
What the Data Crowd Was Reading in May 2026
Tools, techniques and deep dives worth reading that I came across in May 2026.

Fellow Data Tinkerers
It’s time for another round-up on all things data and AI!
But before that, I wanted to share with you what you could unlock if you share Data Tinkerer with just 1 more person.
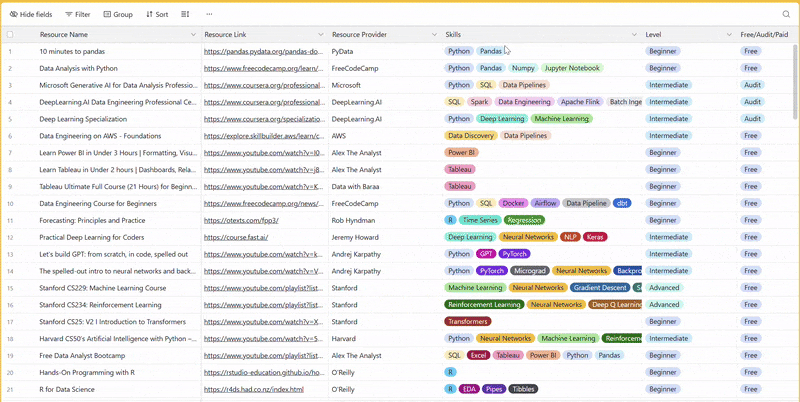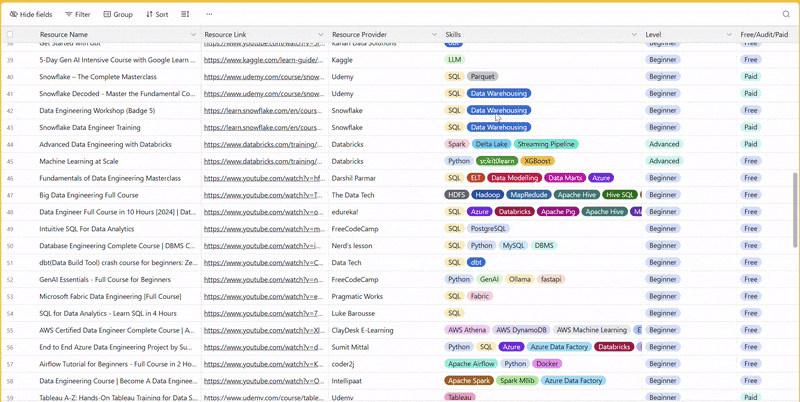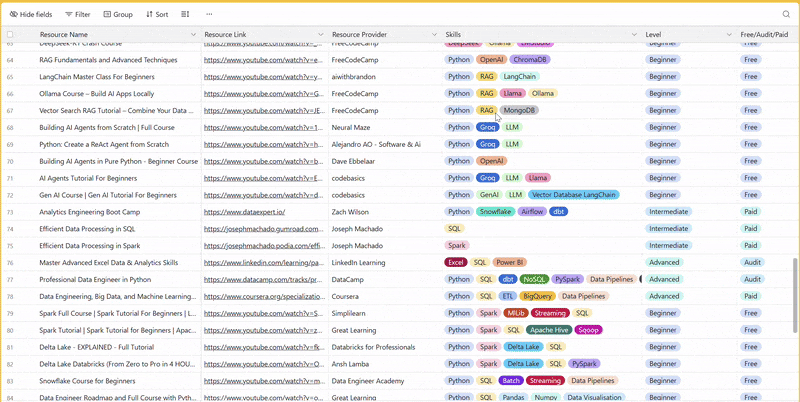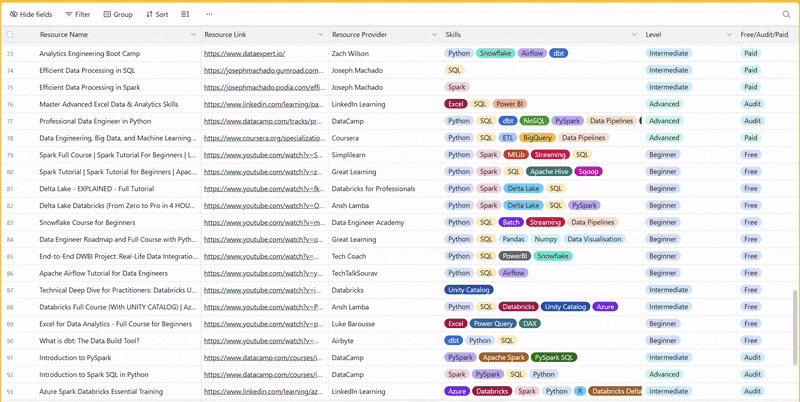
There are 100+ resources to learn all things data (science, engineering, analysis). It includes videos, courses, projects and can be filtered by tech stack (Python, SQL, Spark and etc), skill level (Beginner, Intermediate and so on) provider name or free/paid. So if you know other people who like staying up to date on all things data, please share Data Tinkerer with them!
Without further ado, let’s get to the round up for May!
