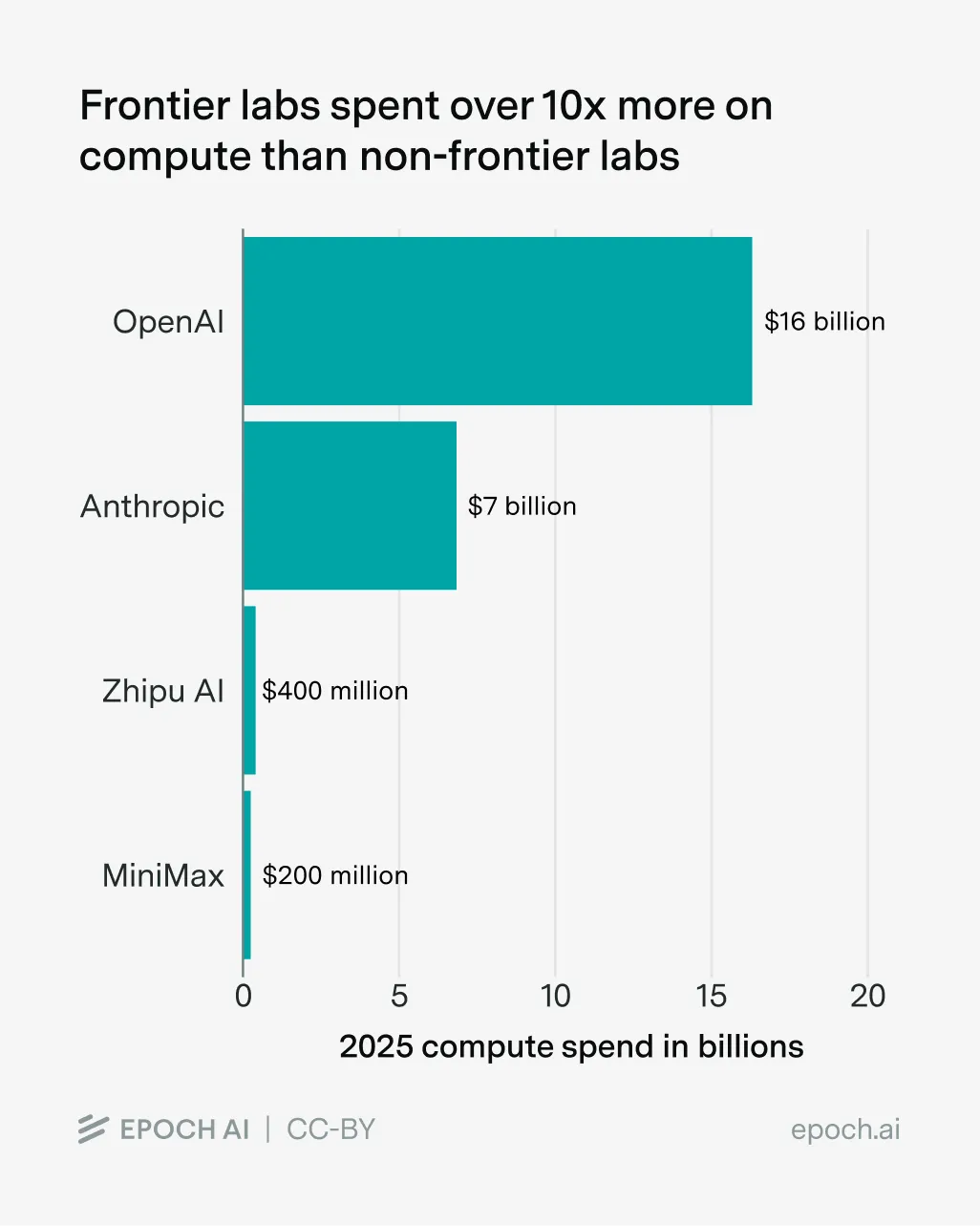
Seeing like a spreadsheet (23 minute read)
Interesting article by David Oks discussing how spreadsheets reshaped American business into a numbers-first optimisation machine and that AI may reorganise work and decision-making in a similar way.
Quick favor - need your take
Was there any standout article or topic from April I missed? Feel free to drop a comment or hit reply, even a quick line helps.
If you are already subscribed and enjoyed the article, please give it a like and/or share it others, really appreciate it 🙏
Keep learning
What the Data Crowd Was Reading in March 2026

It’s time for another data/AI roundup and here are the highlights from March 👇
𝐃𝐚𝐭𝐚 𝐒𝐜𝐢𝐞𝐧𝐜𝐞 & 𝐀𝐈
Why context engineering matters more than prompt hacks
Bayesian statistics in plain English
Why most agentic AI systems fail
The problem with treating context like tokens
A visual guide to modern attention variants
How GPT 5.4 improves Codex
𝐃𝐚𝐭𝐚 𝐄𝐧𝐠𝐢𝐧𝐞𝐞𝐫𝐢𝐧𝐠
Why modern data stacks are getting harder to understand
Why ETL is losing its central role
What makes a strong data engineering GitHub portfolio
Why AI builders need data engineering fundamentals
A beginner’s guide to database internals
Why refactoring beats rebuilding data models
Plus: what frontier AI job postings reveal about the market, Why data teams should start with the business model and Why strategy matters more than dashboards
What the Data Crowd Was Reading in February 2026

It’s time for another data/AI roundup and here are the highlights from February👇
𝐃𝐚𝐭𝐚 𝐒𝐜𝐢𝐞𝐧𝐜𝐞 & 𝐀𝐈
Inside OpenAI’s in-house data agent
A practical guide to which AI to use in the agentic era
Why judgment may not be uniquely human after all
How Codex is being used for serious research automation
Why semantic linking matters for giving data meaning
𝐃𝐚𝐭𝐚 𝐄𝐧𝐠𝐢𝐧𝐞𝐞𝐫𝐢𝐧𝐠
A portable analytics stack built on DuckDB, DuckLake, dlt and SQLMesh
Why healing tables beat slow-motion backfill disasters
The case for MetadataOps engineers
How to use AI tools without losing data engineering fundamentals
Why 5-second BigQuery queries can still be expensive
𝐃𝐚𝐭𝐚 𝐀𝐧𝐚𝐥𝐲𝐬𝐢𝐬 & 𝐁𝐈
The state of machine learning competitions in 2025
Plus: why AI is eating software’s TAM, what world models could unlock in robotics and why AI may intensify work instead of reducing it.
Thank you for the mention 😊