Data science & AI
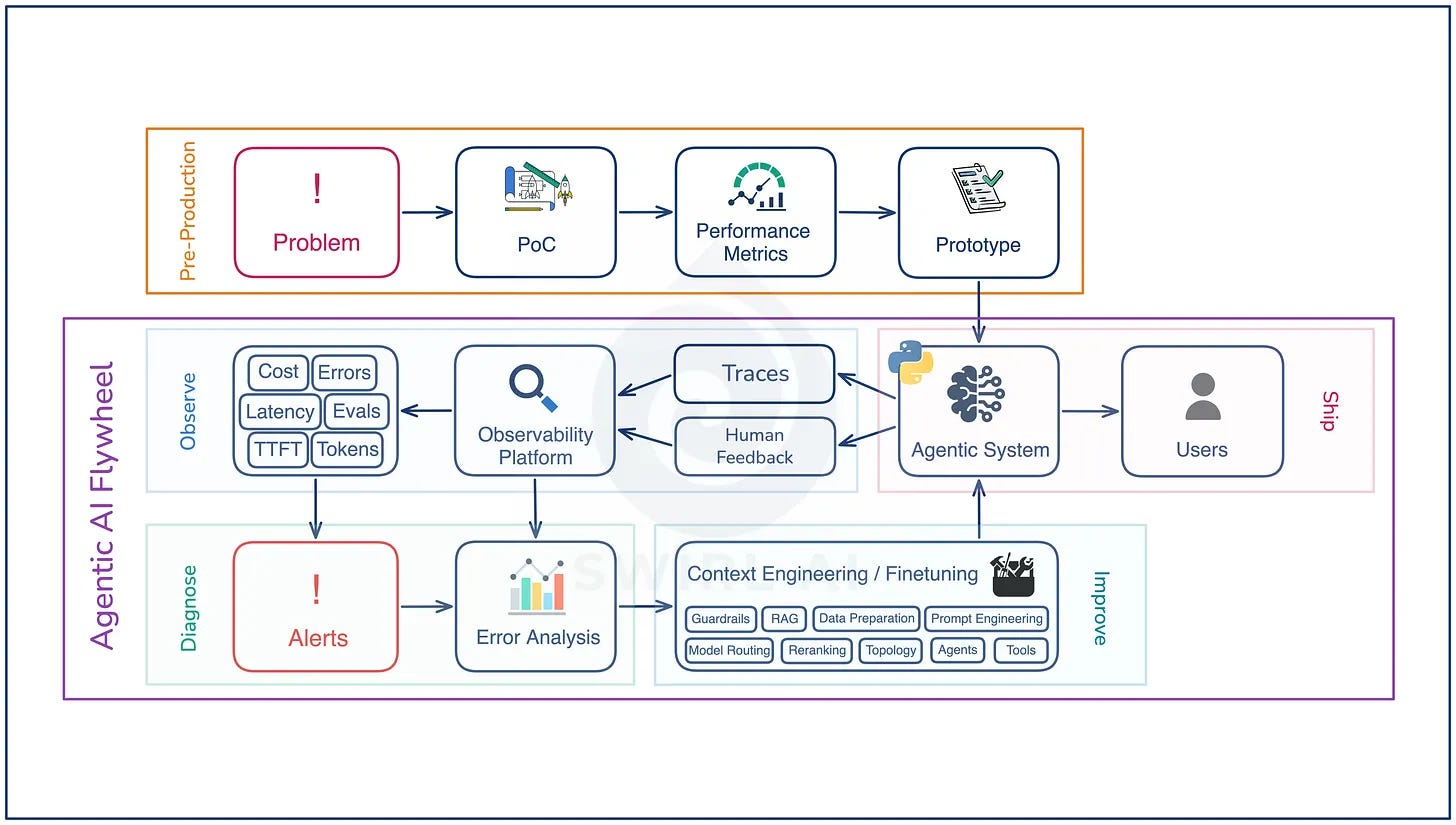
Agentic AI Flywheels (15 minute read)
Aurimas Griciūnas explains how production feedback, observability and evals create a flywheel that helps AI agents improve with every release.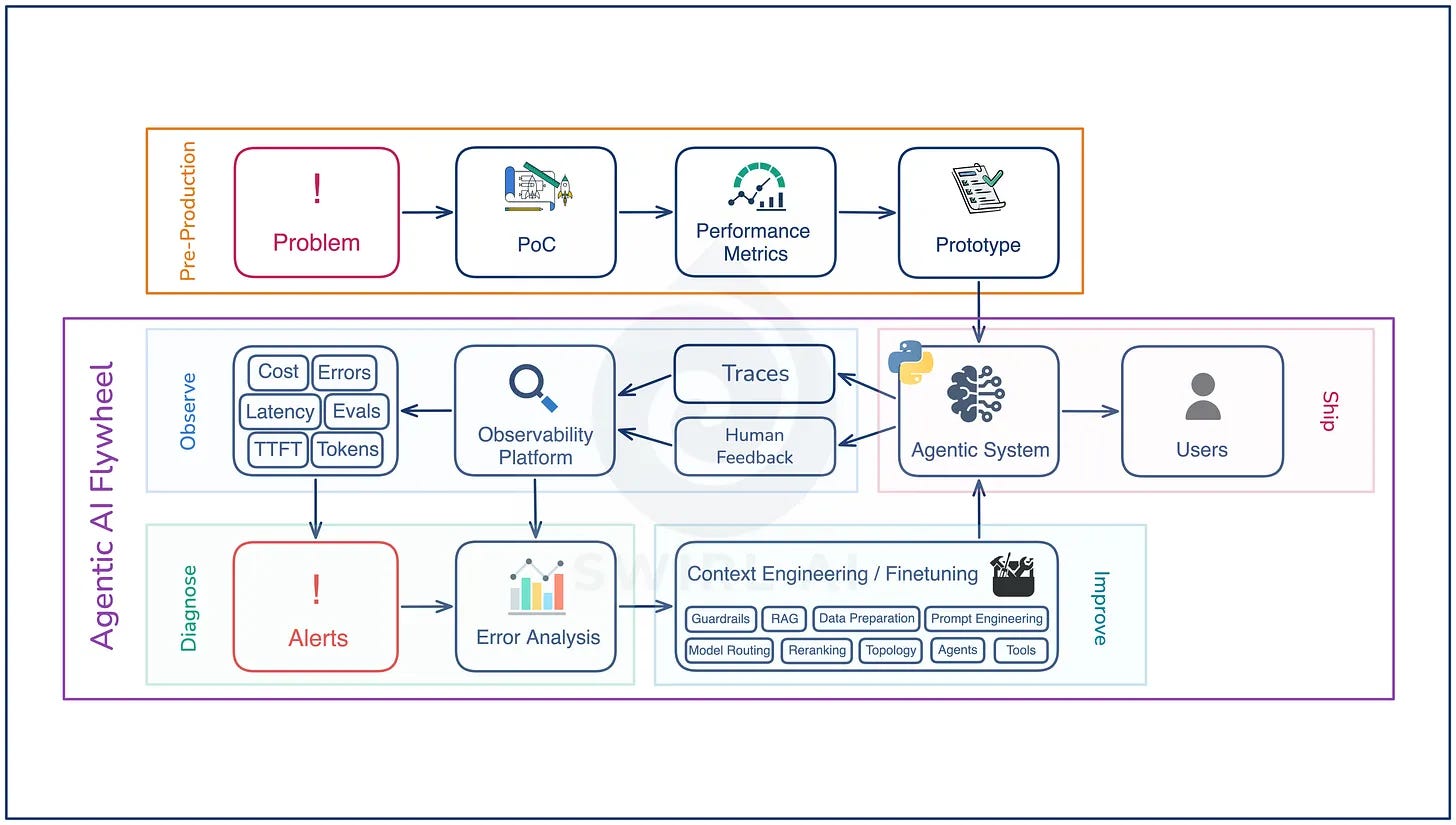
Choosing the Right Graph (36 minute read)
Detailed breakdown by Jessica Talisman, MLS comparing labeled property graphs and RDF knowledge graphs, offering a practical framework for choosing between them.How AI agent memory works (14 minute read)
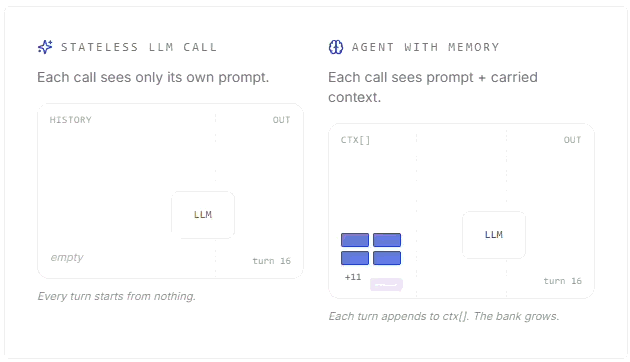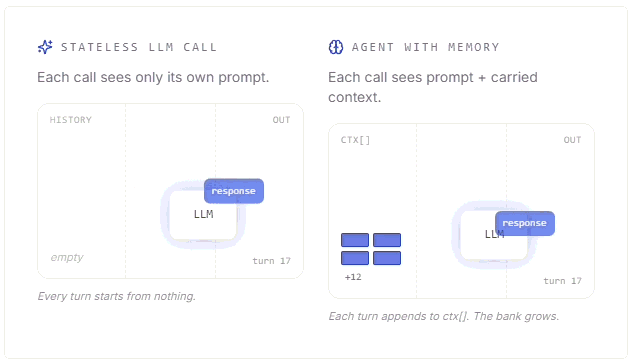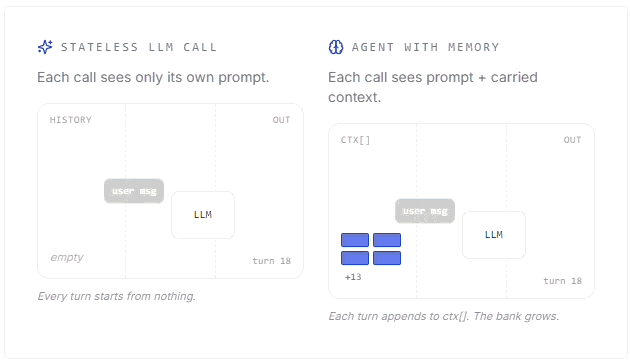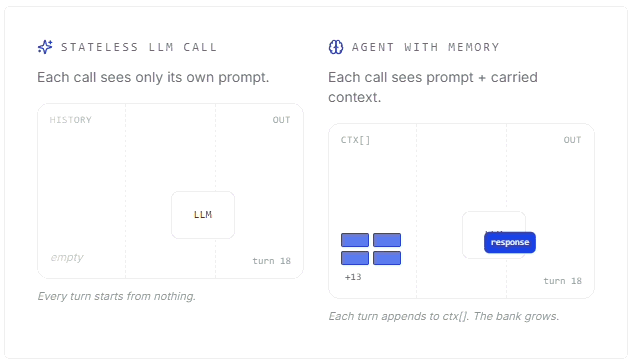
Mert Cobanov walks through how AI agents use context, embeddings, retrieval and memory stores to remember useful information across conversations.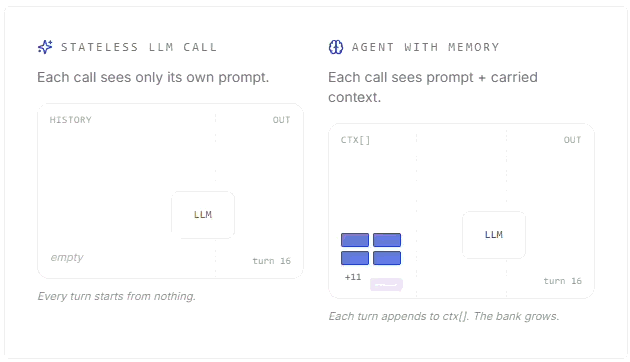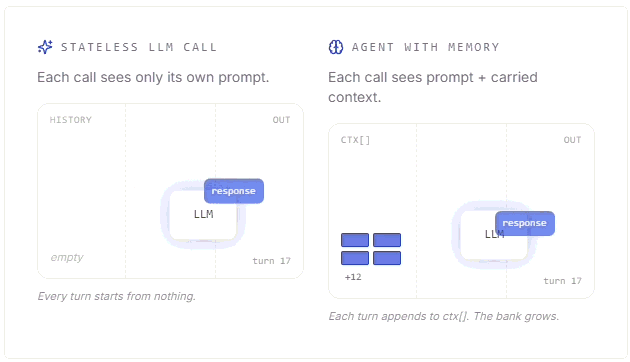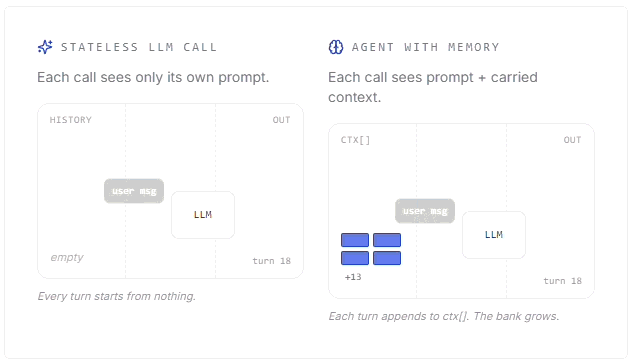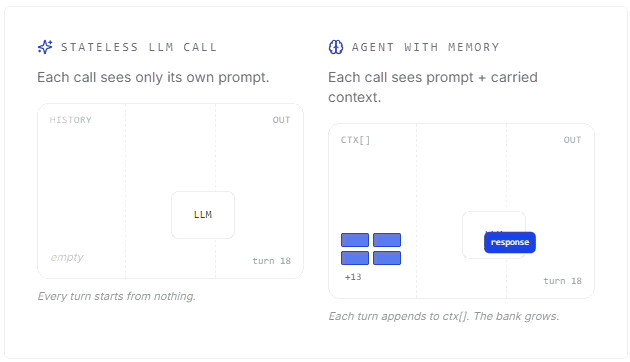
Building Your First Claude Skill (19 minute read)
Andres Vourakis shows how to build a Claude Skill that checks whether an analysis is correct, answers the right question and can be trusted before it reaches stakeholders.What political censorship looks like inside an LLM’s weights (45+ minute read)
This article finds that Qwen 3.5’s political censorship is a small, identifiable circuit layered over facts the model already knows.Agent Evaluation: A Detailed Guide (60+ minute read)
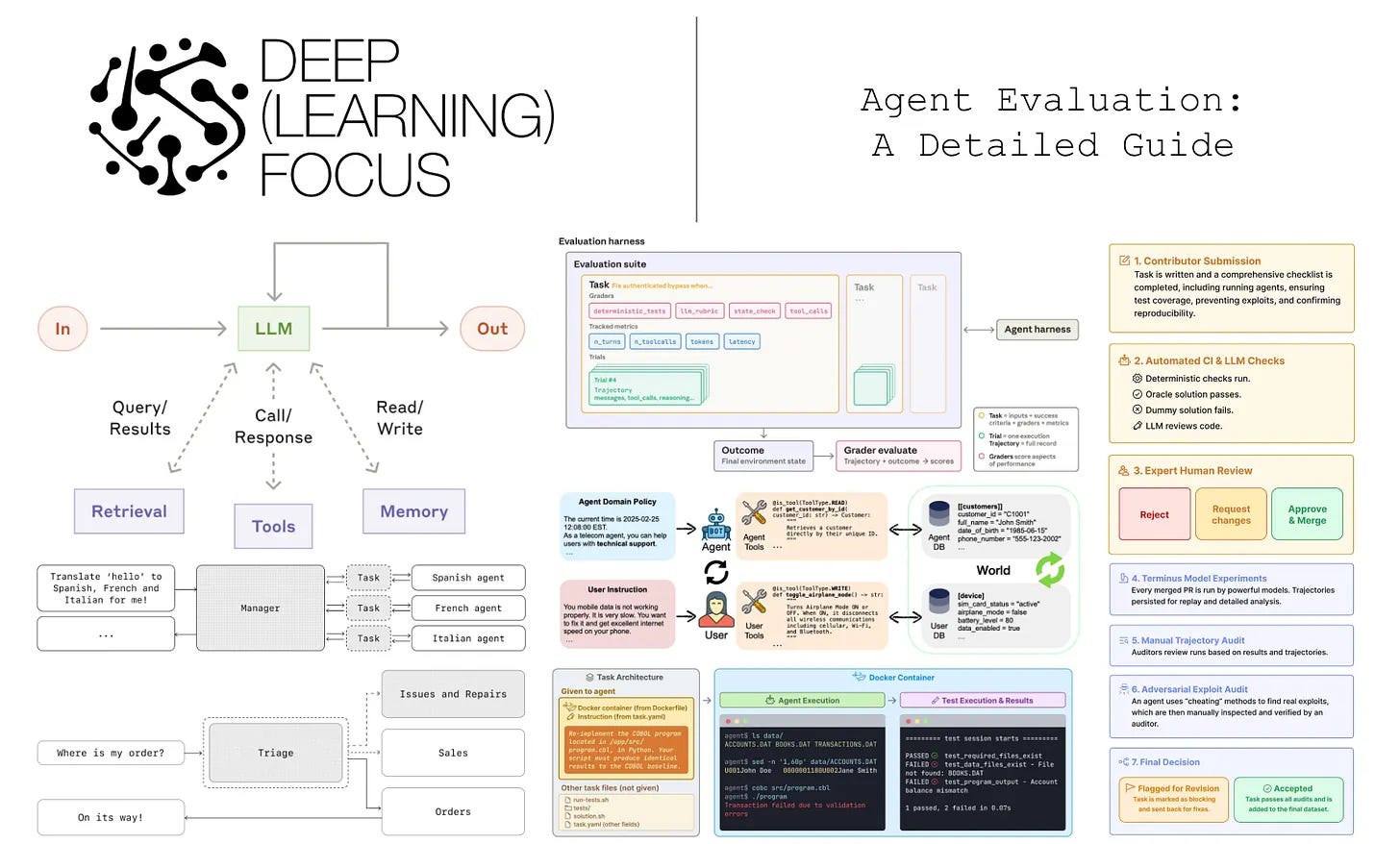
Cameron R. Wolfe, Ph.D. explains how to evaluate AI agents using realistic tasks, outcome-based metrics and detailed analysis of their tool use and decision paths.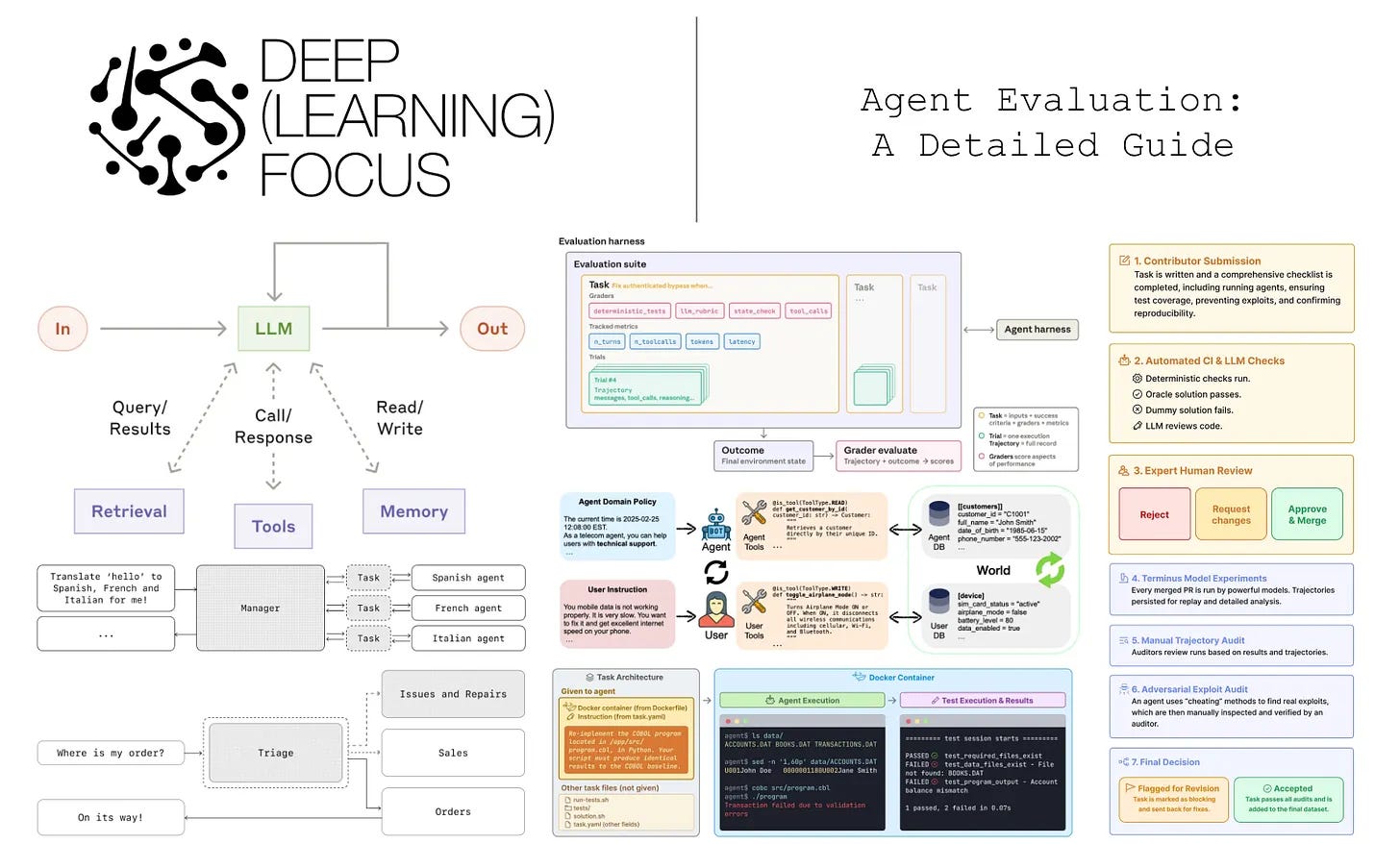
Is logistic regression regression? (6 minute read)
Richard Vale explains why logistic regression is genuinely regression because it predicts a probability, only becoming classification once a cutoff is applied.What Matters in Production RAG (13 minute read)
Arpit Bhayani explains how production RAG depends on thoughtful chunking, reliable index updates and retrieval tracing that shows why the system returned a particular answer.How Lyft Uses AI to Scale Translation Across 150+ Products (18 minute read)
This article walks through how Lyft used an LLM drafting and evaluation loop to cut translation times from days to minutes across 150+ services.
Data engineering
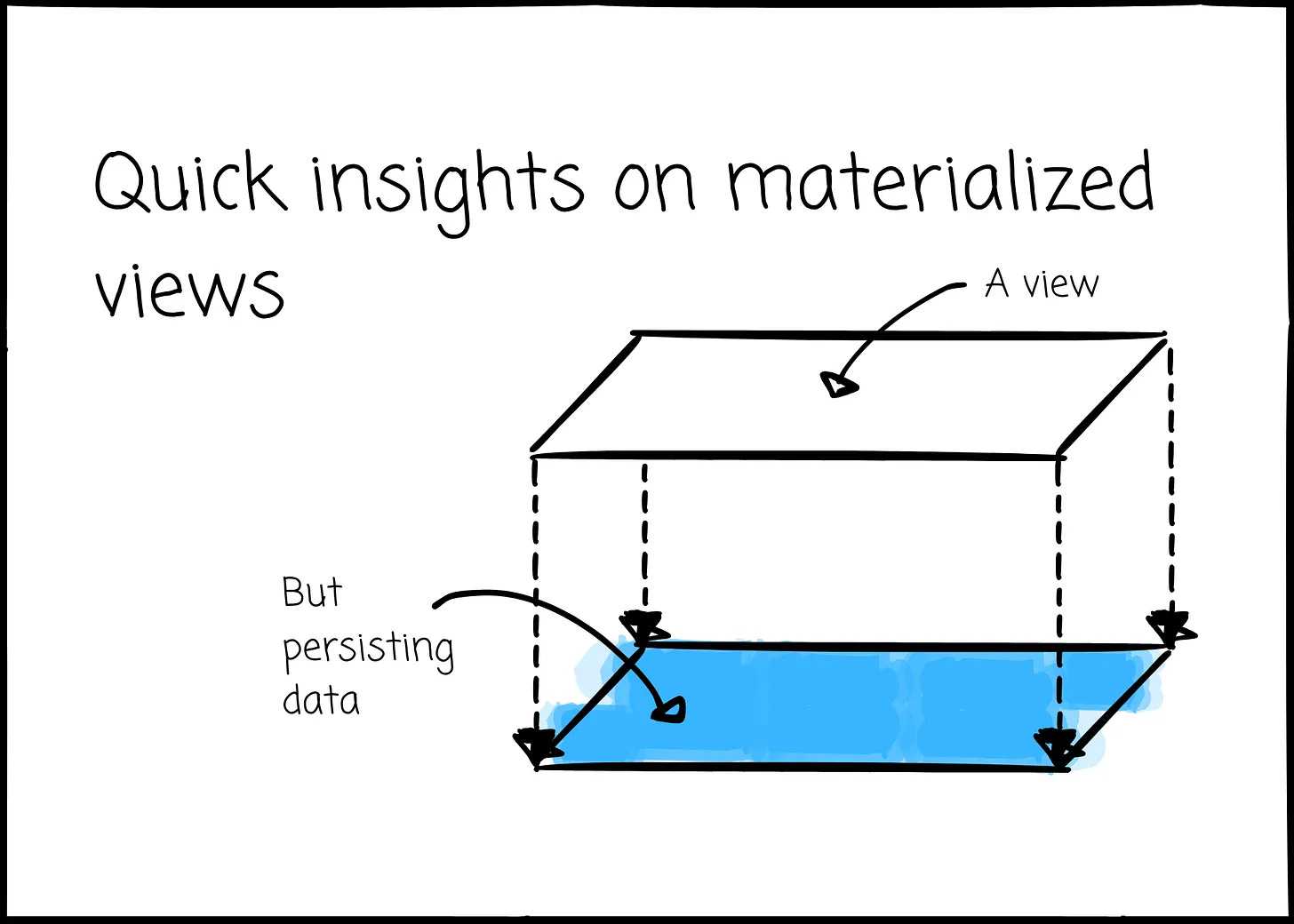
Quick insights on materialized views (11 minute read)
Vu Trinh explains how materialized views speed up queries, how incremental refresh keeps them current and when they make sense for real-time processing.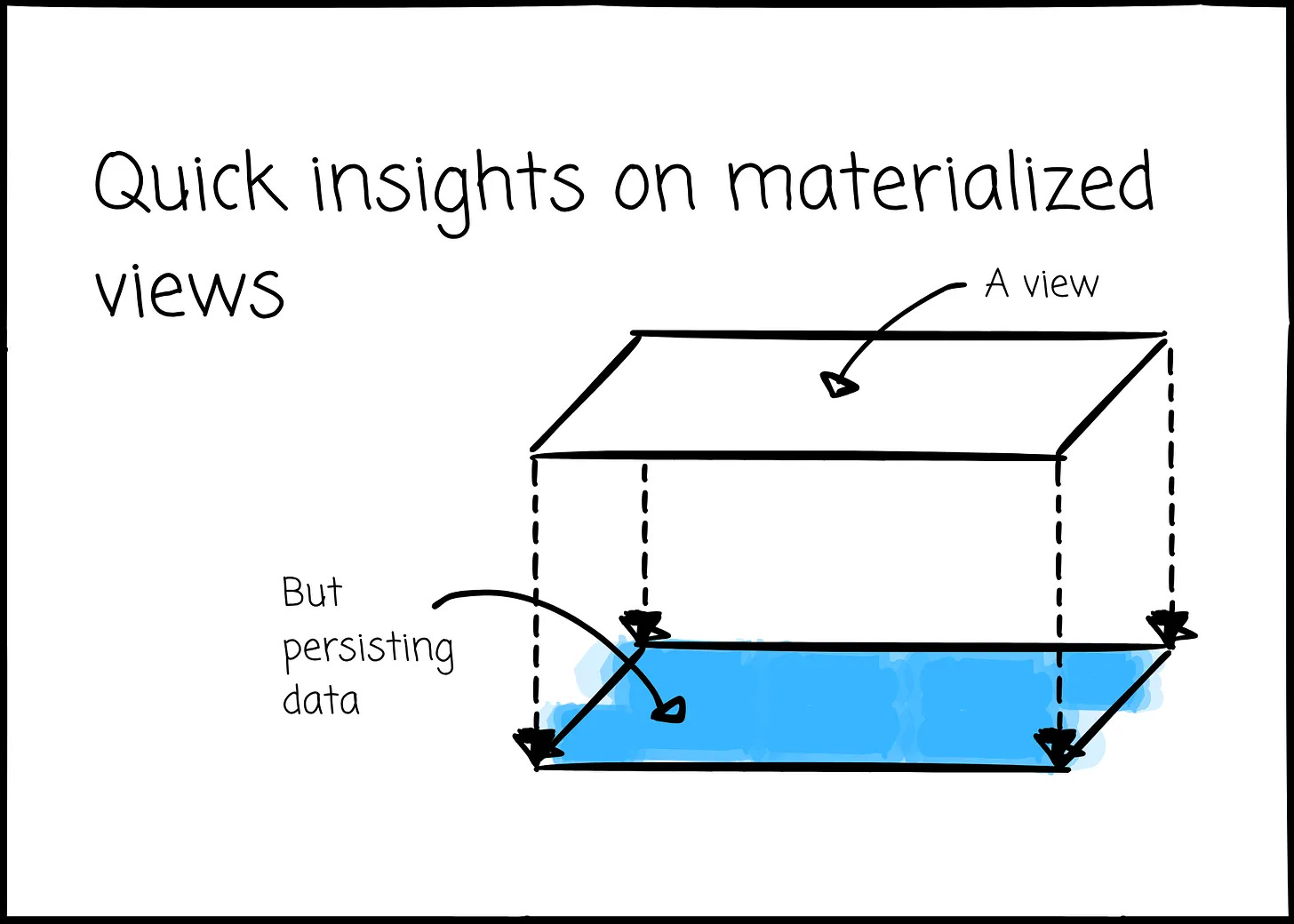
Five Worlds of Data Engineering (12 minute read)
Chris hillman explains why data engineering advice often clashes because teams operate across five very different worlds, each with its own tools, constraints and priorities.Why I Set Up Databricks and Then Walked Away From It (17 minute read)
Erfan Hesami walks through why he dropped Databricks for a simpler open-source stack that better matched his company’s data scale, budget and team maturity.Does ELT vs. ETL Even Still Matter? (9 minute read)
SeattleDataGuy argues that ETL versus ELT matters far less than building reliable, affordable pipelines that help the business make better decisions.Complete End-To-End Build of ETL Pipeline in AWS (12 minute read)
Matt Martin walks through building ETL with DuckDB and ECS Fargate on AWS for under 50 cents.
The Cognitive Overload of AI Development (7 minute read)
Interesting article by Daniel Beach on how AI coding has turned senior engineers into exhausted code reviewers, forever one giant AI-generated pull request away from chicken farming.Event-Driven vs. Polling Architectures for Agent Triggers (17 minute read)
Michel Tricot explains why production agent triggers need a mix of events, reconciliation polling, idempotency and durable runtimes rather than relying on webhooks alone.Progressive Disclosure: The Core Pattern for Analytics Agents (10 minute read)
Alejandro Aboy explains why analytics agents should load only the schema and business context they need, when they need it, to reduce confusion and hallucinated queries.Strong views on PostgreSQL VIEWs (24 minute read)
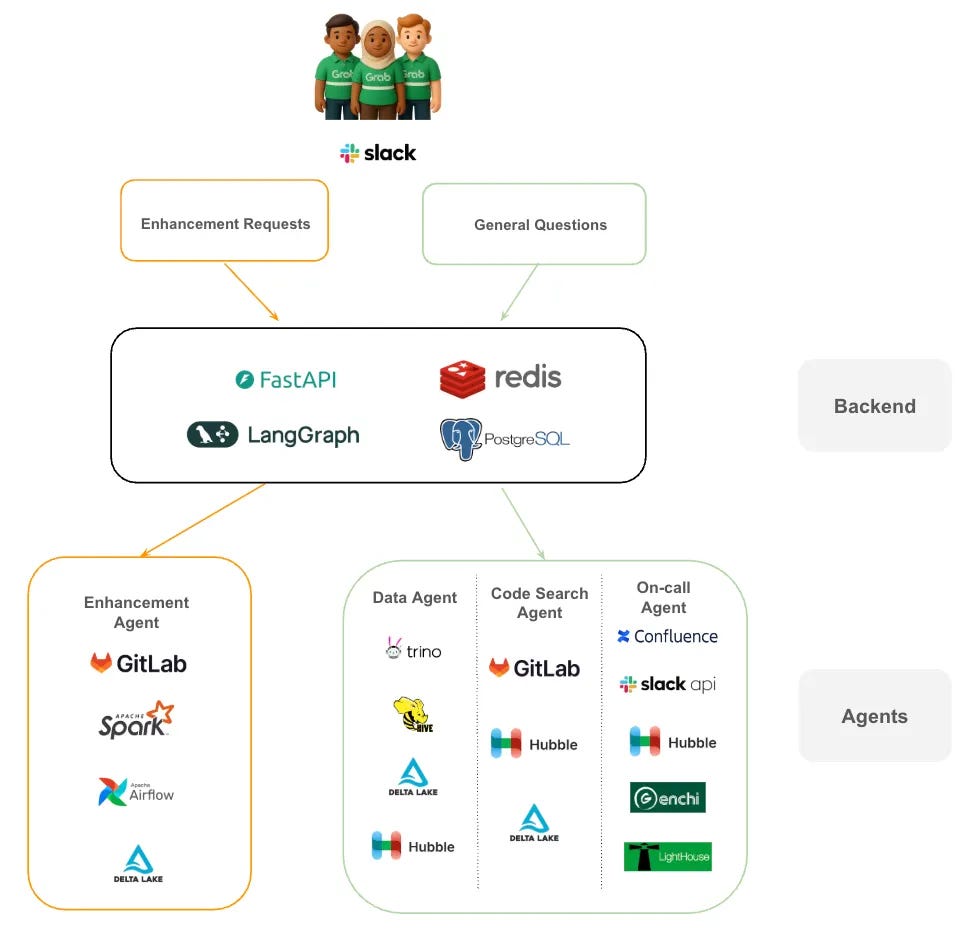
Radim Marek explains why PostgreSQL views remain useful abstractions, but hidden dependencies, rigid schemas and complex migrations make them easy to misuse.How Grab Reclaimed Hundreds of Data Engineering Hours With Multi-Agent AI (17 minute read)
This article explains how Grab used specialist AI agents to cut repetitive data support from hours to minutes and return hundreds of engineering hours to roadmap work.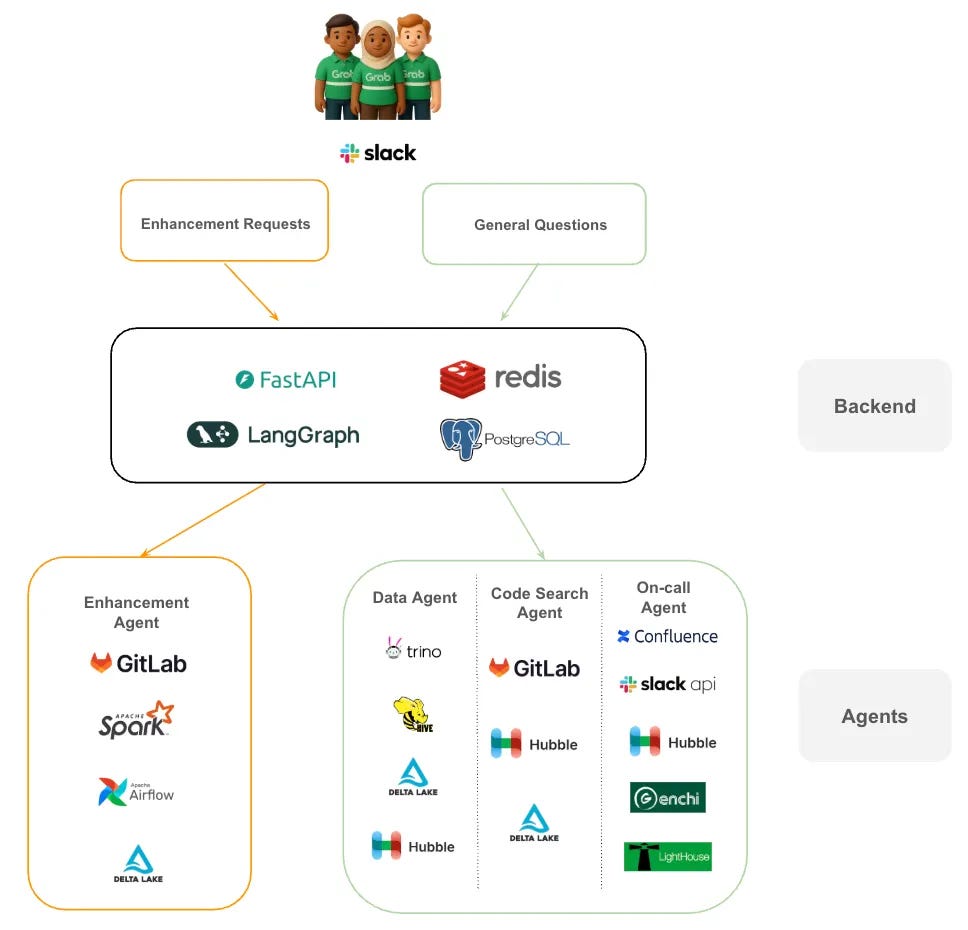
Data analysis and visualisation
Of Hammers and Nails: What AI Can and Cannot Do for a Data Analyst (5 minute read)
Adam Cassar argues that AI makes analysts faster at coding and drafting, but still struggles with the judgement, context and consistency needed for reliable analysis.Dead on Arrival: The AI Dashboard Problem (17 minute read)
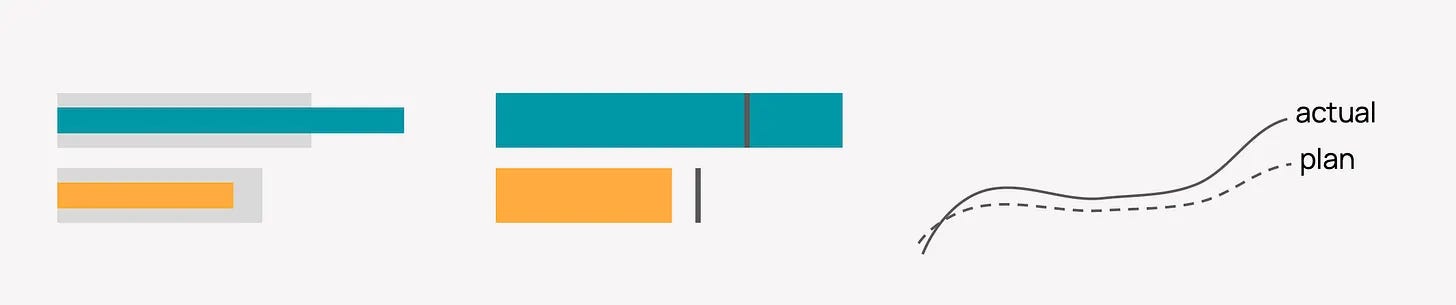
Darragh Murray argues that AI can build polished dashboards in minutes, but good analysis, domain knowledge and human judgement still decide whether anyone should trust them.How to Visualize Plan vs Actual (6 minute read)
Anastasiya Kuznetsova explains how to make plan-versus-actual gaps obvious through distinct visual styles, selective color and the right choice of bars or lines.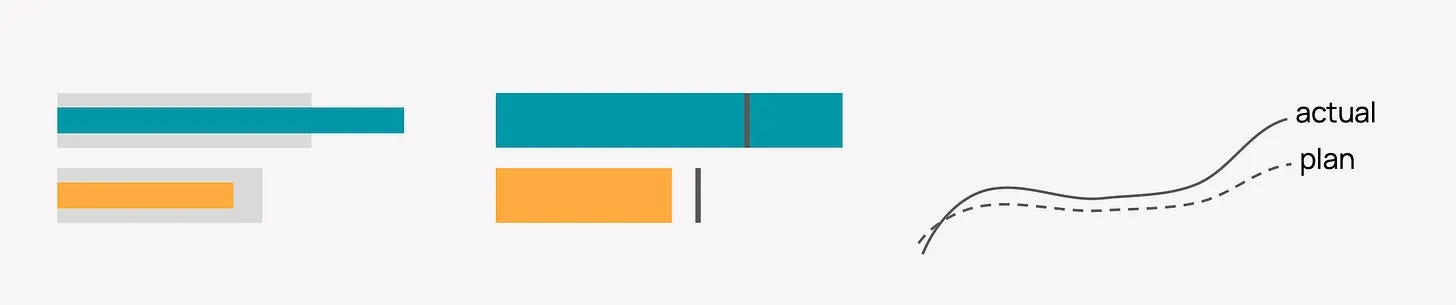
Other interesting reads
Cloudflare And Meta Just Told You Which Jobs Get Cut Next (12 minute read)
Vin Vashishta argues that AI-driven layoffs will move from reporting roles to coordination roles and finally anyone whose work cannot be tied to measurable business value.Notes from inside China’s AI labs (18 minute read)
Nathan Lambert shares what he learned inside China’s leading AI labs, from their fast-moving research culture and open-model mindset to their hunger for more compute.The economics of superstar AI researchers (10 minute read)
Interesting article looking at how small differences in research ability can lead to enormous pay gaps when one researcher’s work reaches billions of users and cannot be replicated by simply hiring more people.
Quick favor - need your take
Was there any standout article or topic from May I missed? Feel free to drop a comment or hit reply, even a quick line helps.
If you are already subscribed and enjoyed the article, please give it a like and/or share it others, really appreciate it 🙏
Keep learning
What the Data Crowd Was Reading in April 2026

It’s time for another data/AI roundup and here are the highlights from April👇
𝐃𝐚𝐭𝐚 𝐒𝐜𝐢𝐞𝐧𝐜𝐞 & 𝐀𝐈
The six core components of coding agents
Why data science is making a comeback in the LLM era
Machine learning explained visually from first principles
Five multi-agent coordination patterns and when to use them
𝐃𝐚𝐭𝐚 𝐄𝐧𝐠𝐢𝐧𝐞𝐞𝐫𝐢𝐧𝐠
The boring foundations of good data platform architecture
Data observability fundamentals for trustworthy pipelines
Why platform decisions should start with use cases, not tools
Defensive database patterns for agentic AI
𝐃𝐚𝐭𝐚 𝐀𝐧𝐚𝐥𝐲𝐬𝐢𝐬 & 𝐁𝐈
Why the data role is being reborn
A better way to colour retention tables
Why dashboard rot is really organisational rot
Plus: why AI may be more like electricity than dot-com, why compute still matters for catching frontier labs and how spreadsheets reshaped business into a numbers-first machine.
What the Data Crowd Was Reading in March 2026

It’s time for another data/AI roundup and here are the highlights from March 👇
𝐃𝐚𝐭𝐚 𝐒𝐜𝐢𝐞𝐧𝐜𝐞 & 𝐀𝐈
Why context engineering matters more than prompt hacks
Bayesian statistics in plain English
Why most agentic AI systems fail
The problem with treating context like tokens
A visual guide to modern attention variants
How GPT 5.4 improves Codex
𝐃𝐚𝐭𝐚 𝐄𝐧𝐠𝐢𝐧𝐞𝐞𝐫𝐢𝐧𝐠
Why modern data stacks are getting harder to understand
Why ETL is losing its central role
What makes a strong data engineering GitHub portfolio
Why AI builders need data engineering fundamentals
A beginner’s guide to database internals
Why refactoring beats rebuilding data models
Plus: what frontier AI job postings reveal about the market, Why data teams should start with the business model and Why strategy matters more than dashboards
Thanks for sharing man! Amazing work as always with the curation 😎